

작년 이전 직장에서 CV팀에서 D* 보험회사에 보험서류 위조 판별 모델, PoC데이터(실제 환경에 적용하기 전에 유효성 검증하는 과정)를 다루며 납품할 당시 우리 업무와 같은 일을 한다고 하며 들어본 회사이다. CV 쪽에서 굉장히 성과를 많이 내는 곳이기도 하고 Solar pro 모델 출시와 더불어 앞으로가 더 기대되는 회사여서 이전부터 굉장히 관심있게 보고 있엇으며, 과연 내가 갈 수 있을까 하는 속앓이를 하며 있다가 이렇게 연락이 오게되어 기분이 매우 좋았다. 인터뷰 직전에 이 회사에 대해 조금 더 알아보기 위해 정리해 보았다.
업스테이지
AI 기술을 활용하여 비즈니스 문제를 해결하는 데 주력하는 회사로, 복잡한 의사결정 지원 및 비용 절감을 통해 기업의 생산성을 향상시키는 AI 솔루션 개발에 주력. 이를 통해 업무 처리 방식을 혁신하고 기업들이 더 효율적으로 성장하도록 지원. 특히 Document AI를 포함한 다양한 API 시리즈를 통해 고객사의 비즈니스 성공에 기여함.
Technical Program Manager (TPM)
기술적 전문성을 기반으로 프로젝트 및 프로그램 관리 담당을 한다. 엔지니어링 팀, 제품 팀, 비즈니스 이해관계자들 사이의 다리 역할을 하면서, 제품 발전 방향성에 맞게 프로젝트들을 조율하고 관리한다.
조직의 목표 달성을 위해 필요한 기술적, 운영적 조율 담당. 회사의 방향성과 프로젝트의 방향성이 일치하도록 역할 수행
- 장·단기 목표 정의 및 로드맵 수립
- 프로젝트 관리 및 운영
- 내외부 팀 간 협업 및 커뮤니케이션
- 문제 해결
- 비용 관리 및 ROI 분석 : 프로젝트의 비용 효율성을 분석하고 ROI를 최적화하는 전략 수립
OCR 기술이란?
✅ OCR은 필기 문서, 활자 인쇄물 등을 디지터 이미지 파일로 변환하고 다시 이미지를 텍스트로 변환하는 SW를 총칭한다.
OCR 기술의 중요성
- 디지털화
- 경제성 : 종이 문서, 활자 인쇄물은 생산과 관리에 많은 시간과 노력을 요구하지만 OCR 사무자동화는 사무 인력 인건비 등 기업의 비용 절감에 기여
- 효율성 : OCR 사무자동화는 신속성과 안전성으로 업무 전반의 효율성을 높여준다.
OCR 활용 분야
1. 기업의 사무 자동화
2. 교육 분야
3. 의료 분야
✅ 이 분야는 이전 직장에서 약간의 경험이 있다. 보험 서류의 위조 방지를 위해 대규모 라벨링을 직접하여 보험금 지급 등의 환자 기록을 처리하는데, 데이터의 정확도도 증가시키고 중요 문서를 전달하는 과정에서의 오류 가능성을 줄인다.
4. 금융 분야
- 입금된 환급 또는 수표에 대한 확인
- 은행 업무를 위한 신분증, 등기권리증, 인감증명서 등 각종 서류를 자동 인식하고 정보를 처리
업스테이지의 OCR
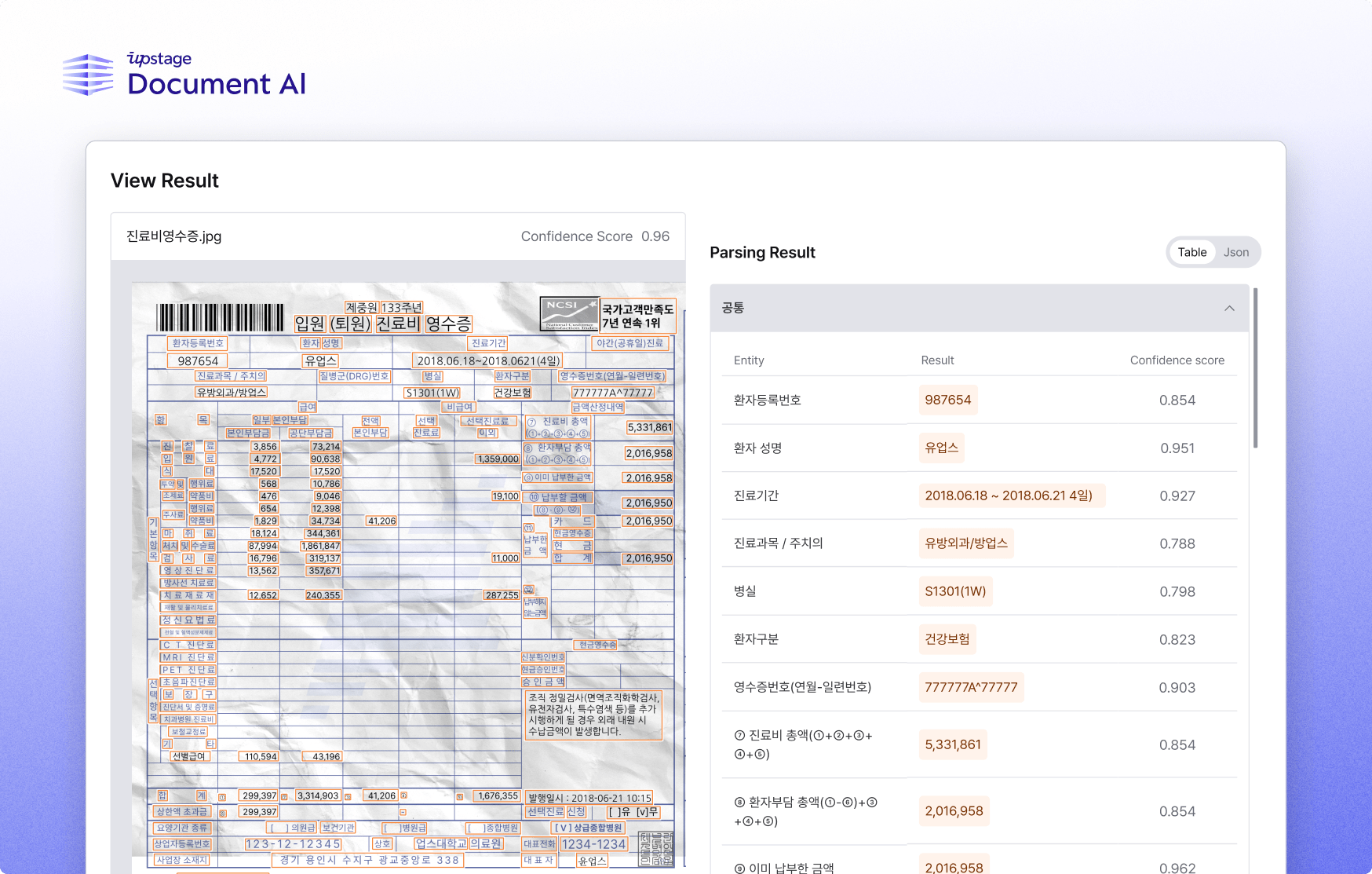
- 삼성생명에 공급한 금융 특화 AI 광학문자인식(OCR) 솔루션(Document AI)이 업계 1위의 정확도 달성
- 한화생명에 OCR Pack 공급 계약 체결.
- 기울어진 각도나 구겨김, 음영 등 다양한 이미지 형태의 문서에서 글자 및 정보를 추출해 디지털 해주는 토탈 AI 솔루션
- 진료비 영수증의 경우 병원마다 문서 양식이 천차만별이고, 손글씨 등 비정형 데이터가 포함돼 고난도 인식 기술
- API 형태로 클라우드에서 손쉽게 사용할 수 있는 Personal 과 기업 요구사항에 따라 도메인 맞춤형 인터페이스를 제공하는 Enterprise 등 2가지 방식 지원
Recsys Pack 이란?
✅ 업스테이지에서 개발한 추천 시스템 관련 기술 패키지. 일반적으로 사용자의 행동, 기호, 구매 패턴 등 다양한 데이터를 기반으로 최적의 상품이나 서비스를 추천해 주는 시스템을 포함한다. 실제 상업 환경에서 Recsys Pack을 테스트하며 해당기술이 브랜디의 플랫폼에 맞게 잘 작동하고, 사용자에게 맞춤형 추천을 제공하여 고객 만족도를 높이고, 결과적으로 판매 증진에 기여할 수 있는지 확인하는 것
업스테이지의 Recsys Pack
- 데이터를 기반으로 초개인화된 데품 추천 솔루션 등 추천팩 개발
- 시간 단축과 표준화된 서빙 제공, 요구사항을 만족하면서 브랜디에만 쓰이는 게 아니라, 다양한 고객사에도 추천 시스템을 제공할 수 있는 틀2
브랜디와의 협업
- 브랜디의 매출 지표에 적합한 추천을 진행. 매출, 클릭 등의 여러 지표에서 기존의 타 추천 시스템보다 우수한 성능을 입증했고 자연스레 계약까지 이어지게 됨
- 앱의 홈 지면에 개인화 AI 추천 형태로 적용되고 있다. 업스테이지의 추천 AI Pack 적용 후 효과는 총 노출 당 구매전환액이 해당 사업 시작하기 전 대비해서 60% 가까이 증가.
- 추천 시스템을 도입하려는 회사들의 고민
- 어떤 것부터 해야할지? 무엇을 최적화해야 하는지? 우리 서비스의 중요한 지표가 무엇인지?
- "노출 당 구매 전환 금액에 대한 멀티터치 어트리뷰션 최대화"
브랜디의 목표 달성 시키기(노출 당 구매 전환 금액 최대화)
- CTR은 높고 CVR은 낮을 때
- 유입된 클릭률은 높고, 전환율이 낮다면 전환 목표를 달성하지 않고 이탈하는 사용자가 많음을 유추
- 유입된 사용자가 우리의 목표 타겟층이 아닐 가능성이 있거나 광고 노출 타겟, 지면 등을 점검 혹은 노출 중인 광고와 랜딩페이지가 일치하지 않거나, 전환 목표인 회원가입, 결제단계, 설치과정이 복잡하거나 원활하지 않다거나 하는 등의 유입 이후의 문제점
- 광고와 실제 랜딩페이지 그리고 전환 목표에 이르기까지 필요한 사용자 액션을 하나하나 점검하고 개선시켜 CVR dmf shvdlsek.
- CTR은 낮고 CVR이 높을 때
- 광고를 통해 유입된 사용자 수가 상대적으로 적지만, 유입된 사용자의 대부분이 전환 액션을 취한다고 유추
- 타겟층에 변화를 주기보다 조금 더 효율적이고, 적합한 노출 지면을 찾는 시도를 하여 노출 수 증가
- 만약 노출 지면에 큰 이상이 없다면, 선정된 타겟층의 모수가 너무 적은 문제일 수도 있으므로 타겟층에 조금씩 변화를 주는 것도 방법
Solar Pro란?

✅ 지난 9월 11일 업스테이지가 개발한 자체 사전학습 거대모델(LLM) 솔라(Solar)
Solar-pro-preview, solar-pro-preview-instruct가 오픈소스 모델로 출시 되엇다. 처음으로 공개했던 모델 Solar 10.7B 보다 2배 이상 큰 파라미터 수(22.1B)를 가지고 있으며, 단일 GPU에서 효율적으로 실행할 수 있다.
모델링 코드
model = AutoModelForCausalLM.from_pretrained(
"upstage/solar-pro-preview-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)- 기존 트랜스포머 라이브러리의 모델 클래스를 사용하지 않고, SolarForCasualLM 이라는 새로운 아키택쳐를 사용한다.
- Transformers vs SolarForCasualLM
- 사용자 지정 아키텍처를 사용하는 모델은 modeling_{model_name}.py 에 해당 모델의 아키텍처를 정의해서 사용한다. Solar-pro-preview 모델의 아키텍처 또한 허깅페이스 repo에 modeling_solar.py에 정의되어 있다. 각종 config들은 configuration_solar.py 에서 불러와 사용하는 구조이다.
- solar의 model config를 살펴보면, 대부분 llama나 mistral과 비슷한 구조를 가지나, 한 가지 추가된 사항이 있다.
def __init__(
self,
vocab_size=32000,
hidden_size=4096,
intermediate_size=11008,
num_hidden_layers=32,
num_attention_heads=32,
num_key_value_heads=None,
hidden_act="silu",
max_position_embeddings=2048,
initializer_range=0.02,
rms_norm_eps=1e-6,
use_cache=True,
pad_token_id=None,
bos_token_id=1,
eos_token_id=2,
pretraining_tp=1,
tie_word_embeddings=False,
rope_theta=10000.0,
rope_scaling=None,
attention_bias=False,
attention_dropout=0.0,
mlp_bias=False,
sliding_window=2047,
bskcn_1=[12, 20, 32, 44],
bskcn_2=[20, 32],
bskcn_3=[16, 24, 36, 48],
bskcn_4=[28, 40],
bskcn_tv=[0.9,0.8],
**kwargs,
):- SolarConfig 라는 클래스를 초기화할 때, bskcn이라는 리스트 형태의 변수를 선언함
- 1~4번까지는 정수의 리스트, bskcn_tv에는 0.9와 0.8이 들어있는 리스트 형태
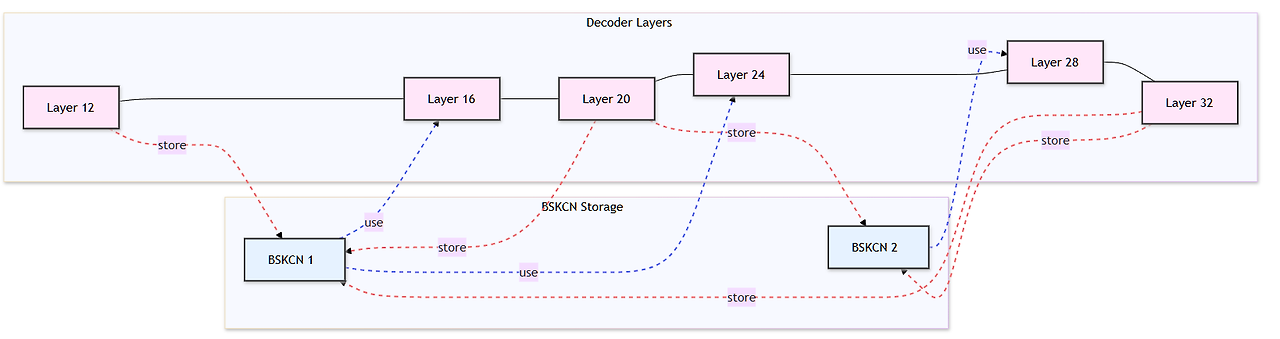
# modeling_solar.py line 1051~
# decoder layers
all_hidden_states = () if output_hidden_states else None
all_self_attns = () if output_attentions else None
next_decoder_cache = None
bskcn_1 = None
bskcn_2 = None
bskcn_tv = self.config.bskcn_tv[0] if self.training else self.config.bskcn_tv[1]
for layer_idx, decoder_layer in enumerate(self.layers):
if layer_idx in self.config.bskcn_1:
bskcn_1 = hidden_states
if layer_idx in self.config.bskcn_2:
bskcn_2 = hidden_states
if layer_idx in self.config.bskcn_3:
hidden_states = (bskcn_1*bskcn_tv).to(hidden_states.device) + hidden_states*(1-bskcn_tv)
if layer_idx in self.config.bskcn_4:
hidden_states = (bskcn_2*bskcn_tv).to(hidden_states.device) + hidden_states*(1-bskcn_tv)- 위 코드는 solar 모델의 decoder 부분 forward 함수의 일부분
https://eda-ai-lab.tistory.com/613
https://blog.naver.com/mars_upstage/223410182396
https://www.upstage.ai/blog/ko/recsys-ai-challenges-interview
