쇼핑몰 로그 데이터 분석해보기
8대로 구성된 하둡, 스파크 클러스터를 활용하여 데이터 분석

흐름도 (예상안)

- 데이터셋 - (eCommerce behavior data from multi category store)
데이터셋 구조
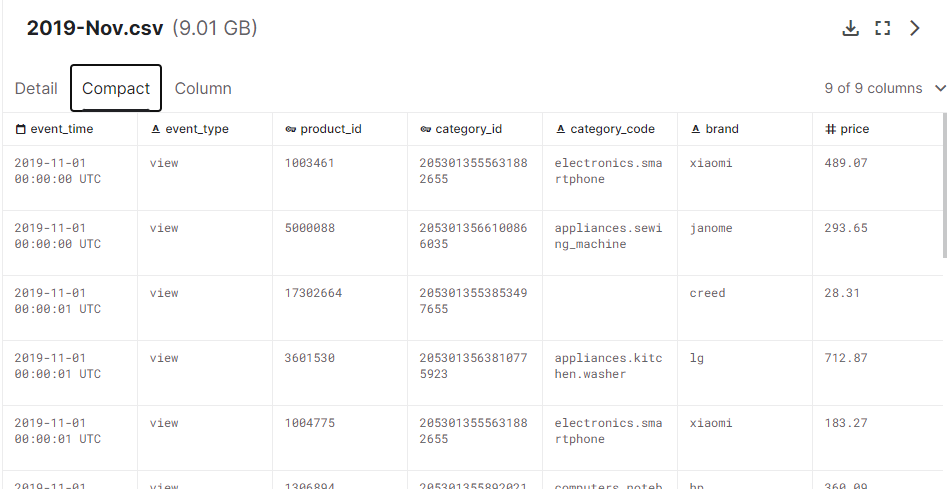
데이터 로드
캐글 사이트에 접속 후 데이터를 다운로드 받았다. (위의 데이터셋 링크 참조)
데이터의 압축 해제 후 hdfs dfs -put ./2019-Nov.csv /08
HDFS 08폴더에 저장하였다.
데이터 전처리
데이터 불러오기
df = spark.read.option("header", "true").csv("hdfs:/08/2019-Nov2.csv")
스파크 세션 생성

Raw Data.ver
| 컬럼명 | 컬럼 설명 | 예시 |
|---|---|---|
| event_time | 이벤트 발생 시간 | 2019-11-01 00:00:00 UTC |
| event_type | 이벤트 유형 | view / cart / purchase |
| product_id | 상품 id | 9800515 |
| category_id | 카테고리 id | 2053013558920217191 |
| category_code | 카테고리 분류 | appliances.kitchen.oven |
| brand | 브랜드명 | samsung |
| price | (상품)가격 | 489.07 |
| user_id | 유저 id | 520088904 |
| user_session | 유저 세션 | 4d3b30da-a5e4-49df-b1a8-ba5943f1dd33 |

Modified.ver (전처리 후 버전 —> 카테고리 대/중/소 분할 등 처리)"."을 기준으로 칼럼 나누기
split_col = split(df["category_code"], "\\.")
df = df.withColumn("major", split_col.getItem(0))
df = df.withColumn("intermediate", split_col.getItem(1))
df = df.withColumn("minor", split_col.getItem(2))
| 컬럼명 | 컬럼 설명 | 예시 |
|---|---|---|
| event_time | 이벤트 발생 시간 | 2019-11-01 00:00:00 UTC |
| event_type | 이벤트 유형 | view / cart / purchase |
| product_id | 상품 id | 9800515 |
| category_id | 카테고리 id | 2053013558920217191 |
| category_code | 카테고리 분류 | appliances.kitchen.oven |
| brand | 브랜드명 | samsung |
| price | (상품)가격 | 489.07 |
| user_id | 유저 id | 520088904 |
| user_session | 유저 세션 | 4d3b30da-a5e4-49df-b1a8-ba5943f1dd33 |
| major | 대분류 | appliances |
| intermediate | 중분류 | kitchen |
| minor | 소분류 | oven |

데이터 전처리 후 데이터 마트 생성
데이터에 category_code가 null값인 것을 제외하고 카테고리를 .을 기준으로 나눠 대, 중, 소분류 칼럼을 만들어 google bigquery에 적재하였다.
from pyspark.sql.functions import col
from google.cloud import bigquery
from google.oauth2 import service_account
import pandas as pd
import pyarrow
# category_code가 널이 아닌 레코드 필터링
filtered_df = df.filter(col("category_code").isNotNull())
# GCP 서비스 계정 키 파일 경로
key_path = "키파일경로" json 파일
# 프로젝트 및 데이터셋 ID
project_id = "프로젝트 ID"
dataset_id = "프로젝트 ID.데이터셋 ID"
# BigQuery 클라이언트 설정
client = bigquery.Client.from_service_account_json(key_path)
# 데이터 프레임을 팬더스 데이터 프레임으로 변환(데이터 시리얼라이즈)
# pandas_df = df.select("*").toPandas()
pandas_df = df.limit(100000).toPandas()
# BigQuery로 데이터 프레임 전송
table_id = "프로젝트 ID.데이터셋 ID.테이블"
job_config = bigquery.LoadJobConfig(
# 스키마 자동 감지
schema=[],
autodetect=True,
# 데이터 쓰기 방식 선택
write_disposition=bigquery.WriteDisposition.WRITE_TRUNCATE, # 이전 테이블 데이터 대체
)
# BigQuery에 데이터 프레임 불러오기
job = client.load_table_from_dataframe(
pandas_df, table_id, job_config=job_config
)
# 작업 완료 시간 기록
job.result()
데이터 분석
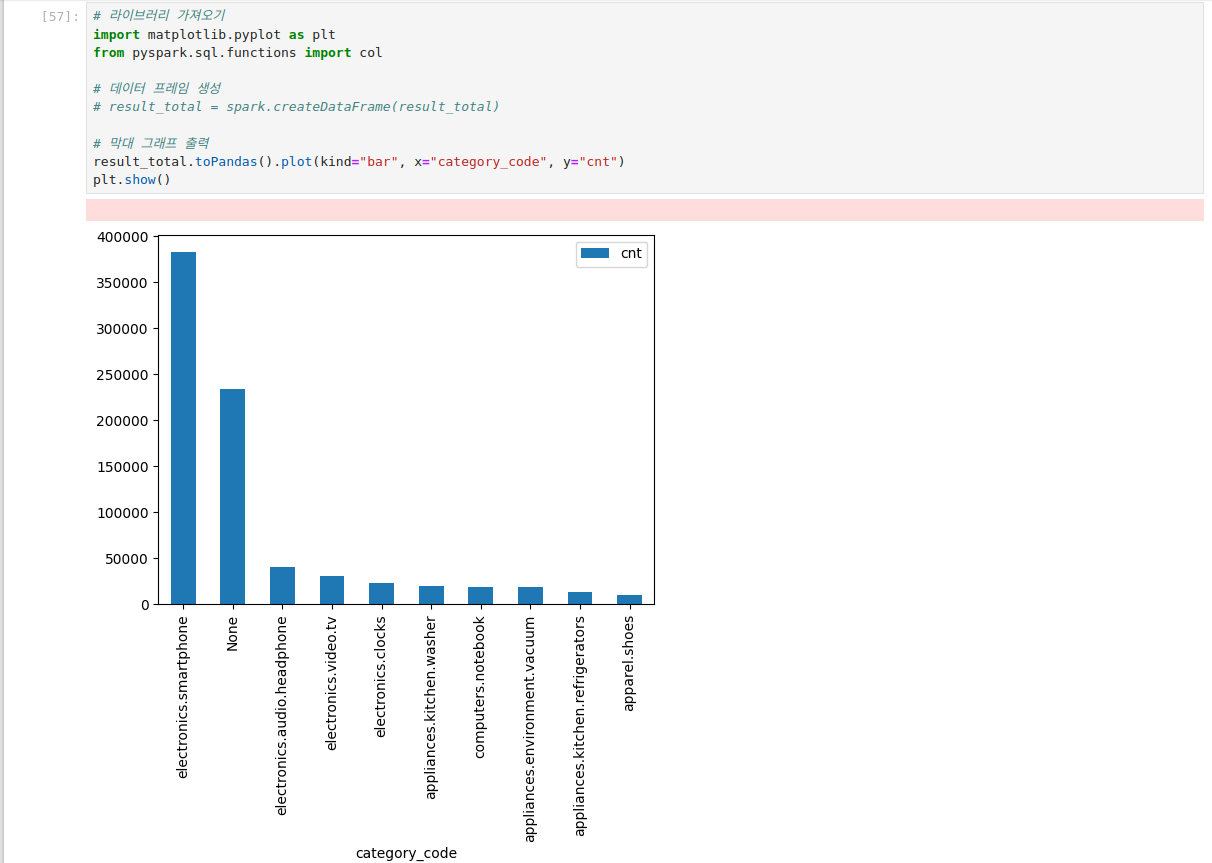
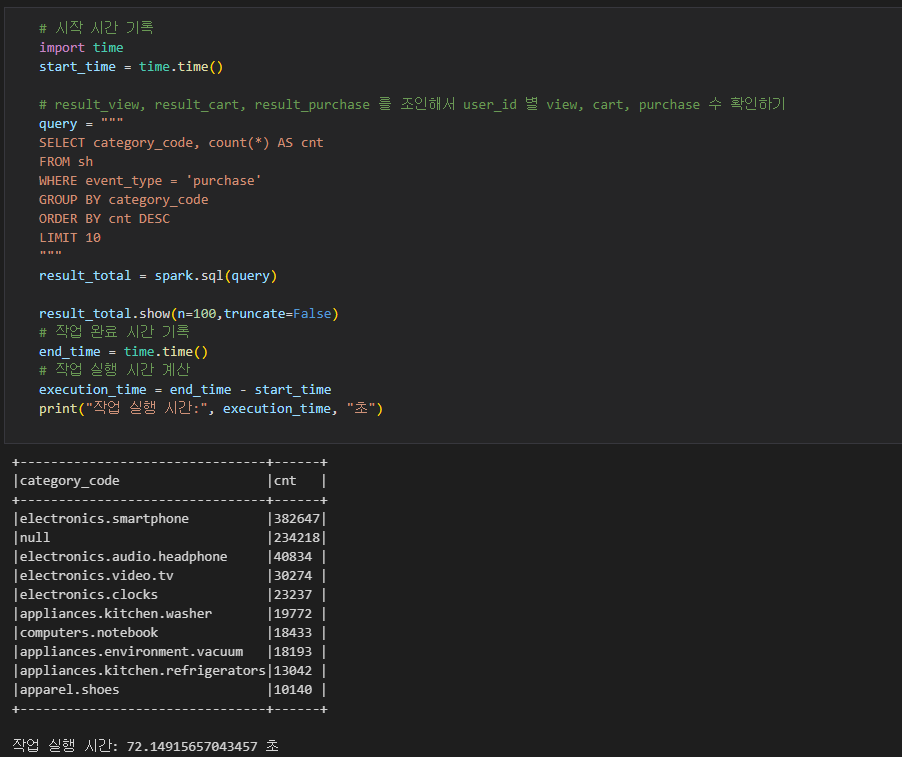
- 카테고리 별 판매 상품 개수 집계 (TOP10)
스파크를 사용한 것과 사용하지 않은 것에 차이가 59초 차이
약 5.54배 정도에 성능을 얻을 수 있었다.
-
Spark 사용

-
로컬
추후 작업
매출, 전환율 현황 분석 리포트를
카테고리 별로 나누어 보기 좋게 제작하고자 한다!

공부 기록