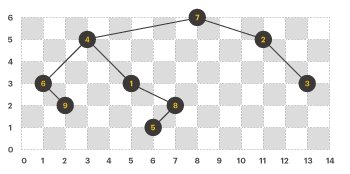
해당 문제는 프로그래머스에서 풀어볼 수 있기에 문제 설명은 생략하겠습니다.
문제 해결 방법
사실 이 문제는 해결 방법을 초기부터 카카오측에서 알려주고 시작을 했습니다.
"이진트리 그래프를 만들고 전위순회 후위순회 해봐" 라는 문제였고 사실 그래프만드는 코드가 조금 까다로울 수 있지만 전위순회, 중위순회, 후위순회는 그래프만 제대로 만들었다면 root 호출 순서에 따라 달라지므로 어렵지 않게 풀 수 있을 것 같았습니다.
이진트리와 preorder, inorder, postorder
이진트리에서 preorder, inorder, postorder 는 순서대로
- 방문 전에 root(top) 노드를 찍는지
- 왼쪽-오른쪽 탐색 중간에 노드를 찍는지
- 탐색 후 노드를 찍는지
위 경우에 따라 나눠 볼 수 있고 코드로 보면 아래처럼 구현이 가능하다.
def findRoot(nodes):
return 루트 노드 인덱스 or 값 등 루트노드를 구분할 수 있는 값을 리턴
def divideNode(nodes, root):
nodes.sort(key=lambda x: x[0])
# nodes 의 root 를 기준으로 왼쪽과 오른쪽으로 나눔
for i, node in enumerate(nodes):
if node[1] == root:
leftNodes, rightNodes = nodes[:i], nodes[i+1:]
return leftNodes, rightNodes
def visitNode(nodes):
nonlocal preorder, postorder
if not nodes: return
root = findRoot(nodes)
leftNodes, rightNodes = divideNode(nodes, root)
preorder.append(root) # 전위순회
visitNode(leftNodes) # 왼쪽노드 탐색
inorder.append(root) # 중위순회
visitNode(rightNodes) # 오른쪽노드 탐색
postorder.append(root) # 후위순회
return이진트리 문제의 기본적인 구조는 위와 같다.
시간복잡도 & recursion depth 계산

문제의 제한사항은 "트리 깊이가 1,000 이하인 경우만 입력으로 주어진다." 라고 되어 있고, nodeinfo 길이도 10,000 이하이므로 시간복잡도는 충분할거라 생각했고 recursion dpeth 도 python 의 기본 recursion depth 의 경우 1,000 으로 문제의 트리 깊이 1,000 을 커버할 수 있는 문제라고 생각했다.
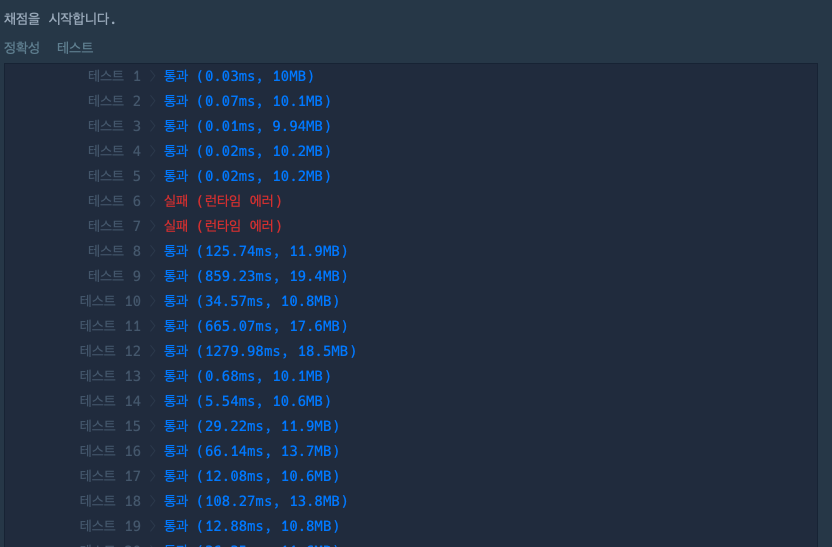
2개의 테스트 케이스가 런타임에러를 뱉었는데 recursion limit error 인 것 같은 느낌을 받았다 실제로 조금 늘려주니 해결되었다.
크게 늘릴 필요도 없이 1010 까지만 늘려줘도 통과가 됐는데, 이유를 찾아보니 python recursion limit 은 Python runtime 에서 자체적으로 재귀 호출을 스택에 담게되는데 스택의 기본 length 가 1,000으로 되어 있지만 해당 스택에 초기에 값이 들어있기에 문제가 발생하는 것으로 보입니다.
즉 초기 스택 프레임 사용은 정해져 있지 않으므로 널널히 늘리고 사용하는 것이 좋아보인다.
import sys
sys.setrecursionlimit(1010)문제 풀이
사실 문제가 너무 명확하고 간결해서 그래프를 그리는게 문제이며, 이진트리 문제를 잘 접하지 않는다면 어려울 수 있지만 풀어본 적이 있다면 크게 어려운 문제는 아니였던거 같다.
import sys
sys.setrecursionlimit(10**6)
def findRoot(nodes):
return sorted([[node[1], val] for node, val in nodes], key=lambda x : x[0])[-1][1]
def divideNode(nodes, root):
xNode = sorted(nodes, key=lambda x: x[0][0])
for i, node in enumerate(xNode):
if node[1] == root:
leftNodes, rightNodes = xNode[:i], xNode[i+1:]
return leftNodes, rightNodes
def solution(nodeinfo):
preorder, postorder = [], []
nodes = [[node, i+1] for i, node in enumerate(nodeinfo)]
def visitNode(nodes):
nonlocal preorder, postorder
if not nodes: return
root = findRoot(nodes)
leftNodes, rightNodes = divideNode(nodes, root)
preorder.append(root)
visitNode(leftNodes)
visitNode(rightNodes)
postorder.append(root)
return
visitNode(nodes)
answer = [preorder, postorder]
return answer새로 배운 내용 & 느낀점
Python REPL callStack code frames
위 문제를 풀며 언급했던 내용처럼 Python 의 기본 recursionlimit 은 1,000 입니다. 하지만 실제로 재귀함수를 돌려보며 재귀탐색을 하다보면 1,000에 도달하기전에 recursionlimit 을 초과했다는 런타임에러가 발생하게됩니다.
왜 그런걸까요?
- 가설1) 초기에 설정이 1,000이 아니었을까요?
>>> import sys
>>> sys.getrecursionlimit()
1000확인을 해보면 초기 recursionlimit 은 1,000으로 되어 있습니다.
- 가설2) 혹시 제가 재귀함수를 잘못 코딩해서 1000번을 초과한게 아닐까요?
n = 0
def test_recursion_limit():
def call():
global n
n += 1
call()
try:
call()
except RuntimeError:
print(n)
test_recursion_limit()
# 출력 : 998998번에서 에러가 발생합니다. 즉 999개의 call() 함수가 호출되었고 1000번째 call() 함수가 호출되지 않았습니다.
이를 통해 depth 가 999 까지 가능하다는걸 알게되었습니다.
- 가설3) 재귀함수를 담는 stack list 에 1개의 인자가 먼저 들어있던게 아닐까요?
(base) ☁ ~ python
Python 3.11.9 (main, Apr 19 2024, 11:43:47) [Clang 14.0.6 ] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> import inspect
>>> len(inspect.stack())
1
>>> print(inspect.stack())
[FrameInfo(frame=<frame at 0x101800bf0, file '<stdin>', line 1, code <module>>, filename='<stdin>', lineno=1, function='<module>', code_context=None, index=None, positions=Positions(lineno=1, end_lineno=1, col_offset=6, end_col_offset=21))]이 가설이 맞았네요. inspect.stack() 을 통해 재귀함수 스택을 확인한 결과 FrameInfo 가 포함되어 있네요.
Python REPL이 단순히 입력된 코드를 실행하는 기본적인 인터프리터이기 때문에, 호출 스택에는 현재 실행 중인 코드 프레임만 포함되어 Length는 1입니다.
그렇다면 좀 더 다양한 기능(구문 강조, 자동 완성, 매직 명령어 등)을 제공해주는 ipython 에서는 어떨까요?
(base) ☁ ~ ipython
Python 3.12.4 | packaged by Anaconda, Inc. | (main, Jun 18 2024, 10:07:17) [Clang 14.0.6 ]
Type 'copyright', 'credits' or 'license' for more information
IPython 8.25.0 -- An enhanced Interactive Python. Type '?' for help.
In [1]: import inspect
In [2]: len(inspect.stack())
Out[2]: 13
여기서 호출 스택의 깊이는 13입니다. 이는 IPython REPL이 기본 Python 인터프리터 위에서 동작하며, 다양한 추가 기능을 제공하기 위해 여러 프레임을 추가로 사용하기 때문입니다. 이러한 추가 프레임들은 IPython의 다양한 기능을 지원하기 위해 필요합니다.
즉 사용하는 REPL에 의해 해당 call Stck code Frame 기본 구성이 달라집니다.
- 보너스) 프로그래머스에서 사용하는 python REPL 의 기본 callStack codeFrame 은 얼마일까요 ?
import sys
import inspect
sys.setrecursionlimit(1008)
print(len(inspect.stack()))
# 출력 : 7느낀점
문제가 깔끔하게 이진트리 자료 구조에 대해 물어보고 있어서 해당 자료구조를 알고 있는지 없는지에 따라 문제 풀이 가능 여부가 정해진거 같다. 알고리즘의 경우 해당 알고리즘을 모르더라도 다른 풀이 방법으로 풀었을 때 효율성에서 안좋을 뿐 풀 수 있는 방법은 존재하지만 자료 구조에 대해서 모르는 문제는 건들 수 조차없어서 아쉬움이 많이 남을 것 같다.
다른 자료 구조 문제들을 많이 풀어봐야겠다.
참고자료
출처 : https://velog.io/@yunu/프로그래머스-길-찾기-게임
출처 : https://stackoverflow.com/questions/40115683/why-is-the-maximum-recursion-depth-in-python-1000
