해당 문제는 프로그래머스에서 풀어볼 수 있기에 문제 설명은 생략하겠습니다.
문제 해결 방법
초기에 문제를 읽고 들었던 구현 방법은 hashmap 을 트리형태로 연결한 Trie 자료 구조였습니다.
시간복잡도 계산

이 문제의 경우 시간복잡도를 줄이는 과정에서 굉장히 생각을 많이 해야하는 문제입니다. 트라이 자료구조의 시간복잡도는 O(m) 여기서 m 은 검색 키워드의 길이입니다. 위 검색 키워드 제한사항으로 주어진 전체 검색 키워드 길이의 합은 1,000,000 이하로 단순히 트라이 자료구조로 사전적인 검색만 하게된다면 통과할 수 있는 기준입니다.
하지만 문제는 와일드카드 문자인 '?' 를 사용할 수 있다는 점입니다. 알파벳은 26개의 영단어로 구성되며, '?'만 들어 있는 '??????'도 가능한 키워드 임을 생각하면 최악의 경우 26^1,000,000 이라는 말도 안되는 연산량이 필요할 수 있습니다. (물론 전체 가사 단어 길이의 합 또한 1,000,000 이하로 이 경우 연산량은 1,000,000 * 1,000,000 이 최대 연산량이지만 이 정도만 되도 시간초과가 발생하기엔 충분합니다.)
그렇기 때문에 이를 해결하는 것이 관건이라고 볼 수 있습니다.
Trie 자료 구조 만들기
Trie 자료 구조는 class 를 통해 다양한 방식으로 만들어 볼 수 있는데, 만약 시간복잡도를 생각하지 않고 Trie 자료 구조를 단순히 만드는 문제였다면 아래처럼 직관적으로 만들었을 것 같습니다.
from collections import defaultdict
class Node:
def __init__(self):
self.isDone = False
self.dict = defaultdict(Node)
class Trie:
def __init__(self):
self.node = Node()
self.cnt = 0
def insert(self, node : Node, word) -> None:
if len(word) == 0:
node.isDone = True
return
self.insert(node.dict[word[0]], word[1:])
def add(self, word) -> None:
self.insert(self.node, word)
return
def checkQuery(self, node: Node, query) -> None:
if not query:
if node.isDone:
self.cnt += 1
return
q = query[0]
if q == "?":
for v in node.dict.keys():
self.checkQuery(node.dict[v], query[1:])
else:
self.checkQuery(node.dict[q], query[1:])
def check(self, query)->int:
self.cnt = 0
self.checkQuery(self.node, query)
return self.cnt
def solution(words, queries):
answer = []
t = Trie()
for word in words:
t.add(word)
for query in queries:
cnt = t.check(query)
answer.append(cnt)
return answer하지만 이 문제에선 이 과정으로 문제를 풀면 당연히 시간초과에 걸리게되고, 주어진 조건을 보고 적당히 가지치기를 해주어야합니다.
해결 방안 key
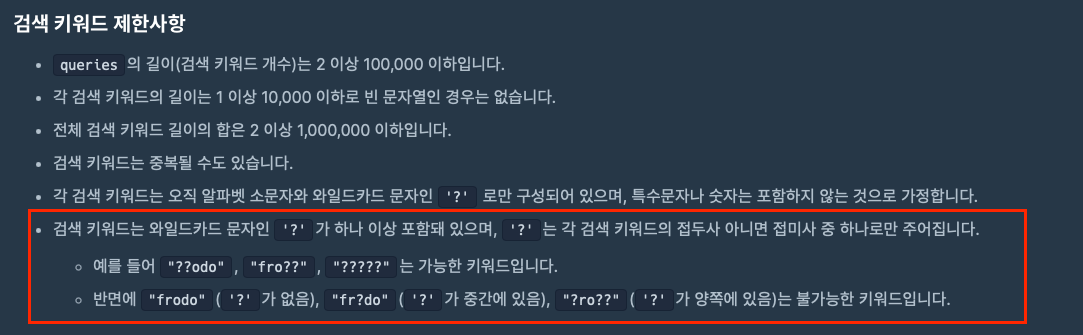
문제의 핵심 해결 키워드는 위 문구로 와일드카드 문자인 '?' 는 한 개 이상 존재하며 접미사 또는 접두사 하나로만 주어진다는 규칙이 있습니다.
와일드카드 검색은 최소화 해야하므로 위 문제를 풀기위해 세 가지 경우의 수로 나누어 문제를 해결하였다.
- '??????' 와 같이 완전히 와일드카드로만 존재하는 경우 -> length 만을 저장하는 딕셔너리를 따로 만들어 길이만을 빠르게 비교해 경우의 수를 체크한다.
- 'fro??' 와 같이 접미사로 주어진 경우 -> 초기 길이 먼저 비교 후 물음표가 나오기 직전인 알파벳 fro 만을 비교함
- '??odo' 와 같이 접두사로 주어진 경우 -> 초기 길이 먼저 비교 후 값을 뒤집어 'odo??' 으로 만들어 거꾸로 저장해둔 Trie 자료 구조와 비교
이렇게 할 경우 Trie 자료 구조는 2개 딕셔너리 1개를 초기 구성해야하는 번거로움이 있지만, 값을 비교할 때 길이가 같은 값만 비교하여 빠르고, 와일드 카드 문자가 나오기 직전까지만 비교하므로 매우 빠르게 값을 처리할 수 있습니다.
문제 풀이
위에서 언급하였던대로 접두사, 접미사를 구분하기 위한 2가지 Trie 구조와 길이만을 빠르게 비교하기 위한 Dictionary 하나를 만들 예정이다. 하지만 여기서 Trie 구조를 잡을 때도 길이가 다르다면 알파벳 확인이 무의미 하므로 빠른 확인을 위해 Dictionary (key 값은 length) 안에 Trie 자료구조를 사용하는 방식으로 진행하였다.
먼저 Trie 자료 구조를 통해 가사의 딕셔너리를 초기 구성할 때 prefixDict 와 suffixDict, lenDict 3가지로 나누었습니다.
word - Trie, Dictionary 구성
from collections import defaultdict
class Trie():
def __init__(self):
self.root = {}
def insert(self, word):
cnode = self.root
for s in word:
if s not in cnode:
cnode[s] = [ {}, 0 ]
cnode[s][1] += 1
cnode = cnode[s][0]
def solution(words, queries):
answer = []
prefixDict = defaultdict(Trie)
suffixDict = defaultdict(Trie)
lenDict = defaultdict(int)
for word in words:
prefixDict[len(word)].insert(word)
suffixDict[len(word)].insert(word[::-1])
lenDict[len(word)] += 1
query 탐색
for query in queries:
if query[0] == "?" and query[-1] == "?":
a = lenDict[len(query)]
elif query[0] == "?":
a = suffixDict[len(query)].find(query[::-1])
elif query[-1] == "?":
a = prefixDict[len(query)].find(query)쿼리 탐색을 진행하게 될 때에는 먼저 '??????' 와 같이 접두사, 접미사 구분이 없이 전체가 와일드카드로 구성된 형태인지 파악한 후 lenDict 를 이용하여 빠르게 결과를 판단하고 접미사, 접두사 구분이 된 쿼리라면 이를 나누어 각각 만들어둔 Trie 자료구조에 length 길이 파악 후 결과를 파악한다.
최종 코드
from collections import defaultdict
class Trie():
def __init__(self):
self.root = {}
def insert(self, word):
cnode = self.root
for s in word:
if s not in cnode:
cnode[s] = [ {}, 0 ]
cnode[s][1] += 1
cnode = cnode[s][0]
def find(self, word) -> int:
result = 0
cnode = self.root
for s in word:
if s == "?":
return result
else:
if s in cnode:
result = cnode[s][1]
cnode = cnode[s][0]
else:
return 0
return result
def solution(words, queries):
answer = []
prefixDict = defaultdict(Trie)
suffixDict = defaultdict(Trie)
lenDict = defaultdict(int)
for word in words:
prefixDict[len(word)].insert(word)
suffixDict[len(word)].insert(word[::-1])
lenDict[len(word)] += 1
for query in queries:
if query[0] == "?" and query[-1] == "?":
a = lenDict[len(query)]
elif query[0] == "?":
a = suffixDict[len(query)].find(query[::-1])
elif query[-1] == "?":
a = prefixDict[len(query)].find(query)
answer.append(a)
return answer해당 문제에선 길이가 정해져 있었고, 시간 활용을 위하여 length 를 먼저 파악하는 코드를 구현하였지만, 사실 Trie 자료 구조는 접두사(prefix) 트리 라고 불릴 만큼 앞에서 부터 원하는 결과를 파악하기 위해 계속해서 탐색해 나가는 자료 구조에 가까워 length 를 정하지 않는 것이 일반적인 것 같습니다.
새로 배운 내용 & 느낀점
새로 배운 내용
Trie 자료 구조
Trie는 문자열을 효율적으로 저장하고 검색할 수 있는 트리 기반의 자료구조이다. 주로 사전(dictionary)와 같은 애플리케이션에서 사용되며, 접두사(prefix) 트리라고도 불린다.
트라이의 주요 특징
- 문자 기반 노드.
- 각 노드는 특정 문자를 나타내며, 루트 노드는 빈 문자열을 나타냅니다.
- 자식 노드는 부모 노드의 문자열에 문자를 추가한 문자열을 나타냅니다.
- 효율적인 검색.
- 문자열 검색이 O(m) 시간 복잡도를 가지며, 여기서 m은 검색하려는 문자열의 길이입니다.
- 접두사 검색(prefix search)에 특히 효율적입니다.
- 공간 효율성.
- 같은 접두사를 공유하는 문자열은 노드를 공유하므로, 저장 공간을 절약할 수 있습니다.
일반적인 Trie 구조
- 노드(Node)
- 각 노드는 여러 자식 노드를 가질 수 있습니다.
- 각 노드는 하나의 문자를 나타내고, isDone 플래그를 통해 하나의 단어가 끝나는 지점을 표시합니다.
- 자식 노드들은 해시 테이블(파이썬에서는 dict 또는 defaultdict로 구현)로 관리됩니다.
트라이의 주요 연산
- 삽입(Insert)
- 단어를 트라이에 삽입할 때, 각 문자를 차례로 따라가면서 노드를 추가합니다.
- 단어의 마지막 문자 노드에 isDone 플래그를 설정합니다.
- 검색(Search)
- 특정 단어 또는 접두사가 트라이에 존재하는지 확인합니다.
- 각 문자를 차례로 따라가며 노드를 탐색합니다.
- 검색하고자 하는 단어가 끝나는 노드에서 isDone 플래그를 확인하여 단어의 존재 여부를 판단합니다.
느낀점
Trie 자료 구조를 새롭게 배우게 되었다, 그 동안 비슷한 문제를 풀며 이게 트라이 자료구조인지도 제대로 모르고 그저 dictionary 의 재귀적인 구현을 통해 풀어야 할 것 같다는 느낌으로 풀어왔었는데, 단순 구현 문제가 아닌 트라이 자료구조 + 시간복잡도 해결 방법을 묻는 문제를 만나니 다른 사람들의 여러 풀이를 보고 트라이 자료 구조에 대해서도 공부하는 시간이 되었습니다.
여러 자료구조들을 좀 더 자세히 찾아보고 python 에서 동작 과정도 알아보는 시간이 필요할 거 같다고 느꼈습니다.
네이버 검색엔진에선 접두사, 접미사를 넘어서 가운데에서도 등장할 수 있고 띄어쓰기도 알아서 변경하는 모습을 보이는데 Trie 자료구조를 바탕으로 구현되었을 것이라 생각합니다.
만약 위 자동완성을 나보고 구현하라고 한다면?
- 최근 검색이 많이 된 키워드들을 일정 시간텀으로 캐싱
- 키워드들이 캐싱된 db에 쿼리를 날리는 백엔드 API를 구현
- 프론트엔드에서 inputbox 에 onChange 이벤트를 걸어 API 요청
방식으로 구현할 것 같은데, 올바른 방법인지는 잘 모르겠습니다.
(혹시 잘 아시는 고수분이 있다면 댓글 달아주시면 제 공부에 많은 도움이 될 것 같습니다!)
