Drop-out(드롭아웃)
개념
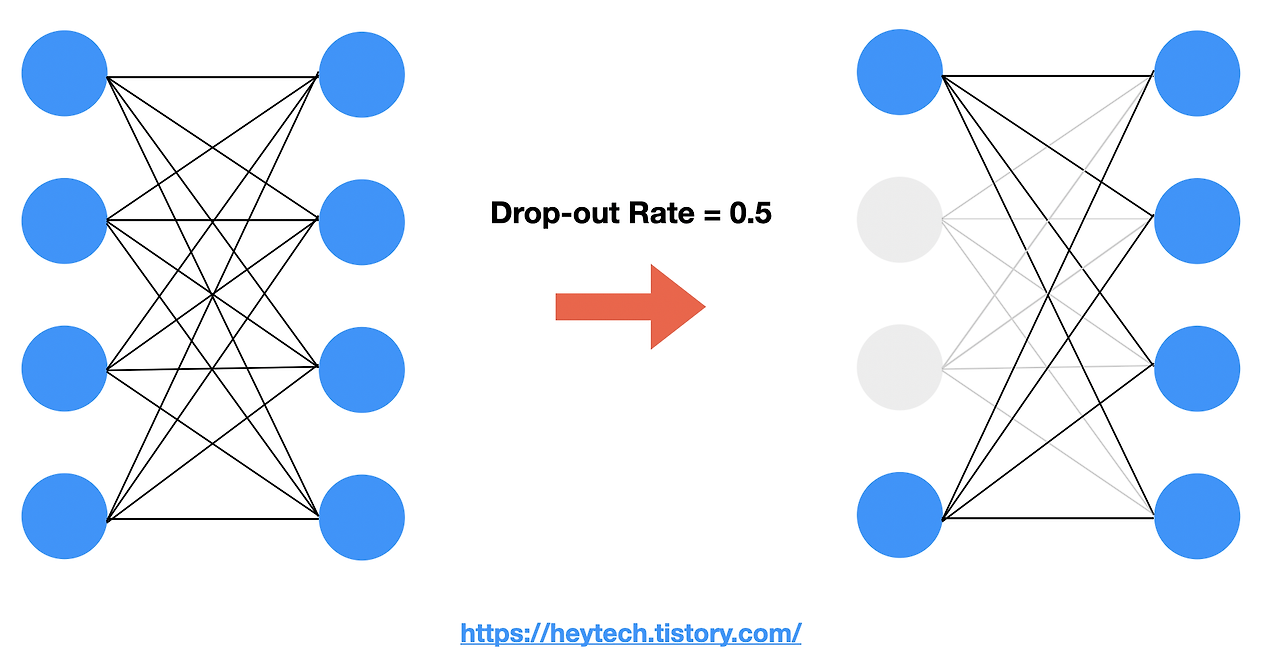
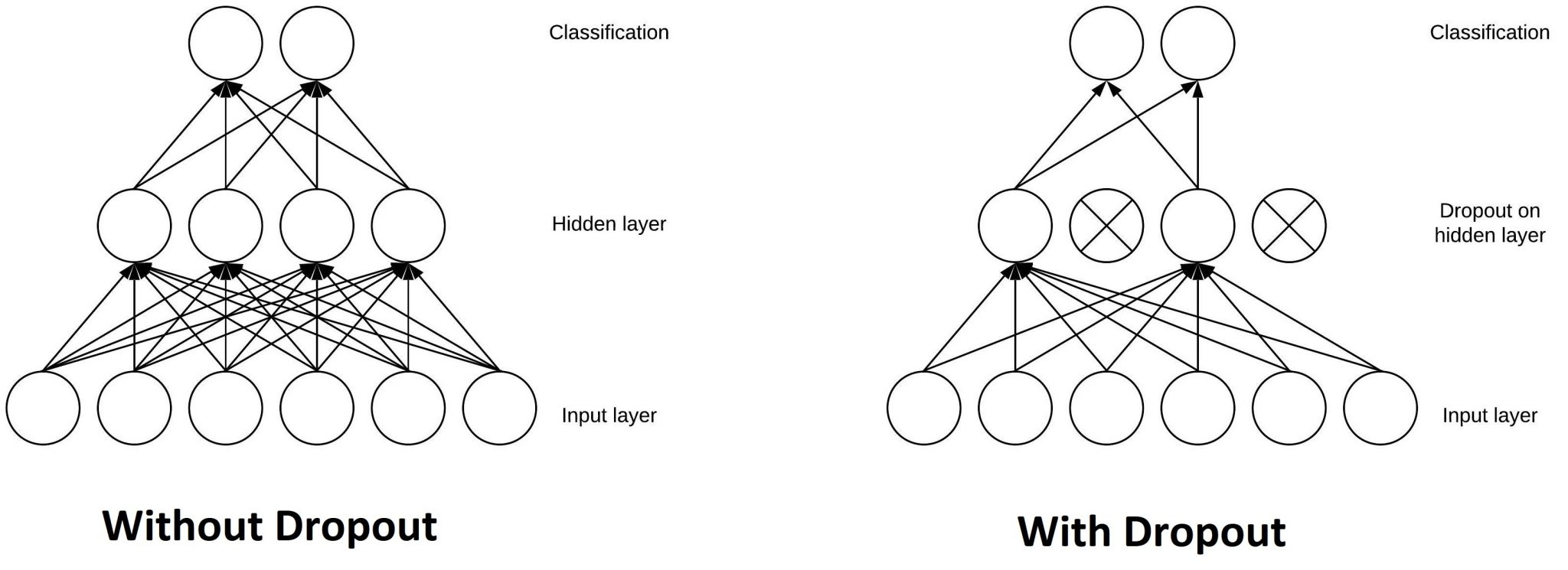
- 훈련(Training)중에 서로 다른 연결망(layer)에서 0~1사이의 확률로 뉴런을 제거하는 기법이다. 사진과 같이 모든 뉴런끼리 연결되어 있는 전결합 계층(Fully Connected Layer)에서 hidden layer에서 주어진 확률로 제거될지 말지 결정된다. Drop-out Rate는 하이퍼파라미터이며 일반적으로 0.5로 설정한다.
사용 목적
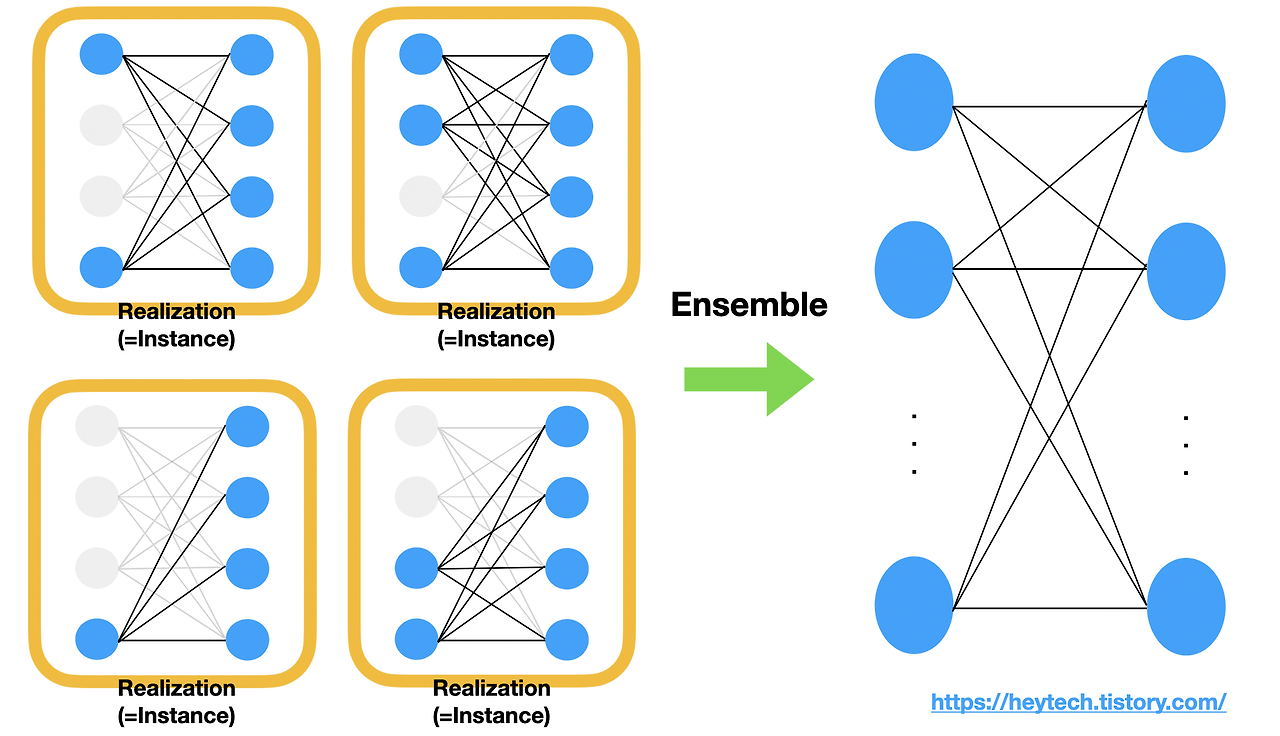
- 특정한 설명변수 Feature만을 과도하게 집중하여 학습함으로써 발생할 수 있는 과대적합(Overfitting)을 방지하기 위해 사용된다. Drop-out이 적용된 전결합계층을 하나의 Realization(=Instance)라고 한다. 각 realization이 일부 뉴런만으로 좋은 출력값을 제공할 수 있도록 최적화 되었을 때, 각각의 여러 출력값에 평균을 취하면(=Ensemble) 모든 뉴런을 사용한 전결합계층의 출력값을 얻을 수 있습니다. 이 출력값은 편향되지 않은 출력값을 얻는데 효과적이다.
- 어느 특정 Feature가 어떤 출력값에 가장 큰 상관관계가 있다고 가정해보자. Drop-out을 적용하지 않고 모델을 학습하면 해당 Feature에 가중치가 가장 크게 설정되어 나머지 Feature에 대해서는 제대로 학습하지 않는다.
- 앙상블 효과 : 학습 중 각 드롭아웃 구성은 고유한 하위 신경망으로 볼 수 있다. 테스트 시 모델이 모든 뉴런을 사용하므로 효과가 발생하여 여러 하위 네트워크의 예측을 효과적으로 일반화한다. 모델의 예측력을 향상 시킴
- 노이즈 주입 : 드롭 아웃의 확률론적 특성은 학습 과정에 노이즈를 주입한다. 이 노이즈는 정규화 역할을 하여 모델이 훈련 데이터에 너무 가깝게 피팅되는 것을 방지하고 노이즈가 마치 신호인 것처럼 처리한다.
작동 방식
1.Training(순전파)
- self.mask에 삭제할 뉴런을 False로 표시
- self.mask는 x와 형상이 같은 배열을 무작위로 생성하고, 그 값이 dropout_ratio보다 큰 원소만 True로 설정함
- Training(역전파)
- ReLU와 같은 동작 방식으로 순전파 때 신호를 통과시키는 뉴런은 역전파 때도 신호를 그대로 통과함
- 순전파 때 통과시키지 않은 뉴런은 역전파 때도 신호를 차단
- Testing(평가)
- 테스트 때는 모든 뉴런에 신호를 전달
- 단, 시험 때는 각 뉴런의 출력에 훈련 때 삭제한 비율을 곱하여 출력
- drop_ratio(삭제 비율) 0.5 였다면 0.5를 곱함으로써 앙상블에서 여러 모델의 평균을 내는 효과
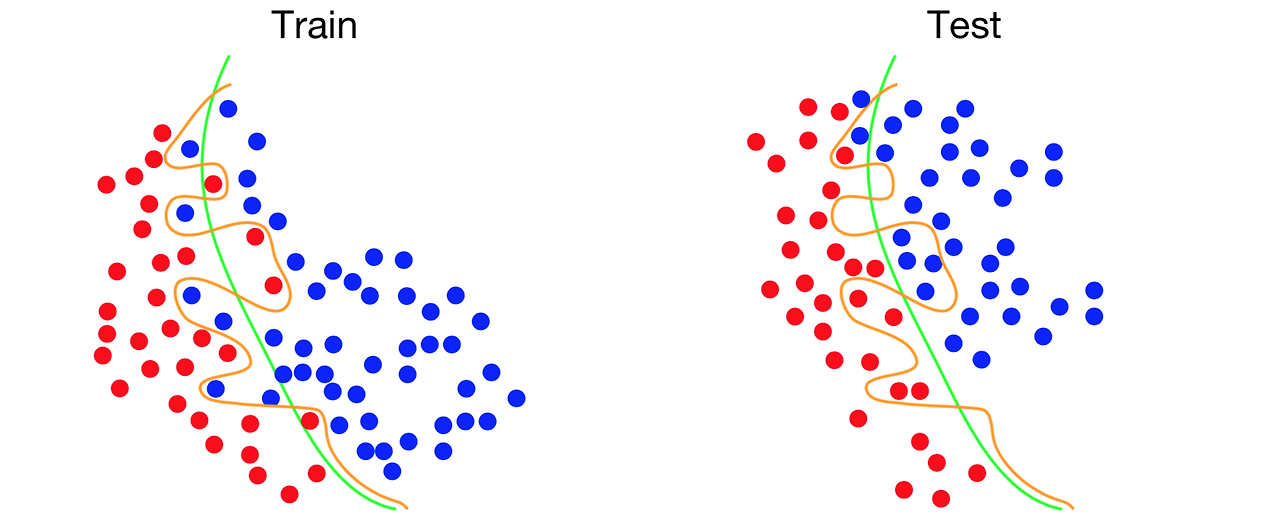
- 주황색 선은 Train에서는 정확도가 100%, Test 에서는 오류가 난다.
- Train set에서는 한 번도 보지 못한 데이터가 있을 수 있기 때문에, train set에 집중하게 되면 실제로 분류햇을 땐 오분류가 나타나 성능이 좋지 않을 수 있다.
- Training 에서 뉴런을 무작위로 삭제하는 행위를 매번 다른 모델을 학습시키는 것으로 해석할 수 있다. 이는 앙상블 학습과 같은 효과를 낸다.
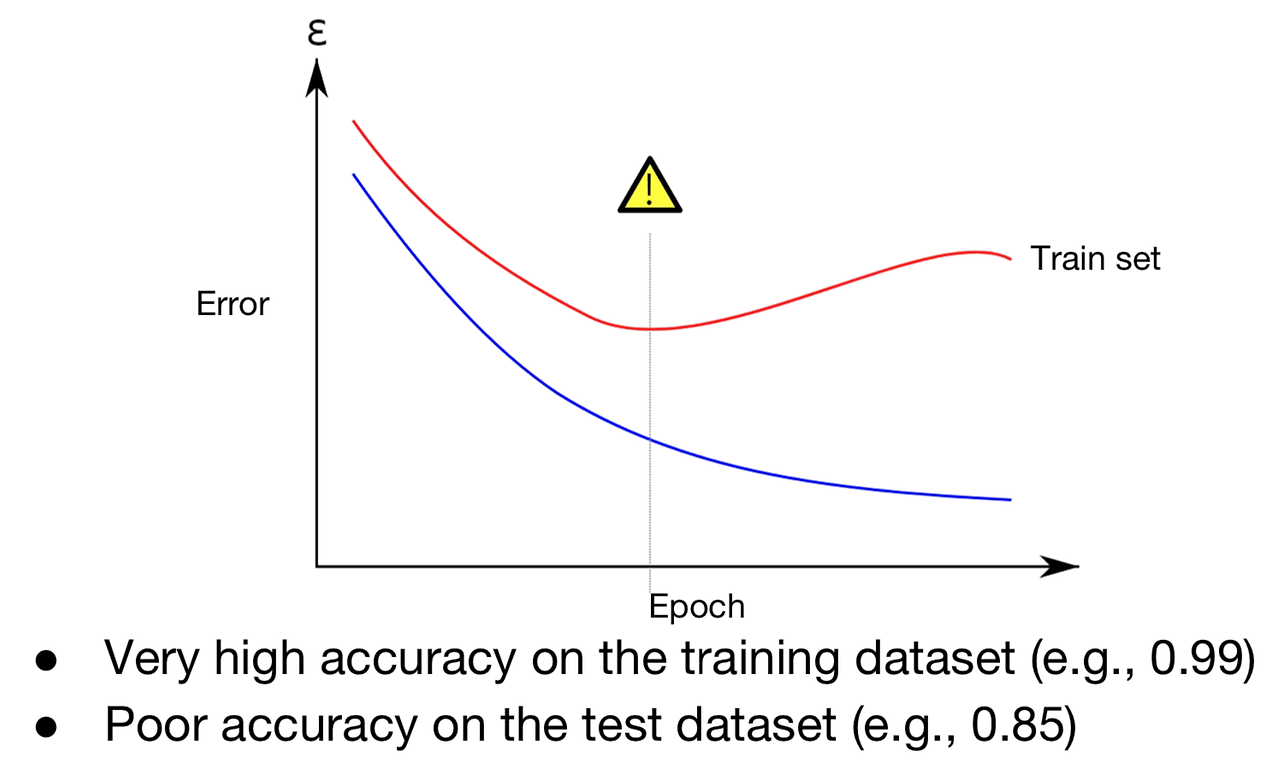
- Train set에서는 정확도가 매우 낮지만, 실제 환경인 test set에서는 정확도는 낮고, 오류율은 증가하게 된다. 이러한 문제가 overfitting 문제이다.
주의할 점
- Dropout-ratio
- 무작위로 탈락되는 뉴런의 비율이다. 일반적으로 약 0.2~0.5에서 시작하는 것이 좋다. 탈락률이 너무 낮으면 과적합을 효과적으로 방지할 수 없고, 너무 높으면 학습을 방해한다.
- Dropout 위치
- 신경망의 계층에 다양하게 배치할 수 있다. 원칙상 히든 레이어에 드롭아웃을 적용한다. 최근 연구에서는 입력과 출력 레이어에도 사용을 검토한다. 입력 레이어에 적용하면 랜덤포레스트의 bagging 과 같은 효과가 있다. 신경망 아키텍처와 복잡성에 따라 달라질거 같다.
결론
- 과적합을 막기 위한 정규화 기법 중에 하나이다. CV에서는 충분한 데이터가 부족하기 때문에 거의 대부분 과적합니 일어나지만, 신경망이 Overfitting 문제가 없으면 드롭아웃을 사용하지 않아도 된다.
Learning rate(학습률)
개념
- 모델이 학습을 진행할 때 각각의 가중치(weight)를 얼마나 업데이트할지 결정하는 하이퍼파라미터 이다. 학습률은 매개변수 업데이트 시의 크기를 조절하여 모델이 적절한 방향으로 수렴할 수 있도록 도와준다.
그림 출처
Hey Tech, https://heytech.tistory.com/127, 2021.08. 10
We gonna make it, https://wegonnamakeit.tistory.com/46, 2020. 02. 09
