앙상블
내가 훈련 시킨 모델이 있다면, 다른 모델들과 결과값을 합쳐서 더 좋은 결과값을 내는것은 어떨까? 하는 생각들을 한 번씩은 해봤을 것입니다.
이것을 가능케 하는 방법론이 앙상블(Ensemble)이고 크게 배깅(Bagging), 부스팅(boosting), 스태킹(stacking), 보팅(voting) 네 가지 방법이 있습니다.

이 글에서는 배깅과 부스팅 방법에 대해 이론적으로 설명하고, 어떤 방법이 내 과제에 더 적합한지에 대한 인사이트를 나에게 주기 위해 작성했습니다.
배깅, Bagging
Bootstrap Aggregation의 줄임말 입니다.
우선 배깅의 사전적 의미부터 보겠습니다.
Bagging은 Bootstrap Aggregating의 줄임말로, 데이터 셋을 여러 서브셋으로 무작위로 나누고 각각의 서브셋에 동일한 알고리즘을 적용하여 개별 모델을 만드는 방법입니다.
각 모델은 독립적으로 예측을 수행하며, 그 결과는 보통 평균화 또는 다수결 투표를 통해 결합됩니다. 배깅은 주로 과적합(overfitting)을 피하고 일반화 성능을 향상시키는 데 사용됩니다.
그러니, 결론적으로 배깅이라는 방법은 - 데이터셋을 여러개로 나눠서 똑같은 모델을 적용해, 각 결과값들을 평균화 혹은 투표를 통해 decision을 하는 알고리즘으로 이해할 수 있겠습니다.
대표적인 알고리즘에 대해서 조금 더 살펴보겠습니다.
배깅에서 가장 흔하게 쓰이는 모델은 아무래도 트리(tree)계열의 모델들입니다. 애초에 앙상블 방법이 여러 트리 모델들을 융합하는 방법이라는 정의도 있습니다.
트리 모델 중에서도 가장 대표적이고 간단한 decision tree와 random forest에 대해 간략하게만 설명하겠습니다.
결정 나무, Decision Tree
사실 decision tree에도 정말 많은 개념과 수식이 있지만, 이 글의 범위를 벗어나니 핵심 개념만 보겠습니다.
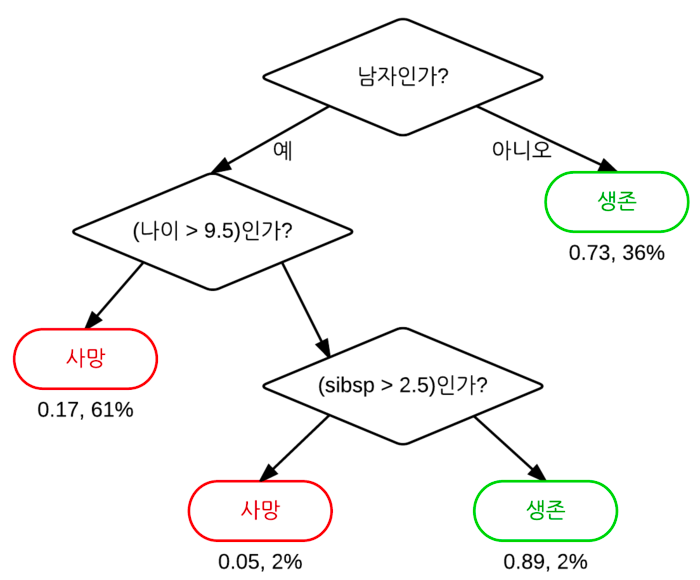
가장 핵심적인 개념은
decision tree는 특정 기준(질문)에 따라 데이터를 구분해서 확률 값을 반환하는 지도 학습 모델입니다.
우리가 흔히 알고 있는 트리 구조의 자료 구조로 생각할 수 있고, 한 분기(질문)마다 2개의 분기, 자식 노드로 갈라집니다.
제일 상단에 있는 노드는 결과에 가장 큰 영향을 끼치는 질문으로 Root node, 중간 노드들은 intermediate node, 맨 끝 단의 노드들은 leaf node라고 합니다.
그리고 leaf node의 복잡도(entrophy)가 가능한 낮도록 만드는 것입니다.
확률이나 복잡도를 구하는 법, 가지 치기 등 자세한 내용은 사진 출처의 블로그를 참고하시면 도움이 될 것 같습니다.
배깅에 적용하는 법을 다시 정리하자면, 데이터셋을 여러 subset으로 나누고 여러개의 decision tree에 추론을 각각 따로 하고, 합치는 것이라고 보면 되겠습니다.
랜덤 포레스트, Random Forest
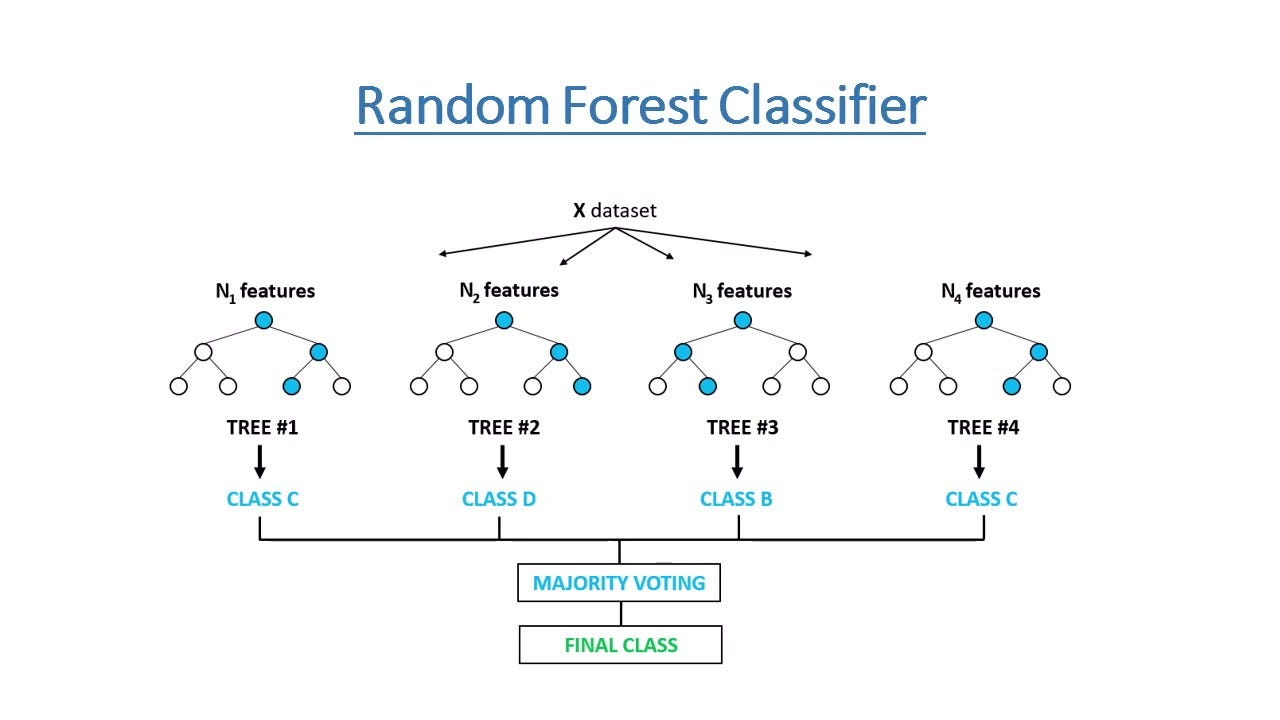
결정 나무와 크게 다르지 않지만 좀 더 강력한 성능을 보이는 랜덤 포레스트에 대해 설명하겠습니다.
결정 나무에서는 모든 특징 값들을 가지고 노드들을 split 했었습니다.
랜덤 포레스트에서는 모든 특징 값을 가지고 나무 모델을 키우는 것이 아니라 이 특징 값 마저도 랜덤하게 선택해서 나무를 키웁니다.
이렇게 랜덤한 특징 값으로 키워진 트리 모델을 랜덤 트리라고 하고 많은 랜덤 트리들을 모으면 랜덤 포레스트가 됩니다.
위 사진처럼 여러 개의 랜덤 트리의 분류 혹은 회귀 값을 종합(aggregation) 하면 랜덤 포레스트의 결과값이 되는 것입니다.
여기서 배깅을 적용하면 여러 랜덤 포레스트의 값을 다시 종합하는, 종합의 종합 모델이 됩니다.
부스팅, Boosting
사실 이 글을 쓰는 이유이기도 한 부스팅 방법도 설명하겠습니다.
사전적 의미부터 살펴보겠습니다.
부스팅은 약한 모델들을 순차적으로 학습시켜 강한 모델을 만드는 방법입니다.
각 순서에서, 이전 모델에서 잘못 예측된 데이터에 대한 가중치를 높여 다음 모델이 해당 데이터를 더 잘 예측하도록 합니다. 최종적으로, 모든 모델이 가중치 투표를 통해 예측을 결합합니다.
즉, 여러개의 분류기를 사용하는 것은 배깅과 같지만, 여러 개의 분류기 (약한 분류기)들을 순차적으로 분류하게 한 후 분류기가 틀린 부분은 가중치를 부여해서 다음 분류기로 넘겨줍니다.
약한 분류기는 모여서 강한 분류기가 됩니다.
왜 부스팅이란 이름이 붙었는지 짐작이 가는 정의입니다.
다른 특이사항으로는 부스팅에서는 트리 형태가 아닌 스텀프(stump)형태 이다. (위에 사진 참고, 왼쪽은 트리 계열, 오른쪽은 부스팅)
이 스텀프는 한 개의 질문으로 2개의 리프 노드로 분류해야 하는 약한 분류기이다.
부스팅의 대표적인 2가지 방법인 AdaBoost와 Gradient Boost를 설명해 보겠습니다.
AdaBoost
Adaptive Boost라고도 불리는 부스팅 기법입니다.
 사진 출처 - StatQuest
사진 출처 - StatQuest
여러 개의 분류기에 가중치를 주되, 그 가중치는 다르게 가중됩니다.
어떤 피처는 다른 피처보다 중요도가 당연히 다를테니 이렇게 가중치를 주는것이 합당해 보입니다.
예를 들어, 사람 목소리를 듣고 나이를 구하는 문제라고 했을 때, 화자의 나이가 목소리의 높낮이 피처 보다 당연히 중요한 피처가 될 것입니다.
모델의 학습을 통해 중요한 피처(질문, 스텀프)를 찾아내고 서로 다른 가중치를 적용하고 모든 가중치를 갖고가는 기법으로 정리할 수 있겠습니다.
Gradient Boost
Gradient Boosting 또한 순차적으로 학습이 진행되는 점에서 AdaBoost와 비슷한 면이 있지만, 매 학습 단계에서 학습률을 사용해 가중치(예측값)을 업데이트 하면서 정답에 한 단계식 다가가는 방법입니다.
조금 더 구조적으로 살펴보겠습니다.
Gradient boosting(이하 GB)에서는 이전 기법과는 다른 방법으로 정답값을 추론합니다.
Boosting에서는 트리(약한 분류기)를 사용해서 추론했고, AdaBoost에서는 각 스텀프에 다른 가중치를 부여해 추론했습니다.
GB에서는 트리도 스텀프도 아닌 리프 노드(leaf node)의 값을 사용해 추론을 합니다.
위에 사진을 예시를 들었을 때,
사람들의 여러 특징들(root and intermediate node)가 있고, 이를 기반으로 몸무게(leaf node)를 예측하는 모델을 만드는 문제라고 하겠습니다.
여기서 여러 몸무게가 주어졌을 때, (예를 들어, 88, 74, 57, 66,...,n) 이에 대한 평균이 사진처럼 71.2라고 했을 때, 이 평균 값을 리프 노드에 빼줍니다. (88, 74, 57, 66,...,n 에 각각 평균 값을 빼준다.)
그렇게 평균값을 빼서 나온 값은 pseudo residual, 유사 잔차 값이 됩니다.
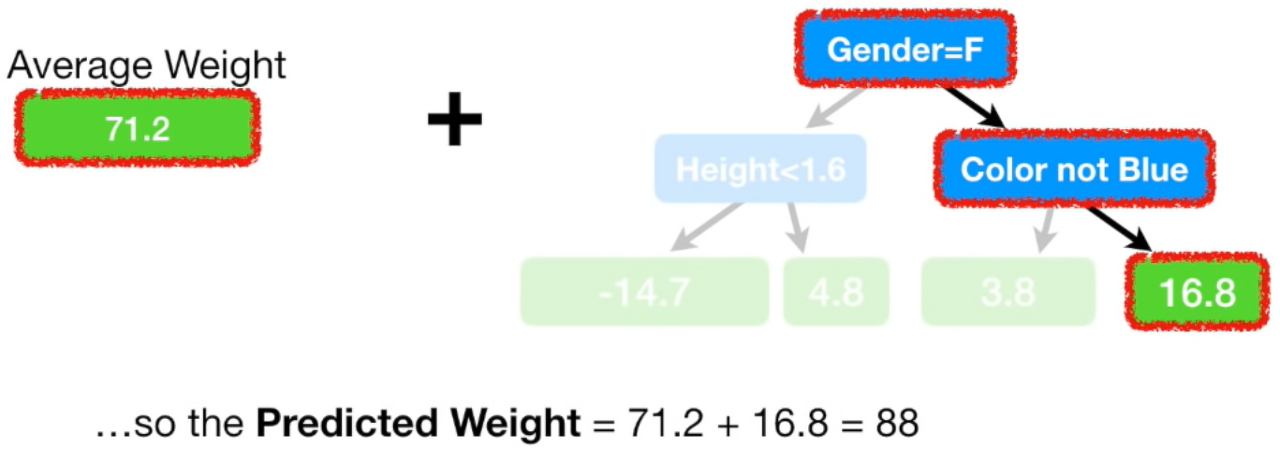
피처 별로 트리 모델을 만들어 결과값들은 분리하고 리프 노드에 평균 값을 더해주면 해당 피처에 대한 예측값이 당연히 나옵니다.
하지만 우리가 원하는건 새로운 데이터 들어왔을 때 대응할 수 있는 모델이다. 위에 방법은 해당 데이터에만 예측을 하는 과적합 상태입니다.
그렇게 학습률, learning rate를 넣어 학습을 하는 것입니다.
그렇게 하면 모든 리프 노드에 대한 잔차 값이 learning rate 만큼만 줄어들게 되고, 학습 데이터가 많아진다면 범용적인 모델로 사용될 수 있는것 입니다.
여기까지가 기본적인 GB 개념에 대한 설명이고 이를 발전시켜 더욱 강력한 모델이 개발되었는데 대표적으로 XGBoost (eXtreme Gradient Boost), LightBoost가 있습니다.
큰 개념은 같지만 추가적인 기술을 도입해, GB보다 성능과 속도를 향상시킨 모델들입니다.
ref
- decision tree
- boosting
- bagging
- Boosting 2 귀퉁이 서재님께서 부스팅 기법을 너무 잘 정리해 주셨습니다.
이 글의 출처는 대부분 chatGPT에게 질의해서 얻은 관련 웹사이트 자료를 정리해 놓은 것입니다.
다음 글에서는 지금 제 과제에 적합하다고 판단되는 LightBoost 구현해보고, 실제 사용 경험을 공유하겠습니다.
