VirtualBox 실행
VirtualBox를 켜서 가상머신 4개 창을 계속 띄우니 화면이 복잡함
bat파일을 통해 창을 백그라운드에서 실행
bat 파일이란?
- BAT 파일은 Batch 파일의 줄임말로, 윈도우 기반 컴퓨터에서 실행되는 스크립트 파일
- 이 파일 형식은 .bat 확장자를 가지며, 한 개 이상의 명령어를 포함하여 일련의 작업을 자동화할 수 있다.
메모장에 다음과 같이 입력 후 hadoop.bat로 저장
- 가상머신 이름 (hadoop client / hadoop namenode / hadoop secondnode / hadoop datanode3)
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm "hadoop client" --type headless
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm "hadoop namenode" --type headless
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm "hadoop secondnode" --type headless
"C:\Program Files\Oracle\VirtualBox\VBoxManage.exe" startvm "hadoop datanode3" --type headless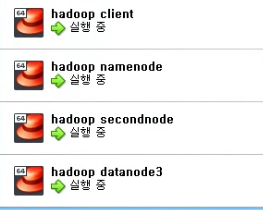
Superputty 접속 (client)
192.168.56.11 client 접속

hadoop 계정에서 별칭으로 지정한 명령어 실행
start_dfs
start_yarn
start_mr
start-dfs.sh - 분산 파일 시스템(Distributed File System)을 시작
start-yarn.sh - YARN(Yet Another Resource Negotiator) 시작
start-mr.sh - MapReduce 작업 이력 서버 시작
용어정리
YARN
YARN은 Hadoop 클러스터에서 리소스 관리와 작업 스케줄링을 담당
HDFS
HDFS는 대용량의 데이터를 분산 저장하는 분산 파일 시스템
MapReduce
MapReduce는 데이터 처리 작업을 분산하여 실행하는 분산 프로그래밍 모델
Spark 실행
pyspark --master yarn --num-executors 3 명령어 실행
client:8888 jupyter notebook 접속
# 스파크 세션 띄우기
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("PySpark to MySQL").config("spark.jars", "mysql-connector-java-8.0.21.jar").getOrCreate()코드 해석
SparkSession.builder: SparkSession을 생성하기 위한 빌더 객체를 생성appName("PySpark to MySQL"): Spark 애플리케이션의 이름을 "PySpark to MySQL"로 지정config("spark.jars", "mysql-connector-java-8.0.21.jar"): Spark의 환경 설정 중 "spark.jars" 옵션을 설정하여, "mysql-connector-java-8.0.21.jar"라는 JAR 파일을 Spark에 제공
- JAR 파일은 MySQL과의 연결을 위해 필요한 JDBC 드라이버
getOrCreate(): 설정된 옵션을 기반으로 SparkSession 객체를 생성하거나, 이미 존재하는 SparkSession 객체를 반환함. 이미 생성된 SparkSession이 있는 경우 새로운 SparkSession을 생성하지 않고 기존의 SparkSession을 사용
df = spark.read.format("csv")\
.option("header", "true")\
.option("inferSchema", "true")\
.load("/data/retail-data/*")코드 해석
spark.read.format("csv"): SparkSession을 사용하여 CSV 파일을 읽기 위한 데이터소스 형식을 설정.option("header", "true"): CSV 파일의 첫 번째 줄을 헤더로 처리하도록 옵션을 설정.option("inferSchema", "true"): 데이터프레임의 스키마를 자동으로 추론하도록 옵션을 설정.load("/data/retail-data/*"): 지정된 경로에서 CSV 파일을 로드하여 데이터프레임을 생성/data/retail-data/*는/data/retail-data/디렉토리에 있는 모든 CSV 파일을 로드하도록 지정
# PySpark에서 데이터프레임을 임시 뷰로 등록하는 코드
df.createOrReplaceTempView("dfTable")# dfTable에 있는 모든 칼럼을 보여줘 (상위 5개만 표시)
spark.sql("select * from dfTable").show(5)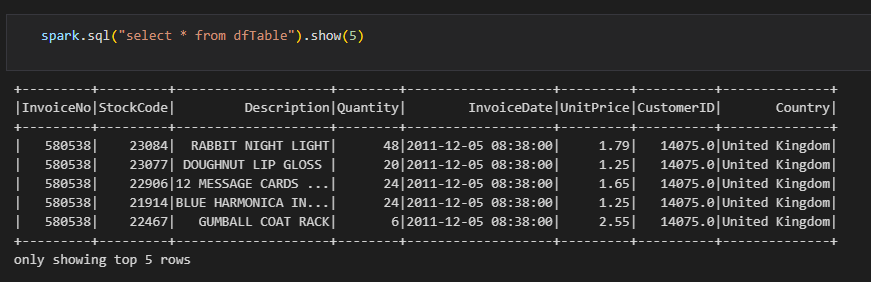
데이터 베이스와 자료 교환해보기
JDBC(Java Database Connectivity)란?
- JDBC는 Java 프로그래밍 언어를 사용하여 데이터베이스와 연결하고 상호 작용하기 위한 API(응용 프로그래밍 인터페이스)입니다. JDBC를 사용하면 Java 애플리케이션에서 다양한 데이터베이스 시스템에 접속하여 데이터베이스와 통신할 수 있다.
- JDBC를 사용하면 데이터베이스 관리 시스템(DBMS)에 대한 특정 드라이버를 로드하고, 연결을 설정하고, SQL 쿼리를 실행하고, 결과를 검색하는 등의 작업을 수행할 수 있다. JDBC는 일관된 방식으로 다양한 데이터베이스와 상호 작용할 수 있도록 표준화된 API를 제공한다.
# 우리 조의 데이터 베이스의 접속 (테이블명은 battleGround)
jdbc_url = "jdbc:mysql:// [ip주소]:3306/[테이블명]?serverTimezone=UTC" # 데이터베이스 URL
table_name = "jk" # 테이블 이름
properties = {
"user": "[사용자명]", # MySQL 사용자명
"password": "[비밀번호]" # MySQL 비밀번호
}코드해석
- jdbc_url: 데이터베이스의 URL을 나타냅니다. 주어진 URL은 jdbc:mysql://[IP주소]:3306/battleGround?serverTimezone=UTC로, MySQL 데이터베이스에 접속하기 위한 URL입니다. [IP 주소]는 데이터베이스 서버의 IP 주소이고, 3306은 MySQL의 기본 포트 번호입니다. battleGround은 데이터베이스의 이름을 나타냅니다. serverTimezone=UTC는 데이터베이스 서버의 시간대를 UTC로 설정
- table_name: 작업을 수행할 테이블의 이름을 나타냅니다. 주어진 코드에서는 jk라는 테이블을 사용합니다.
- properties: 데이터베이스 연결을 위한 추가 속성을 포함하는 맵입니다. 여기서는 user와 password를 설정하고 있습니다. user는 MySQL의 사용자명을 나타내며, password는 해당 사용자의 비밀번호를 나타냅니다.
- 이러한 설정을 사용하여 코드에서는 주어진 JDBC URL을 통해 MySQL 데이터베이스에 연결하고, jk라는 테이블에서 작업을 수행할 수 있게 된다.
DataFrame을 DB에 저장하기
# 앞서 불러왔던 retail-data에 모든 csv를 battleGround DB에 만든 jk테이블로 저장
df.write.jdbc(url=jdbc_url, table=table_name, mode="append", properties=properties)명령어 이후 DB 확인 (아래 사진)
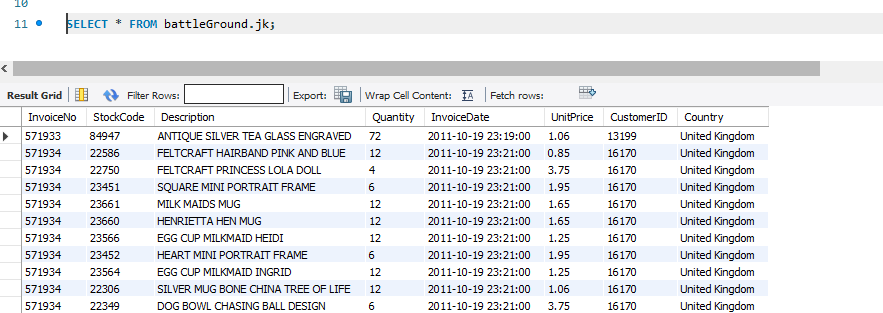
DB에 있는 데이터 불러오기
battleGround DB에 있는 position 테이블 읽기
battle_position = spark.read.jdbc(url=jdbc_url, table='position', properties=properties)
공부 기록