완성 화면
데이터 분석 과정
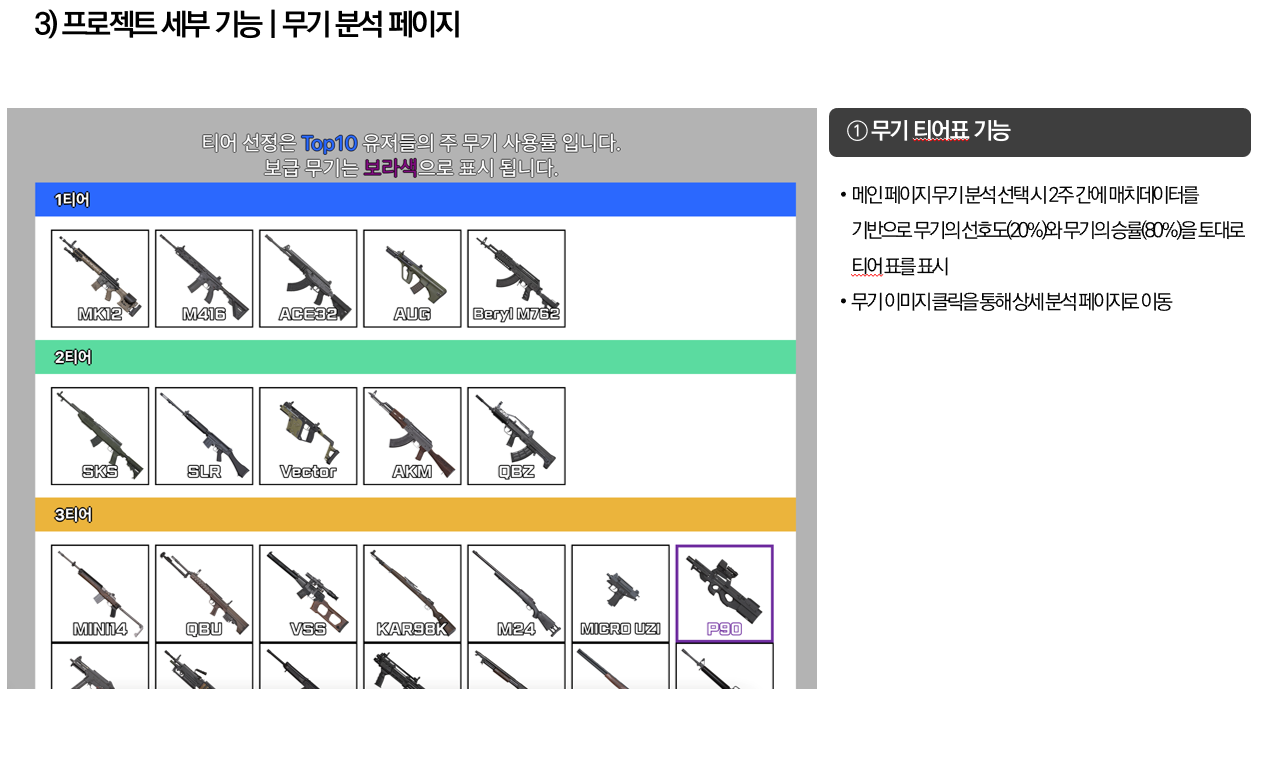
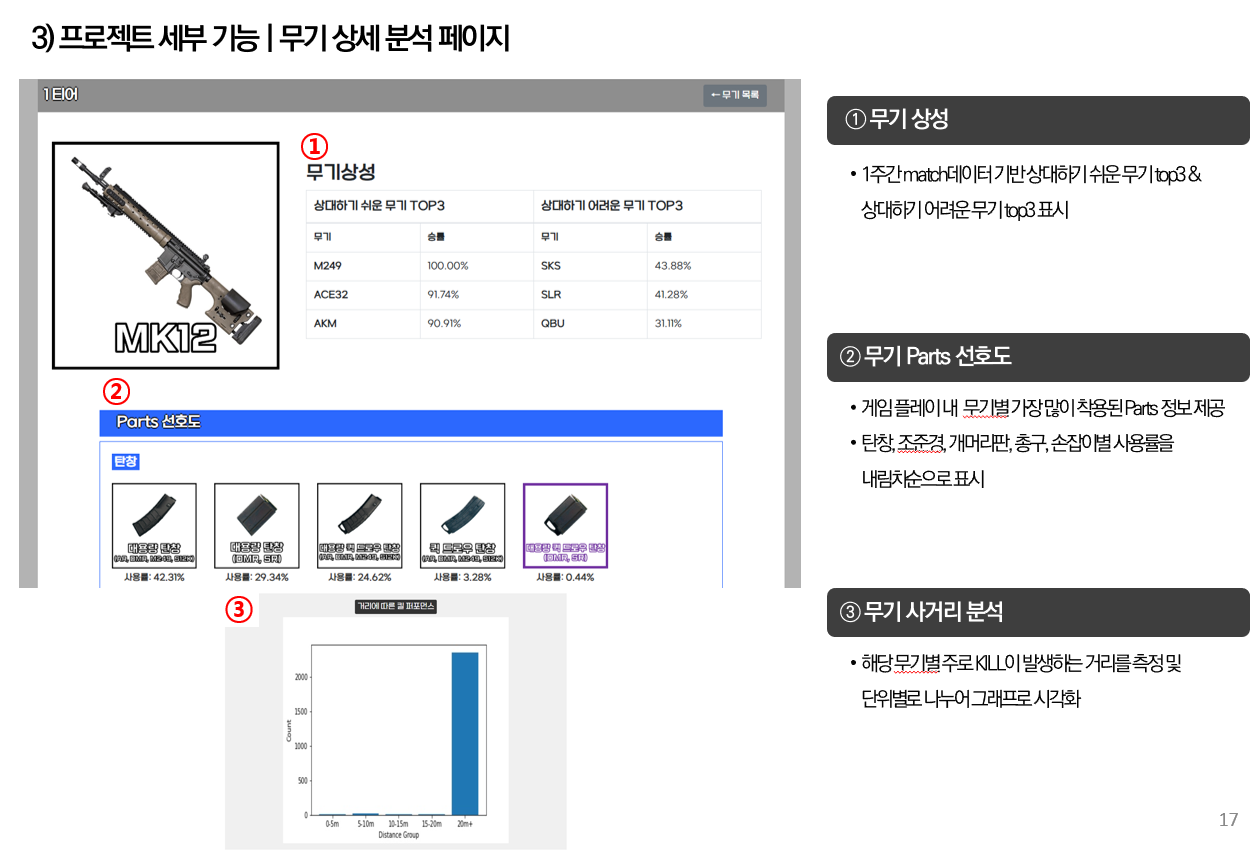
무기 상성과 무기 티어표
1. 무기 상성
개인전의 경우 killer_weapon과 finisher_weapon이 같아 문제가 없었지만, 다인전(듀오나 스쿼드) 의 경우 교전한 데이터인 killer_weapon과 마지막 한발만을 친(막타) finsiher_weapon에 차이가 있었다.
게임 내에서 교전 시에 승률을 알고 싶었기 때문에 마지막에 쏜 것이 아닌 교전을 하며 싸운 killer_weapon을 사용하고자 했다.
교전에 사용된 주무기들을 추출하여 교전 횟수가 일정 횟수 이상인 데이터만을 찾아 상대적 승률을 나타내고자 했다.
AI유저의 데이터는 반영하지 않았고, 동일 무기에 대해서도 반영하지 않았다.
주무기 만의 교전 결과만을 반영하였다.
# 전체 대상 무기 추출
target = result_df['killer_weapon'].unique()
result = {}
for weapon in target:
# 필터링: total_count가 20 이상인 데이터만 선택합니다.
filtered_df = result_df[(result_df['killer_weapon'] == weapon) & (result_df['total_count'] >= 20)].sort_values('win_rate', ascending=False)
high_weapons = filtered_df.iloc[:3] if filtered_df.shape[0] >= 3 else filtered_df
low_weapons = filtered_df.iloc[-3:] if filtered_df.shape[0] >= 3 else filtered_df
result[weapon] = {
"highs": high_weapons,
"lows": low_weapons,
}
result_list = []
for weapon in result.keys():
result_list.append({
"weapon_name": weapon,
**{f"easy_weapon_{i+1}": row["victim_weapon"] if row["victim_weapon"] else None for i, row in result[weapon]["highs"].reset_index(drop=True).iterrows()},
**{f"easy_percent_{i+1}": row["win_rate"] if row["win_rate"] else None for i, row in result[weapon]["highs"].reset_index(drop=True).iterrows()},
**{f"hard_weapon_{i+1}": row["victim_weapon"] if row["victim_weapon"] else None for i, row in result[weapon]["lows"].reset_index(drop=True).iterrows()},
**{f"hard_percent_{i+1}": row["win_rate"] if row["win_rate"] else None for i, row in result[weapon]["lows"].reset_index(drop=True).iterrows()},
})
final_df = pd.DataFrame(result_list)
final_df = final_df.fillna(0)
- 이 코드를 실행하여 적용하여 보니 문제가 생겼다. 슬라이싱을 활용해 승률로만 정리하다보니 교전한 무기가 3개 미만인 경우에 상대하기 어려운 무기와 쉬운 무기에 똑같은 무기가 들어가는 경우가 발생했다.


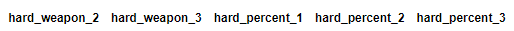

수정된 코드
코드를 승률 50퍼 기준으로 아예 다르게 변수에 저장하였다.
# 전체 경기 수를 계산합니다.
result_df['total_count'] = result_df['count'] + result_df['reverse_count']
# 승률을 계산합니다. (승리 횟수 / 전체 경기 횟수)
result_df['win_rate'] = result_df['count'] * 100 / result_df['total_count']
# None 값과 무기가 서로 같은 경우를 제거합니다.
result_df = result_df[(result_df['victim_weapon'].notnull()) & (result_df['killer_weapon'] != result_df['victim_weapon'])]
# 전체 대상 무기 추출
target = result_df['killer_weapon'].unique()
result = {}
for weapon in target:
filtered_df = result_df[(result_df['killer_weapon'] == weapon) & (result_df['total_count'] >= 20)]
filtered_df["high"] = filtered_df["win_rate"] >= 50 # 승률 50%를 기준으로 새로운 'high' 컬럼에 True 또는 False 값 저장합니다.
high_weapons = filtered_df[filtered_df["high"]].sort_values('win_rate', ascending=False)[:3]
low_weapons = filtered_df[~filtered_df["high"]].sort_values('win_rate', ascending=False)[-3:]
high_weapons.drop('high', axis=1, inplace=True)
low_weapons.drop('high', axis=1, inplace=True)
result[weapon] = {
"highs": high_weapons,
"lows": low_weapons,
}
result_list = []
for weapon in result.keys():
highs = result[weapon]["highs"].reset_index(drop=True) if result[weapon]["highs"] is not None else pd.DataFrame(columns=['victim_weapon', 'win_rate'])
lows = result[weapon]["lows"].reset_index(drop=True) if result[weapon]["lows"] is not None else pd.DataFrame(columns=['victim_weapon', 'win_rate'])
result_list.append({
"weapon_name": weapon,
**{f"easy_weapon_{i + 1}": row["victim_weapon"] if not pd.isna(row["victim_weapon"]) else None for i, row in highs.iterrows()},
**{f"easy_percent_{i + 1}": row["win_rate"] if not pd.isna(row["win_rate"]) else None for i, row in highs.iterrows()},
**{f"hard_weapon_{i + 1}": row["victim_weapon"] if not pd.isna(row["victim_weapon"]) else None for i, row in lows.iterrows()},
**{f"hard_percent_{i + 1}": row["win_rate"] if not pd.isna(row["win_rate"]) else None for i, row in lows.iterrows()},
})
final_df = pd.DataFrame(result_list)
final_df = final_df.fillna(0)
- 결과값
중복데이터도 사라지고, 승률이 높아야 할 easy_percent가 50 아래인 경우도 없어졌다.

최종 dag코드
read_data_task : 이전 포스트에서 저장했던 여러 매치 데이터에서 파싱한 무기데이터 불러오기
process_data_task : 무기 상성 및 무기 티어 데이터 처리
update_database_task : 처리한 데이터를 DB에 최신화
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
import os
from google.cloud import storage
import numpy as np
import pandas as pd
from io import BytesIO
import io
import pyarrow
# slack_notifications.py
from slack_notifications import SlackAlert
from airflow.models import Variable
import pymysql
from config import DB_CONFIG
KEY_PATH = "./playdata-2-1e60a2f219de.json"
os.environ["GOOGLE_APPLICATION_CREDENTIALS"] = KEY_PATH
slack_api_token = Variable.get("slack_api_token")
alert = SlackAlert('#message', slack_api_token) # 메세지를 보낼 슬랙 채널명을 파라미터로 넣어줍니다.
dag = DAG(
dag_id="load_weapon_data",
description="무기_분석",
start_date=datetime(2023, 7, 1, 0, 0),
schedule_interval='0 16 * * *',
on_success_callback=alert.success_msg,
on_failure_callback=alert.fail_msg
)
def _read_data_from_gcp_storage(**kwargs):
bucket_name = "playdata2"
file_path = "logs_weapon/"
storage_client = storage.Client()
bucket = storage_client.bucket(bucket_name)
parquet_data = []
blobs = bucket.list_blobs(prefix=file_path)
for blob in blobs:
# parquet 형식의 파일인지 확인
if blob.name.endswith(".parquet"):
# 객체를 바이트 스트림으로 다운로드
byte_stream = io.BytesIO(blob.download_as_bytes())
# parquet 데이터를 pandas DataFrame으로 읽기
df = pd.read_parquet(byte_stream)
parquet_data.append(df)
# 개별 DataFrame들을 하나의 DataFrame으로 합치기
concat_data = pd.concat(parquet_data, axis=0, ignore_index=True)
kwargs['ti'].xcom_push(key='parquet_data', value=concat_data)
def _process_weapon_data(**kwargs):
# GCP Storage에서 데이터 읽어오기
parquet_data = kwargs['ti'].xcom_pull(key='parquet_data')
kv3 = pd.concat(parquet_data, axis=0, ignore_index=True)
result_df = kv3.groupby(['killer_weapon', 'victim_weapon']).size().reset_index(name='count')
reverse_combinations = result_df.rename(columns={'killer_weapon': 'victim_weapon', 'victim_weapon': 'killer_weapon', 'count': 'reverse_count'})
result_df = result_df.merge(reverse_combinations, on=['killer_weapon', 'victim_weapon'], how='outer')
result_df.fillna(0, inplace=True)
result_df['total_count'] = result_df['count'] + result_df['reverse_count']
result_df['win_rate'] = result_df['count'] * 100 / result_df['total_count']
result_df = result_df[(result_df['victim_weapon'].notnull()) & (result_df['killer_weapon'] != result_df['victim_weapon'])]
target = result_df['killer_weapon'].unique()
result = {}
for weapon in target:
filtered_df = result_df[(result_df['killer_weapon'] == weapon) & (result_df['total_count'] >= 20)].sort_values('win_rate', ascending=False)
high_weapons = filtered_df.iloc[:3] if filtered_df.shape[0] >= 3 else filtered_df
low_weapons = filtered_df.iloc[-3:] if filtered_df.shape[0] >= 3 else filtered_df
result[weapon] = {
"highs": high_weapons,
"lows": low_weapons,
}
result_list = []
for weapon in result.keys():
result_list.append({
"weapon_name": weapon,
**{f"easy_weapon_{i + 1}": row["victim_weapon"] if row["victim_weapon"] else None for i, row in result[weapon]["highs"].reset_index(drop=True).iterrows()},
**{f"easy_percent_{i + 1}": row["win_rate"] if row["win_rate"] else None for i, row in result[weapon]["highs"].reset_index(drop=True).iterrows()},
**{f"hard_weapon_{i + 1}": row["victim_weapon"] if row["victim_weapon"] else None for i, row in result[weapon]["lows"].reset_index(drop=True).iterrows()},
**{f"hard_percent_{i + 1}": row["win_rate"] if row["win_rate"] else None for i, row in result[weapon]["lows"].reset_index(drop=True).iterrows()},
})
final_df = pd.DataFrame(result_list)
final_df = final_df.fillna(0)
games_threshold = 30
weapon_summary2 = result_df.groupby('killer_weapon').agg({'total_count': 'sum', 'count': 'sum'}).reset_index()
weapon_summary2['win_rate'] = weapon_summary2['count'] * 100 / weapon_summary2['total_count']
valid_weapons = weapon_summary2[weapon_summary2['total_count'] >= games_threshold]
count_weight = 0.2
win_rate_weight = 0.8
weapon_summary2['score'] = (weapon_summary2['total_count'] * count_weight) + (weapon_summary2['win_rate'] * win_rate_weight)
quantiles = weapon_summary2['score'].quantile([.9, .8, .5, .3, 0]).values
tier_1 = weapon_summary2[weapon_summary2['score'] >= quantiles[0]]
tier_2 = weapon_summary2[(weapon_summary2['score'] >= quantiles[1]) & (weapon_summary2['score'] < quantiles[0])]
tier_3 = weapon_summary2[(weapon_summary2['score'] >= quantiles[2]) & (weapon_summary2['score'] < quantiles[1])]
tier_4 = weapon_summary2[(weapon_summary2['score'] >= quantiles[3]) & (weapon_summary2['score'] < quantiles[2])]
tier_5 = weapon_summary2[weapon_summary2['score'] < quantiles[3]]
tier_1_sorted = tier_1.sort_values('score', ascending=True)['killer_weapon'].tolist()
tier_2_sorted = tier_2.sort_values('score', ascending=True)['killer_weapon'].tolist()
tier_3_sorted = tier_3.sort_values('score', ascending=True)['killer_weapon'].tolist()
tier_4_sorted = tier_4.sort_values('score', ascending=True)['killer_weapon'].tolist()
tier_5_sorted = tier_5.sort_values('score', ascending=True)['killer_weapon'].tolist()
for idx, row in weapon_summary2.iterrows():
if row['killer_weapon'] in tier_1_sorted:
weapon_summary2.loc[idx, 'tier'] = 1
elif row['killer_weapon'] in tier_2_sorted:
weapon_summary2.loc[idx, 'tier'] = 2
elif row['killer_weapon'] in tier_3_sorted:
weapon_summary2.loc[idx, 'tier'] = 3
elif row['killer_weapon'] in tier_4_sorted:
weapon_summary2.loc[idx, 'tier'] = 4
else:
weapon_summary2.loc[idx, 'tier'] = 5
weapon_summary2['tier'] = weapon_summary2['tier'].astype(int)
final_df = final_df.merge(weapon_summary2[['killer_weapon', 'tier']], left_on='weapon_name', right_on='killer_weapon', how='left').drop(columns=['killer_weapon'])
output_filename = "result.csv"
final_df.to_csv(output_filename, index=False)
return final_df
def _update_database(final_df):
conn = pymysql.connect(**DB_CONFIG)
cur = conn.cursor()
for index, row in final_df.iterrows():
weapon_name = row['weapon_name']
easy_weapon_1 = row['easy_weapon_1']
easy_weapon_2 = row['easy_weapon_2']
easy_weapon_3 = row['easy_weapon_3']
easy_percent_1 = row['easy_percent_1']
easy_percent_2 = row['easy_percent_2']
easy_percent_3 = row['easy_percent_3']
hard_weapon_1 = row['hard_weapon_1']
hard_weapon_2 = row['hard_weapon_2']
hard_weapon_3 = row['hard_weapon_3']
hard_percent_1 = row['hard_percent_1']
hard_percent_2 = row['hard_percent_2']
hard_percent_3 = row['hard_percent_3']
weapon_tier = row['tier']
update_query = """
UPDATE services_weapons SET weapon_tier = %s,
first_easy_weapon = %s,
first_easy_percent = %s,
second_easy_weapon = %s,
second_easy_percent = %s,
third_easy_weapon = %s,
third_easy_percent = %s,
first_hard_weapon = %s,
first_hard_percent = %s,
second_hard_weapon = %s,
second_hard_percent= %s,
third_hard_weapon = %s,
third_hard_percent = %s WHERE weapon_name = %s
"""
cur.execute(update_query, (weapon_tier, easy_weapon_1, easy_percent_1, easy_weapon_2, easy_percent_2, easy_weapon_3, easy_percent_3,
hard_weapon_1, hard_percent_1, hard_weapon_2, hard_percent_2, hard_weapon_3, hard_percent_3,
weapon_name))
conn.commit()
read_data_task = PythonOperator(
task_id='read_data',
python_callable=_read_data_from_gcp_storage,
provide_context=True
)
process_data_task = PythonOperator(
task_id='process_data',
python_callable=_process_weapon_data,
provide_context=True
)
update_database_task = PythonOperator(
task_id='update_database',
python_callable=_update_database,
provide_context=True
)
read_data_task >> process_data_task >> update_database_task
회고
배틀그라운드라는 게임을 많이 해보지 않았지만, 이번 프로젝트를 수행하며 배틀그라운드 게임도 많이 해보고, 특히 무기 관련해서 많이 보게 되었다.
처음에는 어느 총이 좋은 총인지도 몰라 해메었지만, 이번 분석을 통해 어느 정도 티어가 확립되고 나니 나에게 맞는 총, 그 총에 대한 정보를 알 수 있었다.
아쉬운점
아쉬운 점이 있다면, 주무기만을 한정해서 만든게 좀 아쉬웠다. 데이터를 파싱하는 데에 시간이 많이 들어 범위를 축소해서 분석을 수행했었다. 시간이 더 있었다면 다른 종류에 무기들에 대해서도 조사해보고 싶다. ( 투척무기, 근접무기, 권총 등)
