Q1. t-test란?
t-test는 두 집단 간의 평균을 비교하여 두 집단 간의 차이가 통계적으로 유의미한지를 평가하는 통계적 검정방법이다. 세 가지 경우가 있는데 하나는 독립포본 t-test(Independent t-test)이고, 하나는 대응표본 t-test(Paired t-test)이고 나머지 하나는 단일 표본 t-test(One Sample t-test)이다.
1. 독립포본 t-test(Independent t-test)
- 두 개의 독립된 집단의 평균 비교
- ex) 새로운 학습 방법이 학생들의 성적에 미치는 영향(기존 vs 새로운 학습 방법)
2. 대응표본 t-test(Paired t-test)
- 동일한 집단에서 두 번 측정된 평균을 비교
- ex) 다이어트 프로그램에 전후의 체중 비교
3. 단일 표본 t-test(One Sample t-test)
- 하나의 표본 평균과 알려진 모집단 평균 비교
- ex) 특정 지역 학생들의 평균 수학 점수가 전국 평균과 다른지 확인.
4. t-test 수행 단계
- 가설 설정
- 귀무가설(H0) : 두 집단의 평균에 차이가 없다. 즉, 두 집단의 평균이 동일하다.
- 대립가설(H1) : 두 집단의 평균에 차이가 잇다. 즉, 두 집단의 평균이 다르다.
- 유의수준 설정
- '귀무가설이 참임에도 불구하고 귀무가설을 기각할 확률' 을 의미
- 5%의 오류를 감수하고 결론을 내리겠다는 의미
- ex) 5%의 확률로 두 집단의 평균 차이가 우연에 의해 발생했다고 판단할 수 있는 오류를 허용
- 통계량 계산
- t-값(t-statistic) 은 두 집단의 평균 차이가 표준 오차(Standard Error)의 몇 배인지를 나타낸다. 이를 계산하기 위해선 각 집단의 평균과 표준 편차를 사용하여 t-값 계산
- ex) 두 집단의 평균 성적이 각각 75점과 80점, 표준편차가 10고 12이며, 각 집단의 크기가 30이라면, t-값을 계산하여 평균 차이가 있는지를 평가할 수 있다.
- p-value 계산 및 해석
- p-value 란 t-값이 나타날 확률을 의미하며, 이를 통해 귀무 가설을 기각할지를 결정한다.
- p-val < α(0.05) : 귀무가설 기각. 두 집단의 평균 차이가 통계적으로 유의미
- p-val < α(0.05) : 귀무가설 기각x. 두 집단의 평균 차이가 통계적으로 무의미
결론 - t-test 를 수행하여, 두 집단 간의 차이가 통계적으로 유의미한지 판단할 수 있다.
Q2. 사분위수란?
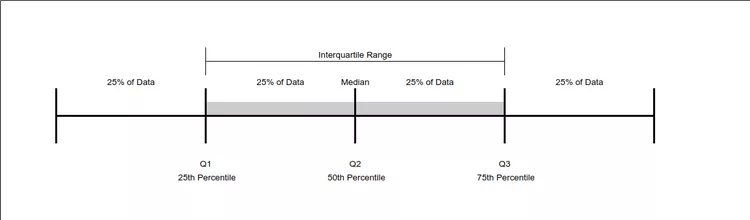
- 사분위수(Quartile)은 측정값을 낮은 순에서 높은 순으로 정렬한 후 4등분 했을 때 각 등위에 해당하는 값을 의미하는데, 보통 1/4분위수(First quantile) 와 3/4분위수(Thrid quantile)를 가장 많이 사용한다.
- 평균(mean), 중앙값(median), 분산(variance), 표준편차(standard deviation), 표준오차(standard error) 를 집단에서 측정된 수치의 특성을 나타낸다.
- 1사분위 수(Q1)와 3사분위 수(Q3)를 찾고, IQR(Q3-Q1)를 구한다. Interquartile rance를 벗어난 값들을 이상치로 판단하고 제거해준다.
Q1 = df['price'].quantile(0.25)
Q3 = df['price'].quantile(0.75)
IQR = Q3 - Q1
lower_fence = Q1 - 1.5 * IQR
upper_fence = Q3 + 1.5 * IQR
condition1 = df['price'] >= lower_fence
condition2 = df['price'] <= upper_fence
df = df[condition1 & condition2]- 참고로 이상치를 제거하는 방법에는 평균과 표준편차를 이용한 Z-score 방법이 있다.(정규분포를 따른다는 가정)
- 데이터 포인터들의 평균과 표준편차를 구한다.
- 각 데이터 포인터트의 Z-score를 구한다. Z-score는 데이터 포인트가 평균과의 거리가 몇 sigma 범위에 있는지를 의미한다.
- Z-score가 특정 threshold(일반적으로 3) 이상인 값들은 이상치로 판단하고 제거한다.
Q3. 기술통계 vs 추론통계
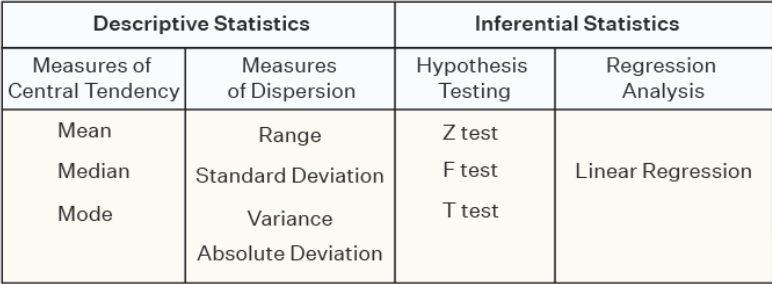
1. 기술통계(Descriptive Statistics)
- 데이터의 간결한 요약 정보 제공
- 수치적 or 시각적으로 데이터를 요약한다. 예를 들어, 학교에서 100명의 학생 성적 데이터를 수집. 이를 통해 학생의 평균, 중앙값, 표준편차 등을 계산한다. 데이터의 일반적인 경향이나 분포를 요약하여 보여줄 수 있다.
2. 추론통계(Inferential Statistics)
- 모집단에 대한 추론을 하기 위해서 모집단으로부터 추출한 샘플 사용
- 전체 모집단의 모든 인원을 조사할 수 없을 때 유용하다. 예를 들어, 선거 여론조사를 실시하여 1000명을 대상으로 특정 후보의 지지율이 52%라는 지지율이 나왔다고 가정. 이 결과를 바탕으로 해당 지역 전체 유권자(10만명)의 지지율이 50% 이상일 것이라고 추론. 이 과정에서 표본을 사용하여 전체 모집단에 대한 결론을 내리는 것이 추론통계의 대표적인 예이다.
- 귀무가설, 대립가설을 판단하는 기준은 검정통계량과 p-value 통해서 진행
-- 귀무가설
-- 대립가설
결론
- 기술통계(Descriptive Statistics)는 데이터 자체를 요약하여 보여주는 통계 방법으로, 평균, 중앙값, 표준편차 등과 같은 통계량을 통해 데이터의 일반적인 경향을 설명한다. 추론통계(Inferential Statistics)는 표본 데이터를 사용하여 전체 모집단에 대한 결론을 내리는 통계 방법으로, 가설 검정이나 신뢰 구간을 통해 결론을 도출한다.
Q4. 제1종 오류 vs 제2종 오류
우리는 자료를 수집하고 데이터를 바탕으로 어떠한 사안에 대해서 결정을한다. 하지만 데이터를 가지고 항상 옳은 결정을 하는 것은 불가능하기에 가장 오류가 최소화하는데 목적을 갖고있다. 우리가 수집한 자료는 모집단에서 추출한 표본이기 때문에 항상 오류의 가능성이있다.
그 전에 귀무가설과 대립가설에 대해서 이해가 필요하다.
H0 : 귀무가설(Null Hypothesis) - 대립가설과 상반되는 가설(효과가 없다, 차이가 없다, 서로 다르지 않다)
H1 : 대립가설(Alternative Hypothesis) - 확인하고 싶은 연구와 관심의 대상이 되는 가설(효과가 있다, 차이가 있다, 서로 다르다)
통계적 오류에는 1종 오류와 2종 오류 이렇게 두 가지가 있다.
상황 : 한 학교에서 새로운 교육 프로그램이 학생들의 수학 시험 점수를 향상시킬 수 있는지 확인해보고자 한다.
귀무가설(H0) : 새로운 교육 프로그램을 받은 학생들의 평균 점수는 기존 프로그램을 받은 학생들의 평균 점수와 같다.
대립가설(H1) : 새로운 교육 프로그램을 받은 학생들의 평균 점수는 기존 프로그램을 받은 학생들의 평균 점수보다 높다.

1. 제1종 오류 (Type I Error)
귀무가설(H0)이 실제로 참인데도 불구하고 이를 기각하는 오류를 의미한다. 이는 통계적으로 유의한 차이가 없는 경우에도 귀무가설을 잘못 기각하여, 마치 차이가 있는 것처럼 결론을 내리는 상황이다.
예시 : 새로운 약물이 기존 약물보다 효과가 없는데, 실험 결과로 인해 이 새로운 약물이 더 효과가 있다고 결론을 내리는 경우.
확률 : 제 1종 오류의 발생 확률은 유의수준(α)으로 나타내며, 보통 0.05(5%)로 설정하는 경우가 많다. 이는 귀무 가설이 참일 때 5%의 확률로 잘못된 결론을 내릴 수 있음을 의미.
2. 제2종 오류 (Type II Error)
귀무가설이 거짓인데도 불구하고 이를 기각하지 않는 오류를 의미합니다. 즉, 실제로 대립가설이 참이지만, 귀무가설을 기각하지 못해 차이가 없는 것으로 결론을 내리는 상황이다.
예시 : 새로운 약물이 기존 약물보다 효과가 있는데, 실험 결과로 인해 이 새로운 약물이 효과가 없다고 결론을 내리는 경우.
확률 : 제 2종 오류의 발생은 확률은 β로 나타내며, 이 값이 클수록 제2종 오류를 범할 가능성이 높아집니다. 제2종 오류를 줄이기 위해서는 표본 크기를 늘리거나, 실험 설계를 개선할 필요가 있음
Q5. p-value 란?
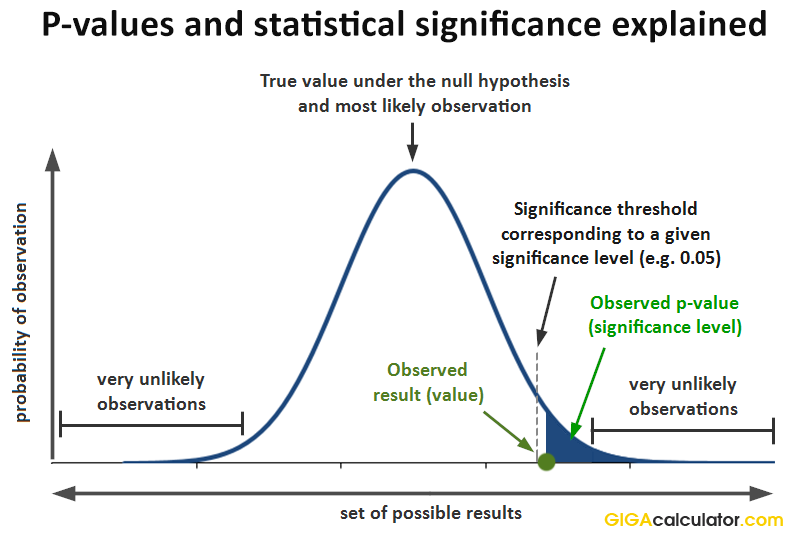
P-value 란 간단히 말해서 어떤 사건이 우연히 발생할 확률이다. 앞서 말햇던 것처럼 통계적 가설 검정은 모집단의 일부인 표본의 통계량을 사용하는 과정이기 때문에 확률적 오류가 발생할 수 밖에 없다. 귀무가설을 기각할 수 있는지를 판단하기 위해, 가설검정에 있어 귀무가설의 채택/기각 중 하나를 결정할 때 오류에 대한 내용이 있어야 하는데 이 때 P-value 는 를 사용한다.
예를 들어, p값이 0.05보다 작으면 우연히 일어날 확률이 5%보다 작다라는 의미이다. 이 뜻은 사건이 우연히 일어날 가능성이 거의 없다는 것과 같다.
상황 : 한 연구자가 새로운 다이어트 프로그램이 체중 감량에 효과가 있는지를 테스트한다. 실험군과 대조군의 체중변화 비교
귀무가설(H0) : 다이어트 프로그램은 체중 감량에 효과가 없다. (두 그룹간의 체중 변화에 차이가 없다.)
대립가설(H1) : 다이어트 프로그램은 체중 감량에 효과가 있다. (두 그룹간의 체중 변화에 차이가 있다.)
결론 : 실험군들의 체중 감소량이 더 컸다. 통계적 검증을 통해 p-value = 0.03. 설정된 유의수준(0.05) 보다 작기 때문에 귀무가설을 기각하고 대립가설을 채택할 수 있다. 즉, 다이어트 프로그램이 체중 감량에 효과가 있다고 결론.
Q6. high-dimensional clustering 문제 해결 방법
데이터 간의 유사도를 계산할 때, feature의 수가 많다면(예: 100개 이상) 어떻게 해결해야할까?
1. 차원축소
-
주성분 분석을 통해 데이터의 분산을 최대한 보존하면서 주요 성분을 추출하여 차원을 축소한다.
-
고차원 데이터를 저차원으로 변환하여 데이터의 군집 구조를 시각화하는 데 유용하다.
-
비선형 차원 축소 기법
-
밀도 기반 클러스터링 기법
- DBSCAN : 밀도 차이를 기반으로 클러스터를 형성하여 비선형적이고 복잡한 데이터 구조를 효과적으로 처리한다.- Spectral Clustering : 그래프 라플라시안의 고유벡터를 사용하여 데이터의 비선형 구조를 반영하는 클러스터링을 수행
