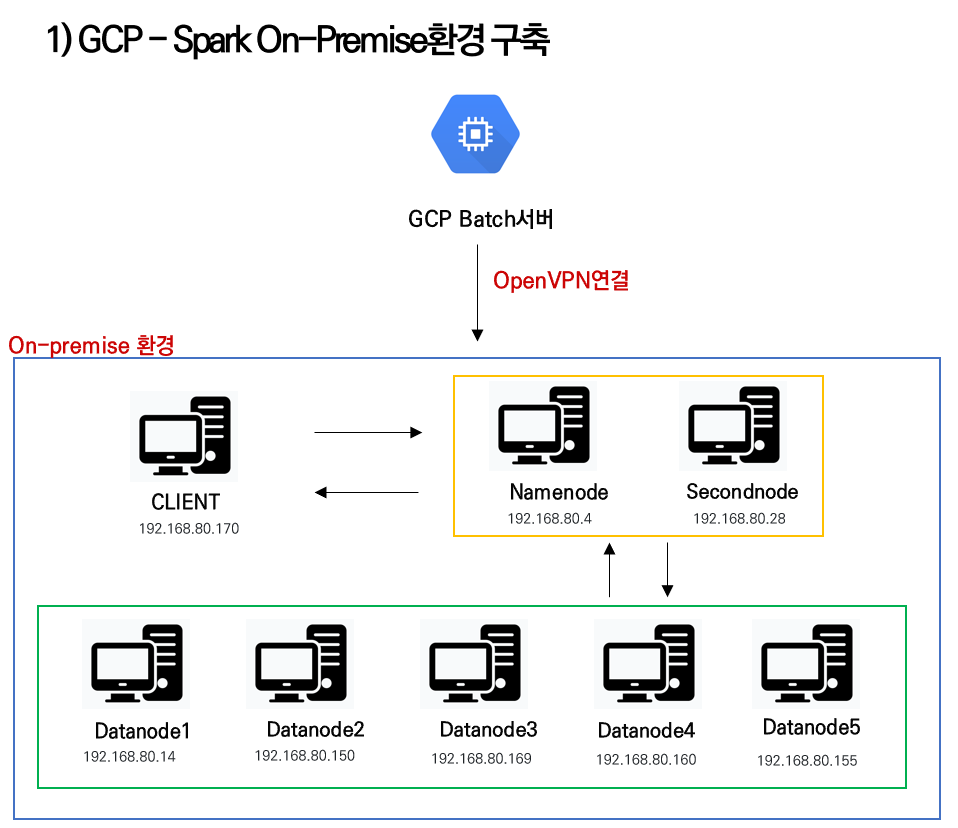
노트북 8대를 이용하여 클러스터를 구축
openVPN을 통해 학원IP가 아니더라도 연결하여 작업을 수행할 수 있게 만들어 주었다.
Spark 클러스터 모드로 데이터 전처리 하기
from pyspark.sql import SparkSession
from pyspark.sql.functions import col
from pyspark.sql.functions import explode
from pyspark.sql.functions import count
from pyspark.sql.functions import regexp_replace
from pyspark.sql.functions import when, array_contains, coalesce, udf, StringType
df = spark.read.parquet("hdfs:/killv2_/")
df.count()df.printSchema()을 확인해보니 아래와 같이 되어있었다.

총 322656건이 자료가 조회됐다.
df = df.withColumn("victim_weapon", regexp_replace("victim_weapon", r"(?:^Weapon|^Weap)|_C.*$", ""))
df = df.withColumn("killer_weapon", regexp_replace("killer_weapon", r"(?:^Weapon|^Weap)|_C.*$", ""))
df = df.withColumn("무기분류",
when(df['killer_weapon'].isin(['SKS', 'SLR', '미니 14', 'MK12', 'MK14', 'QBU', 'VSS']), 'DMR')
.when(df['killer_weapon'].isin(['AWM', 'KAR98K', '링스 AMR', 'M24', '모신 나강', 'WIN94']), 'SR')
.when(df['killer_weapon'].isin(['토미 건', 'PP-19 비존', '마이크로 UZI', 'MP5K', 'MP9', 'P90', 'UMP45', '벡터']), 'SMG')
.when(df['killer_weapon'].isin(['DP-28', 'M249', 'MG3']), 'LMG')
.when(df['killer_weapon'].isin(['S12K', 'DBS', '012', 'S1897', 'S686', '소드 오프']), 'SG')
.when(df['killer_weapon'].isin(['DEAGLE', 'P18C', 'P1911', 'P92', 'R1895', 'R45', '스콜피온']), 'Pistol')
.when(df['killer_weapon'].isin(['석궁']), 'MISC')
.when(df['killer_weapon'].isin(['M416', 'G36C', 'ACE32', 'AKM', 'AUG', 'FAMAS', '그로자', 'K2', 'M16A4', '베릴 M762', 'MK47 뮤턴트', 'QBZ', 'SCAR-L']), 'AR')
.otherwise("Unknown")
)
weapon_name_mapping = {
'SKS': 'SKS', 'FNFal': 'SLR', 'Mini14': '미니14', 'Mk12': 'MK12', 'Mk14': 'MK14',
'QBU88': 'QBU', 'VSS': 'VSS', 'AWM': 'AWM', 'Kar98k': 'KAR98K', 'L6': '링스 AMR',
'M24': 'M24', 'Mosin': '모신 나강', 'Win1894': 'WIN94', 'Thompson': '토미 건',
'BizonPP19': 'PP-19 비존', 'UZI': '마이크로 UZI', 'MP5K': 'MP5K', 'MP9': 'MP9',
'P90': 'P90', 'UMP': 'UMP45', 'Vector': '벡터', 'DP28': 'DP-28', 'M249': 'M249',
'MG3': 'MG3', 'Saiga12': 'S12K', 'DP12': 'DBS', 'OriginS12': 'O12',
'Winchester': 'S1897', 'Berreta686': 'S686', 'Sawnoff': '소드 오프',
'DesertEagle': 'Deagle', 'G18': 'P18C', 'M1911': 'P1911', 'M9': 'P92',
'NagantM1895': 'R1895', 'Rhino': 'R45', 'vz61Skorpion': '스콜피온',
'Crossbow_1': '석궁', 'HK416': 'M416', 'G36C': 'G36C', 'ACE32': 'ACE32',
'AK47': 'AKM', 'AUG': 'AUG', 'Mk47Mutant': 'MK47 뮤턴트', 'FamasG2': 'FAMAS',
'G36C': 'G36C', 'K2': 'K2', 'M16A4': 'M16A4', 'BerylM762': '베릴 M762',
'QBZ95': 'QBZ', 'SCAR-L': 'SCAR-L', 'Groza': '그로자'
}
from pyspark.sql.functions import udf
from pyspark.sql.types import StringType
def map_weapon(weapon):
return weapon_mapping.get(weapon, weapon)
map_weapon_udf = udf(map_weapon, StringType())
df_exploded = df.withColumn("killer_weapon", map_weapon_udf(df["killer_weapon"]))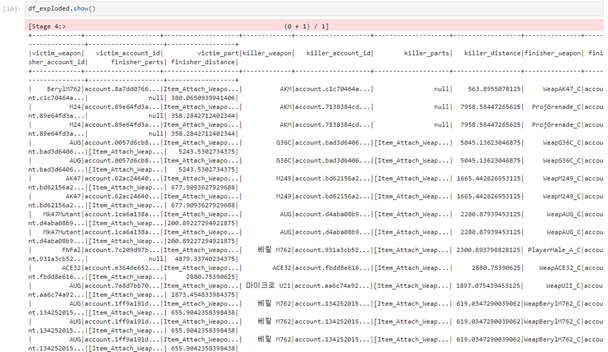
매치 데이터가 많아져 전처리를 한꺼번에 수행하려 하면 로컬에서 실행할 경우에 커널이 죽어버리는 현상이 발생했는데, 클러스터를 형성하여 파케이 파일들을 다 불러모아 실행하니 커널이 죽지 않고 전처리가 잘 됐다.
- 간혹 파케이 파일의 스키마 형식이 잘못되어 오류가 발생하는 경우가 있었다.
victim_weapon의 형태가 string이 기댓값인데, int32로 되어있는 경우가 있었기 때문이다.
그래서 아래와 같은 코드로 형태를 변형시켜서 적용하였다.
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, when
import re
# Spark 세션 생성
spark = SparkSession.builder.appName("WeaponPreprocessing").getOrCreate()
# 여러 개의 Parquet 파일을 동시에 로드
df = spark.read.parquet("hdfs:/killv2_/")
# victim_weapon 컬럼 데이터 타입 변환
df = df.withColumn("victim_weapon", col("victim_weapon").cast("string"))
# killer_weapon 컬럼 값 전처리
df = df.withColumn("killer_weapon", regexp_replace("killer_weapon", r"(?:^Weapon|^Weap)|_C.*$", ""))
df = df.withColumn("killer_weapon",
when(df['killer_weapon'] == 'SKS', 'SKS')
.when(df['killer_weapon'] == 'FNFal', 'SLR')
.when(df['killer_weapon'] == 'Mini14', '미니14')
.when(df['killer_weapon'] == 'Mk12', 'MK12')
.when(df['killer_weapon'] == 'Mk14', 'MK14')
# 다른 경우도 추가해주세요
.otherwise(df['killer_weapon'])
)
# 무기분류 컬럼 생성
df = df.withColumn("무기분류",
when(df['killer_weapon'].isin(['SKS', 'SLR', '미니14', 'MK12', 'MK14']), 'DMR')
.when(df['killer_weapon'].isin(['AWM', 'KAR98K', '링스 AMR', 'M24', '모신 나강', 'WIN94']), 'SR')
.when(df['killer_weapon'].isin(['토미 건', 'PP-19 비존', '마이크로 UZI', 'MP5K', 'MP9', 'P90', 'UMP45', '벡터']), 'SMG')
.when(df['killer_weapon'].isin(['DP-28', 'M249', 'MG3']), 'LMG')
.when(df['killer_weapon'].isin(['S12K', 'DBS', '012', 'S1897', 'S686', '소드 오프']), 'SG')
.when(df['killer_weapon'].isin(['DEAGLE', 'P18C', 'P1911', 'P92', 'R1895', 'R45', '스콜피온']), 'Pistol')
.when(df['killer_weapon'].isin(['석궁']), 'MISC')
.when(df['killer_weapon'].isin(['M416', 'G36C', 'ACE32', 'AKM', 'AUG', 'FAMAS', '그로자', 'K2', 'M16A4', '베릴 M762', 'MK47 뮤턴트', 'QBZ', 'SCAR-L']), 'AR')
.otherwise("Unknown")
)
# 변환 결과 확인
df.show()
# 이제 df를 사용하여 원하는 분석 작업을 수행할 수 있습니다.
# Spark 세션 종료
spark.stop()

공부 기록