개요
윈도우 8대 노트북을 우분투 22.04 LTS를 이용하여 각각의 서버로 만들어 하둡 구성하기
최종 프로젝트를 준비하던 중 데이터가 많아 결과를 보기까지가 오래걸려
분산처리를 한다면 얼마나 시간을 단축할 수 있을까?에 대한 생각으로 온프레미스 환경으로
노트북 8대를 연결하여 Hadoop 클러스터를 구성하였다. 데이터를 HDFS에 밀어넣어
PySpark를 통해 데이터 전처리와 분석을 해보려 한다.
🛠️ 노트북 스펙
OS : Windows 10 HOME
프로세서 : Intel(R) Core(TM) i5-7200U CPU
RAM : 16GB
🛠️ 설정 환경
OS : Ubuntu 22.04
Hadoop : 3.2.1
jdk : 1.8.0
spark : 3.2.4
python : 3.10.10 (miniconda 환경)
프로젝트 인프로 설계도 (변경 가능)
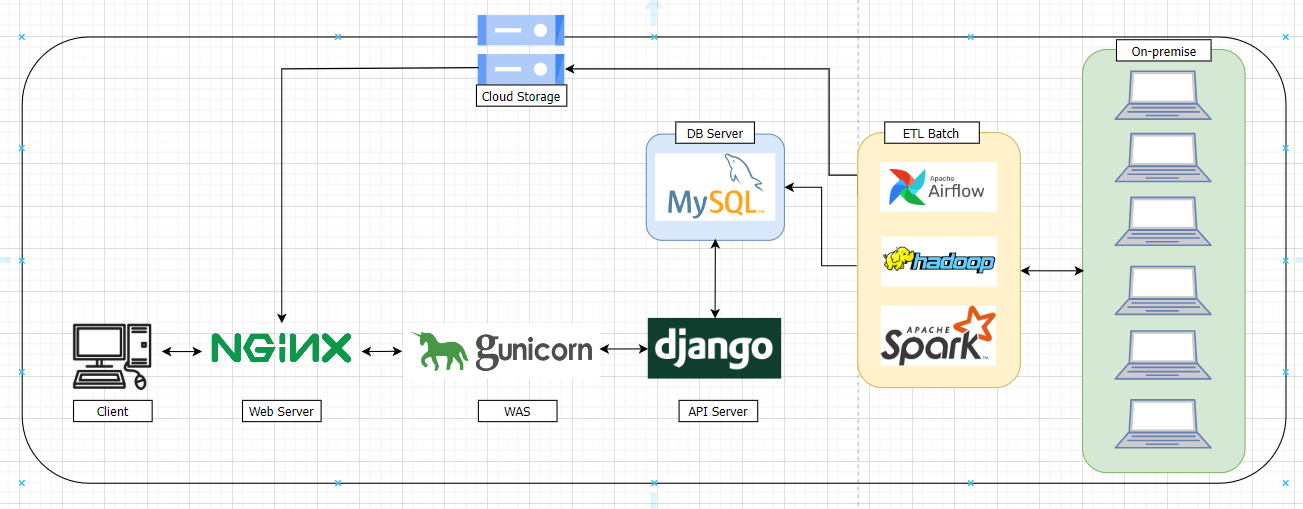
목표: 여러 대의 노트북으로 하둡 클러스터 구성해보기
8개의 노트북으로 client, namenode, secondnode, datanode 1~5를 구성
Ubuntu 22.04 설치
노트북에 기존에 깔려있던 윈도우 운영체제 삭제 후, Ubuntu 운영체제 설치 (USB 이용)
※ 컴퓨터 몇 대가 USB를 통해 Ubuntu 운영체제를 설치하려고 해도 설치되지 않는 현상 발생
기존에 windows 운영체제 파티션 충돌 문제로 인해 설치가 되지 않았다.
수동으로 파티션에 있는 걸 모두 비어준 다음 설치하니 제대로 작동이 되었다.
우분투 한글 설정 방법
터미널을 열어
ibus-setup 명령어 입력
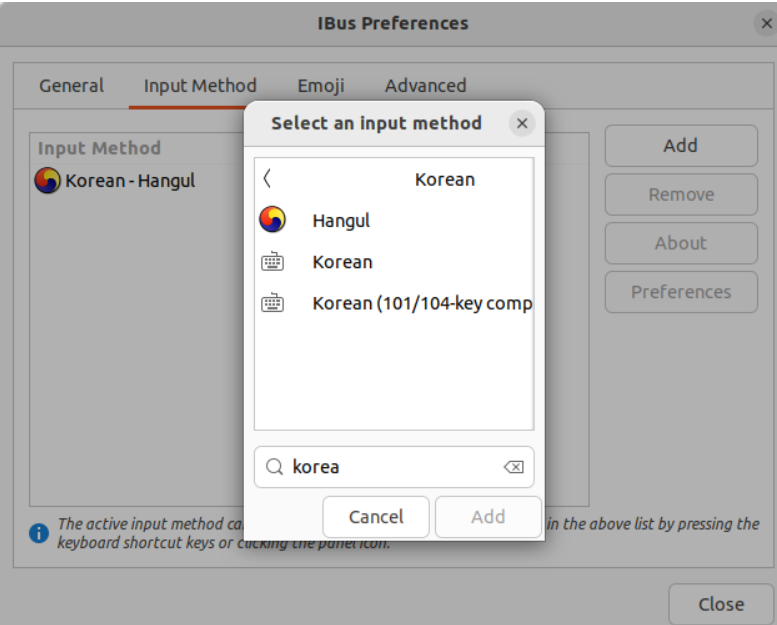
-
Settings > Keyboard > + 버튼을 누르고 > Korean 검색 후 > Korean(Hangul)을 Add
-
여기까지 진행하면 우측상단에서 Korean(Hangul)이 추가되어서 수정할 수 있다.
- 한글, 영어 수정 방법은 Shift+Space 키 혹은 한/영 키를 누르기
hadoop user 생성하기
sudo adduser hadoop hadoop 계정 생성
비밀번호는 hadoop으로 설정
SSH 접속을 위한 키 생성
노트북끼리 서로 원활하게 소통하기 위해 키 생성
퍼블릭 키를 통해 서로의 노트북에 접속 가능케 하기 위함
ssh-keygen -t rsa 키 생성
SSH이란? (What is SSH?)
시큐어 셀(Secure SHell, SSH)은 네트워크 상의 다른 컴퓨터에 로그인하거나 원격 시스템에서 명령을 실행하고 다른 시스템으로 파일을 복사할 수 있도록 해주는 응용 프로그램 또는 그 프로토콜을 가리킨다.
서로 ssh 명령어로 접속이 가능하도록 openssh-server 설치
sudo apt install openssh-server
호스트 이름 변경
노트북 8대를
client, namenode, secondnode, datanode1, datanode2, datanode3, datanode4, datanode5 설정
sudo hostnamectl set-hostname client
sudo hostnamectl set-hostname namenode
sudo hostnamectl set-hostname secondnode
sudo hostnamectl set-hostname datanode1
sudo hostnamectl set-hostname datanode2
sudo hostnamectl set-hostname datanode3
sudo hostnamectl set-hostname datanode4
sudo hostnamectl set-hostname datanode5
root계정으로 hadoop 계정 권한 설정
sudo visudo 명령은 리눅스 시스템에서 /etc/sudoers 파일을 수정하기 위해 사용되는 명령
sudo visudo
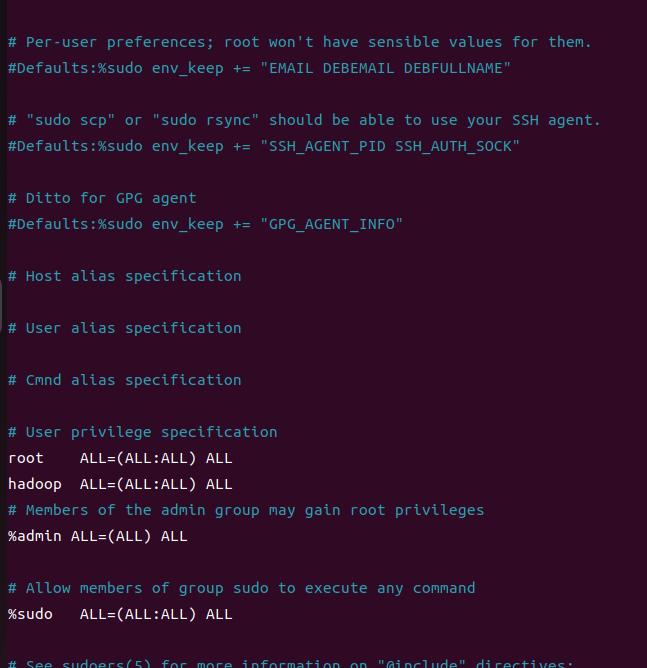
root 밑에 hadoop 계정 추가해주기
계정을 추가하면 sudo 명령어를 사용할 수 있게 됨
방화벽 해제
방화벽을 해제하여 서로 연결하는데 방해요소가 없도록 설정
sudo apt install ufw 방화벽 설치
sudo systemctl stop ufw 방화벽 멈추기
sudo systemctl status ufw 방화벽 상태 확인
Ip 고정 설정
노트북에 전부 랜선을 꽂을 환경이 되지 않아 Wi-Fi로 접속하였고,
서로 지속적으로 통신을 해야 되기 때문에 IP주소를 고정하였다.
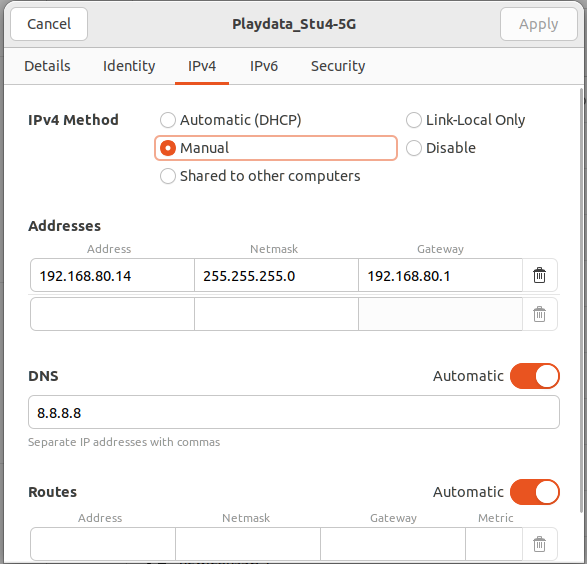
노드 간 통신 설정
퍼블릭 키를 authorized_keys에 적어 scp 명령어를 통해 모든 노드에 복사
권한 설정을 하여 서로 ssh를 통해 접속 가능하게 설정
cd ~/.ssh .ssh로 이동
cat id_rsa.pub >> authorized_keys authorized_keys에 노트북 7대에 퍼블릭 키를 받아 작성
chmod 600 ./authorized_keys 소유자에게만 읽기,쓰기 권한 부여
scp ./authorized_keys client:/home/hadoop/.ssh/
scp ./authorized_keys namenode:/home/hadoop/.ssh/
scp ./authorized_keys secondnode:/home/hadoop/.ssh/
scp ./authorized_keys datanode1:/home/hadoop/.ssh/
scp ./authorized_keys datanode2:/home/hadoop/.ssh/
scp ./authorized_keys datanode3:/home/hadoop/.ssh/
scp ./authorized_keys datanode4:/home/hadoop/.ssh/
scp ./authorized_keys datanode5:/home/hadoop/.ssh/
7대에 퍼블릭 키를 모아둔 파일을 모든 노드에 복사
위의 명령어를 이용하여 모든 노드에서 키 공유
sudo apt install vim vim 설치
vim /etc/hosts host 파일 수정
192.168.80.14 datanode1
192.168.80.150 datanode2
192.168.80.169 datanode3
192.168.80.160 datanode4
192.168.80.155 datanode5
192.168.80.170 client
192.168.80.4 namenode
192.168.80.28 secondnode
↑ 추가
ssh를 통해 모든 컴퓨터에 접속 가능
ssh client
ssh namenode
ssh secondnode
ssh datanode1
ssh datanode2
ssh datanode3
ssh datanode4
ssh datanode5
JAVA 설치 (open jdk 1.8.0)
하둡이 자바로 구성돼있기 때문에 java 설치
sudo apt-get update
sudo apt-get install openjdk-8-jdk
java -version 버전 확인
JAVA_HOME 설정
readlink -f $(which java) JAVA가 설치된 경로 확인
sudo vi /etc/profile profile 편집 // .bashrc에 설정해도 된다.
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64 자바 홈 경로 추가
export PATH=$PATH:$JAVA_HOME/bin 경로 지정
:$JAVA_HOME/bin의미 : 기존 PATH에 JAVA_HOME을 추가- $PATH를 제외 하고 입력할 시에 PATH가 JAVA_HOME만 남기 때문에 JAVA는 이상이 없지만 다른 명령어는 먹히지 않음
.bashrc와 .profile의 차이점
- .bashrc : 터미널에서 실행될 때마다 실행되는 파일로서, 새로운 쉘을 시작할 때마다 사용자의 환경을 설정. 사용자의 특정 프로그램에 관한 환경 변수를 정의하거나 에일리어스(Alias; 단축 명령어)를 설정하는 등의 작업을 수행. 이 파일은 로그인이 아닌 쉘에서 실행됩니다.
- .profile : 사용자가 로그인할 때 실행되는 파일. 로그인 쉘에서만 실행되며, 사용자의 환경을 설정하는 중요한 파일. 이 파일에서는 PATH 환경변수를 정의하거나, PS1환경 변수를 설정하고, 로그인 후 실행해야 할 명령어를 작성할 수 있음
일반적으로 .profile 파일은 종료되면 재시작해야하는 작업을 수행하는 것과 같은 시스템 전체의 기본적인 설정을 정의하고, .bashrc 파일은 로그인 후 사용자가 사용 가능한 작업을 정의하는 데 사용됩니다.
miniconda 설치
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh 미니콘다 설치(wget)
sh ./Miniconda3-latest-Linux-x86_64.sh 쉘스크립트 설치 파일 실행
source ~/.bashrc 적용

Hadoop 설치
hadoop 계정 cd ~에서
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz 하둡 파일 다운로드
tar xzf hadoop-3.2.1.tar.gz hadoop tar 파일 압축 해제
mv ./hadoop-3.2.1 ./hadoop 파일명 hadoop으로 변경
하둡 설정
hadoop의 conf 디렉토리에 있는 파일들을 수정하였다.
아래 파일들을 설정했다.
cd ~에서 다른 노트북에도 hadoop 설치를 위해 파일 scp를 이용해 복사
scp -r ./hadoop namenode:/home/hadoop/
- 쉘 스크립트 만들어보기
- 여러 노드에 명령어를 계속치지 않으려 쉘 스크립트로 만들어 보았다. (feat. chatGPT)
#!/bin/bash
local_directory="./hadoop" # 로컬 디렉토리 경로
remote_hosts=("datanode2" "datanode3" "datanode4" "datanode5" "client" "namenode" "secondnode") # 원격 호스트 이름 > 목록
remote_directory="/home/hadoop/" # 원격 디렉토리 경로
for host in "${remote_hosts[@]}"; do
scp -r "$local_directory" "$host:$remote_directory"
done한개의 파일에 경우는 scp로 만으로도 복사가 되지만,
대량의 파일을 전송할 경우에는 -r 옵션을 사용해야 함
추후 진행할 작업
- pyspark 설치
- jupyter 설치
- HDFS에 데이터 업로드
