스파크 세션 열기
from pyspark.sql import SparkSessionfrom pyspark.sql.types import StructField, StructType, StringType, LongType
스키마는 DataFrame의 컬럼명과 데이터 타입을 정의
- CSV나 JSON 같은 일반 텍스트 파일을 사용하면 다소 느릴 수 있음
- 하지만 Long 데이터 타입을 Integer 데이터 타입으로 잘못 인식하는 등 정밀도 문제가 발생할 수 있음
- 따라서 운영 환경에서 추출, 변환, 적재를 수행하는 ETL 작업에 스파크를 사용한다면 직접 스키마를 정의해야 함
- ETL 작업 중에 데이터 타입을 알기 힘든 CSV나 JSON 등의 데이터소스를 사용하는 경우 스키마 추론 과정에서 읽어 들인 샘플 데이터의 타입에 따라 스키마를 결정해 버릴 수 있음
스키마는 여러 개의 StructField 타입 필드로 구성된 StructType 객체
- StructField는 이름, 데이터 타입, 컬럼이 값이 없거나 null 일 수 있는지 지정하는 불리언값을 가짐
- 필요한 경우 컬럼과 관련된 메타데이터를 지정할 수 있음
- pyspark.sql.types: PySpark에서 구조화된 데이터를 다루기 위한 데이터 타입 및 스키마를 정의하는 모듈
- StructField: 구조화된 데이터의 필드 또는 열(column)을 정의하는 클래스입니다. 각 필드는 이름(name), 데이터 타입(dataType), 널 허용 여부(nullable) 등의 속성을 가지고 있다.
- StructType: 구조화된 데이터의 스키마(schema)를 정의하는 클래스입니다. 스키마는 여러 StructField 객체로 구성되어 있으며, 각 필드의 이름과 데이터 타입을 정의하여 DataFrame의 열 구조를 설명
- StringType: 문자열 데이터 타입을 나타내는 클래스입니다. PySpark에서 문자열은 StringType으로 표현
- LongType: 정수형 데이터 타입 중 하나인 Long을 나타내는 클래스입니다. PySpark에서 64비트 정수는 LongType으로 표현
HDFS에 csv파일에 밀어넣기
filezila를 통해 강사님이 주신 json폴더에 csv파일 모두 다운로드 받은 후
홈에다가 옮기기
홈에 옮긴 후
cd json
hdfs dfs -put *.csv ./json csv파일 밀어넣기
hdfs dfs -ls ./json 잘 들어갔는지 확인
Spark 실습해보기
myManualSchema = StructType([
StructField("DEST_COUNTRY_NAME", StringType(), True),
StructField("ORIGIN_COUNTRY_NAME", StringType(), True),
StructField("count", LongType(), False, metadata={"hello":"world"})
])
df = spark.read.format("json").schema(myManualSchema)\
.load("/json/2015-summary.json")StructField 클래스는 PySpark에서 구조화된 데이터의 필드 또는 열(column)을 정의하는 데 사용됩니다. 각 필드는 이름(name), 데이터 타입(dataType), 널 허용 여부(nullable) 등의 속성을 가지고 있다.
- name: 필드의 이름을 나타내는 문자열. 필드의 이름은 해당 필드를 식별하는 데 사용
- dataType: 필드의 데이터 타입을 나타내는 클래스. 데이터 타입은 PySpark의 pyspark.sql.types 모듈에서 제공하는 클래스를 사용하여 지정할 수 있습니다. 예를 들어, 문자열 데이터 타입은 StringType()으로, 정수형 데이터 타입은 LongType()으로 지정할 수 있다.
- nullable: 필드의 널 허용 여부를 나타내는 부울 값입니다. 기본값은 True이며, True로 설정되면 해당 필드는 널(null) 값을 가질 수 있다.
- metadata: 필드의 메타데이터를 나타내는 맵입니다. 메타데이터는 추가 정보를 필드에 연결하기 위해 사용될 수 있습니다. 예를 들어, 필드에 대한 설명이나 태그 등의 정보를 메타데이터로 설정할 수 있습니다. 메타데이터는 선택적이며, 필요에 따라 사용할 수 있다.
# 기본폼 StructField(name, dataType, nullable=True, metadata=None)
metadata={"hello":"world"}의 해석
메타데이터는 일반적으로 키-값 형태의 맵(map)으로 표현
여기서는 hello가 키, world가 값이다. 키와 값은 문자열 형태로 지정함
메타 데이터의 키와 값은 개발자가 데이터에 대한 부가적인 정보를 제공하기 위해 사용하는 것이므로, 어떤 값을 사용할 지는 개발자의 재량에 따라 결정됨
예제에서는 설명보단, 임의의 값을 넣었음
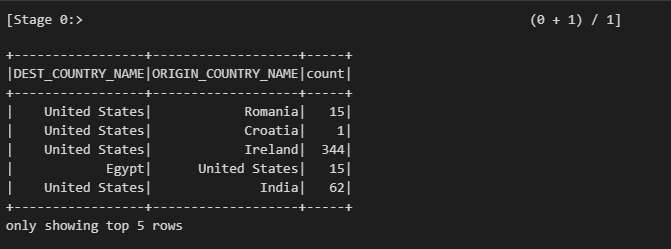
df.explain() 명령어를 입력해 데이터프레임의 실행 계획을 출력 (아래는 출력값)
== Physical Plan ==
FileScan json [DEST_COUNTRY_NAME#0,ORIGIN_COUNTRY_NAME#1,count#2L] Batched: false, DataFilters: [], Format: JSON, Location: InMemoryFileIndex(1 paths)[hdfs://namenode:8020/json/2015-summary.json], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<DEST_COUNTRY_NAME:string,ORIGIN_COUNTRY_NAME:string,count:bigint>
df.show(5) df 5건만 확인
Select와 SelectExpr
select와 selectExpr
- select와 selectExpr 메서드를 사용하면 데이터 테이블에 SQL을 실행하는 것처럼 DataFrame에서 SQL을 사용할 수 있음
- sql과 같은 형태의 쿼리로 여러 칼럼을 선택해 출력 가능
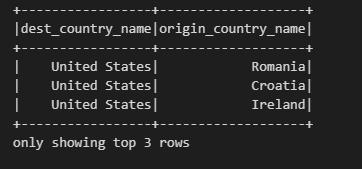
df.select("dest_country_name", "origin_country_name").show(3)
from pyspark.sql.functions import expr, col, column
# 각각 expr, col, column 함수를 사용하여 dest_country_name열을 선택 후 출력
df.select( expr("dest_country_name"), col("dest_country_name"), column("dest_country_name")).show(3)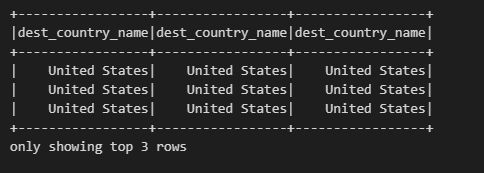
칼럼명 변경 (as, .alias)
# dest_country_name을 destination으로 변경
df.select(expr("dest_country_name as destination")).show(2)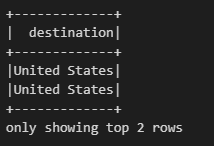
# destination로 변경된 칼럼명을 alias를 이용해 dest_country_name로 변경
df.select(expr("dest_country_name as destination").alias("dest_country_name")).show(2)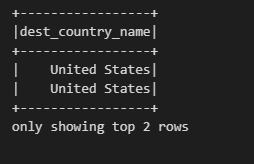
selectExpr
selectExpr 메서드는 스파크의 진정한 능력을 보여줌
- 새로운 DataFrame을 생성하는 복잡한 표현식을 간단하게 만드는 도구
- 모든 유효한 비집계형(non-aggregating) SQL 구문을 지정할 수 있음
- 단, 컬럼을 식별할 수 있어야 함
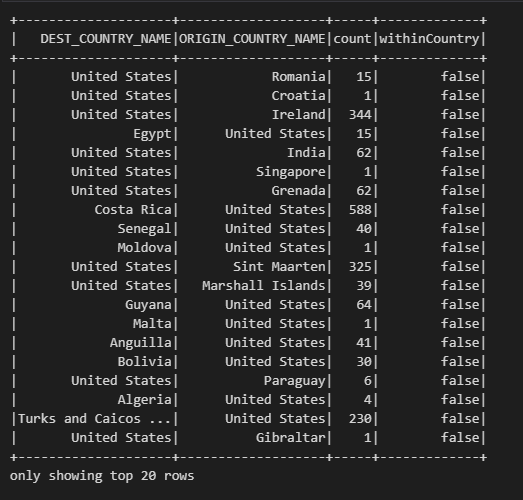
df.selectExpr("*", "(dest_country_name = origin_country_name) as withinCountry").show()"df" DataFrame의 모든 열을 선택하고, "dest_country_name"과 "origin_country_name"이 동일한지 비교하여 "withinCountry" 열을 추가한 뒤, 결과를 출력하는 작업을 수행합니다. "withinCountry" 열은 동일한 국가 내에서 여행한 여부를 나타내는 불리언(Boolean) 값으로 출력
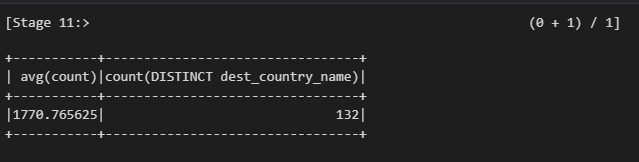
df.selectExpr("avg(count)", "count(distinct(dest_country_name))").show(2)"df" DataFrame에서 "count" 열의 평균과 "dest_country_name" 열의 고유한 값 개수를 계산한 뒤, 결과를 출력하는 작업을 수행
Spark 데이터 타입으로 변환하기
- 새로운 컬럼이 아닌 명시적인 값을 스파크에 전달해야 함
- 명시적인 값은 상수 값일 수 있고, 추후 비교에 사용할 무언가가 될 수도 있음
- 이때 literal을 사용
- 리터럴은 프로그래밍 언어의 리터럴값을 스파크가 이해할 수 있는 값으로 변환
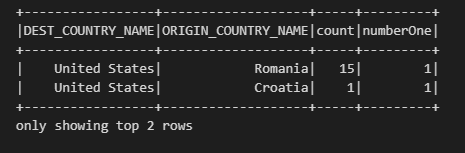
df.withColumn("numberOne", lit(1)).show(2)"df" DataFrame에 "numberOne"이라는 새로운 열을 추가하고, 해당 열의 모든 행에 값 1을 할당한 뒤, 결과를 출력하는 작업을 수행
withColumn 메서드 - DataFrame에 신규 컬럼을 추가하는 방법
.lit 함수를 사용하여 1이라는 상수 할당하고, 출력