해당 문제는 프로그래머스에서 풀어볼 수 있기에 문제 설명은 생략하겠습니다.
문제 해결 방법
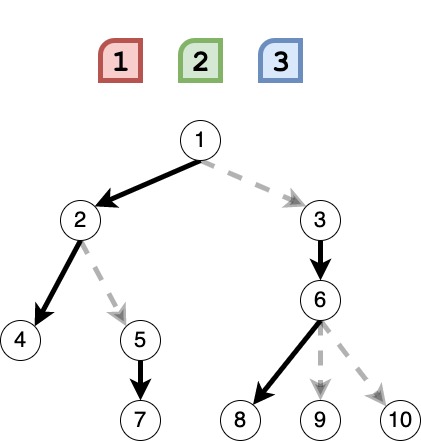
저는 위와 같은 복잡한 문제를 만나면 항상 문제를 쪼개서 생각을 하는 습관을 가지고 있습니다.
그렇게 문제를 읽고 가장 먼저 들었던 생각은 두 가지였습니다.
- 심플하게 상단루트에서 노드 방향만 바꾸면서 최소, 최대 값을 저장해 진행하는 코드를 짜면 답 도달이 가능한지(T/F) 유무판단과 최단거리로 구하기가 가능하다고 판단했습니다.
- 해당 기능을 구현하기 위해서 그래프의 인접리스트를 만들어야했습니다.
- 또한 각 노드를 인스턴스로 구현하면 각 노드들마다 자신의 자식노드들, 다음으로 방문할 자식노드, 리프노드라면 자신이 지금까지 더해져온 최소, 최대값 범위 등을 각자 기억시킬 수 있어 편리할 것으로 판단했습니다.
- 최종적으로 나온 최단거리로 지나온 노드들의 인덱스를 알 수 있다면 사전형식상 빠른 순으로 떨어 뜨릴 숫자를 나열하는 것을 알 수 있을 것이라 판단했습니다.
이렇게 초기 2가지 생각으로 쪼개어 생각했고 먼저 구현해야할 1번 과정을 다시 쪼개어 생각해 기본적인 자료구조를 구현해보았습니다.
시간복잡도 계산

먼저 시간복잡도를 고려한 설계를 진행해야하기에 위에서 제가 세운 초기 설계가 시간복잡도 내에 들어갈 지 고려하였습니다.
저는 계속해서 노드의 갯수는 최대 101개이며 간선의 갯수는 100개였습니다. 또한 리프노드의 쌓일 수 있는 값은 최대 100까지로 최솟값인 1씩 더해진다하더라도 최대 100번의 연산이 진행됩니다.
이를 토대로 계산해본 제 시간복잡도는 루프의 리프노드를 찾는데 걸리는 최악의 시간복잡도 N, 루프의 리프노드에 값이 변경 될때마다 target 과 검증하는 과정의 시간복잡도 N 으로 O(N^2) 이 예상됩니다.
이정도면 N이 100으로 매우 작기때문에 시간복잡도는 전혀 문제가 되지 않는다고 판단하여 시간복잡도를 더이상 고려하지않고 직관적으로 코드 구현이 가능하다면 직관적으로 짜려고 노력하엿습니다.
문제 풀이
Node 설계
각 노드들마다 자신의 자식노드를 담는 nodes, 다음으로 방문할 차례인 자식노드 인덱스를 가리키는 idx, 마지막으로 자신이 리프노드일 경우를 위해 자신의 최소, 최대값을 저장할 leafSum 을 초기화하고 시작하였습니다.
class Node:
def __init__(self):
self.nodes = []
self.idx = 0
self.leafSum = [0, 0]
def push(self, i):
self.nodes.append(i)
def selectNode(self):
if self.nodes:
val = self.nodes[self.idx]
self.idx = (self.idx + 1) % len(self.nodes)
return val
return False
def plusLeaf(self):
self.leafSum[0] += 1
self.leafSum[1] += 3
return self.leafSum
def __repr__(self):
return str(self.nodes)그 이후엔 해당 클래스에 3가지 함수를 정의해 각 노드 인스턴스를 관리할 수 있게 구현했습니다.
- push 함수를 만들어 인접리스트 방식으로 노드의 자식노드를 추가할 수 있도록 구현했습니다.
- selectNode 함수를 만들어 현재 노드의 자식노드들 중 다음으로 방문해야할 자식노드 index를 리턴하도록 하였고 다음 자식노드의 인덱스를 해당 노드 인스턴스.idx에 업데이트합니다. 이 때 만약 리프노드이기에 자식노드가 없다면 False를 리턴하여 리프노드임을 알려주도록 구현했습니다.
- plusLeaf 함수를 만들어 리프노드일 경우 최소, 최대 값을 리프노드 인스턴스에 업데이트하고 해당 업데이트된 값을 바로 리턴하도록 구현하였습니다.
그 이후 Main 이 되는 solution 함수에 다음과 같이 노드 정보를 초기화 시키는 코드를 통해 인접리스트를 구현할 수 있었습니다.
nodes = [Node() for _ in range(len(target)+1)]
for x, y in edges:
nodes[x].push(y)놓치기 쉬운 부분
해당 문제는 함정처럼 놓치기 쉬운 부분들이 2가지 존재하였습니다.(사실 제가 놓쳤었습니다.)
-
노드의 번호가 1번부터 시작.

노드 번호가 1번부터 시작하기에 0번 인덱스부터 시작하는 것을 고려하여 범위를 1칸씩 늘려주었습니다.
사실 이 부분은 모두 잘 알고있으시겠지만, 이 때 target으로 주어진 값또한 1번인덱스부터 시작하는 것으로 되어있어 앞에 0번인덱스를 고려할 수 있도록 범위를 늘려주어야 했습니다.target = [0] + target -
edges 순서가 뒤죽박죽을 제공되더라도 자식노드 번호가 가장 작은 것을 초기 길로 설정함.

이 글에서 사실 애매한 부분이 있엇습니다. 자식 노드 중 가장 번호가 작은 노드를 간선의 초기길로 설정하고 나머지는 edges 에서 제공하는 순서대로 하라는 것인지, 다음 노드를 가리키는 것도 노드 번호가 작은 순서대로 해야하는 것인지입니다. 저는 그래도 후자가 더 합리적인것 같아 edges의 자식노드를 기준으로 sorting 하였고 최종적으로 맞는 선택이었습니다.edges.sort(key=lambda x : x[1])
최종 코드
class Node:
def __init__(self):
self.nodes = []
self.idx = 0
self.leafSum = [0, 0]
def push(self, i):
self.nodes.append(i)
def selectNode(self):
if self.nodes:
val = self.nodes[self.idx]
self.idx = (self.idx + 1) % len(self.nodes)
return val
return False
def plusLeaf(self):
self.leafSum[0] += 1
self.leafSum[1] += 3
return self.leafSum
def __repr__(self):
return str(self.nodes)
def solution(edges, target):
answer = []
nodes = [Node() for _ in range(len(target)+1)]
edges.sort(key=lambda x : x[1])
curValues = [0 for _ in range(len(target)+1)]
target = [0] + target
for x, y in edges:
nodes[x].push(y)
temp = []
while True:
w = nodes[1].selectNode()
while w:
leaf = w
w = nodes[w].selectNode()
curValues[leaf] = nodes[leaf].plusLeaf()
temp.append(leaf)
for i in range(len(target)):
if curValues[i] and curValues[i][0] > target[i]:
return [-1]
elif not curValues[i] and target[i]:
break
elif curValues[i] and not curValues[i][0] <= target[i] <= curValues[i][1]:
break
else:
for t in temp:
curValues[t][0] -= 1
curValues[t][1] -= 3
for j in range(1, 4):
if curValues[t][0] <= target[t]-j <= curValues[t][1]:
answer.append(j)
target[t] -= j
break
return answer
return 0최종적으로 위에서 Node Class 를 구현하고 인접리스트를 만든 뒤 놓치기 쉬운 부분들을 체크한다면 노드의 1번 노드부터 탐색하여 도달할 다음 리프노드를 아래 코드처럼 쉽게 구할 수 있습니다. 또한 해당 리프노드의 최소, 최대값을 업데이트하고 업데이트 시 마다 target과 비교하여 그때 그때 정답 유무를 알 수 있고 이는 최단거리를 보장합니다.
만약 현재 리프노드의 최솟값이 목표로하는 target의 값보다 커지게 된다면 target 에는 음수(-)값이 들어올 수 없으므로 만들 수 없다는 뜻의 [-1] 을 리턴하여 성공 유/무를 판단할 수 있습니다.
마지막으로 최단거리로 도달할 수 있는 정답을 발견했다면 반드시 성공하는 최단거리임이 보장되므로 앞에서부터 1부터 넣어 사전적으로 빠른 순을 검사합니다. 만약 1을 넣었을 때 실패하게된다면 1은 들어 갈 수 없으므로 1->2->3 순으로 넣어 사전적으로 빠른순을 보장합니다.
느낀점
카카오 코테는 배워가는 점이 정말 많은 것 같다. 카카오 코테 문제를 풀면서 2차원 누적합이나 비트마스킹+다익스트라가 합쳐진 문제 등을 보고 정말 다양한 사고를 요구하는구나라고 느꼈었다.
이번 문제도 단순 구현이지만 노드별 초기화, 업데이트를 하지않으면 구현이 상당히 복잡해진다. 이는 객체적 구현을 통한 인스턴스 관리를 묻는 문제가 될 수도 있고, 그렇지 않다면 함수형 구현으로 Shallow Copy 문제를 해결하며 설계할 수 있는지 묻는 문제이기도 했다.
또한 1~3 까지 숫자가 더해질 수 있기에 문제 자체적으로 어렵게(?) 느껴지게 만드는 요소가 되기도 했다. 복합적인 문제들을 해결할 수 있는지 묻는 문제이기에 개인적으로 특정한 알고리즘이나 자료구조를 반드시 알아야 풀 수 있는 문제들보단 좋은 문제라고 생각하고 여러번 복습을 해야겠다고 느꼈습니다.
감사합니다.
