논문 : https://arxiv.org/abs/2507.02379
Abstract
복잡한 실험을 독립적으로 수행하고, 비전문가에게도 서비스를 제공하는 자율적인 과학 연구는 오랜 목표였다. 현재 자율 실험 시스템이 등장하고 있으나, 이는 주로 단일 목적이나 잘 정의되고 간단한 실험 워크플로우(예: 화학 합성, 촉매)에 국한된다.
본 논문은 AI-native 자율 실험 플랫폼을 제안한다.
이 플랫폼은 실험 장비 자율적으로 관리하고, 실험에 특화된 절차 및 최적화 휴리스틱 형성하며, 다수의 사용자 요청을 동시 처리할 수 있다.
이를 통해 인간의 개입 없이, 실험 성능을 자율적으로 최적화하고, 인간 과학자가 달성한 기존 최고 수준(state-of-the-art)의 성능에 도달한다.
Instroduction
기존 한계
기존 AI 통합 플랫폼은 자연어 명령(NLP instructions)을 통해 실험을 실행할 수 있도록 LLM과 자동화 하드웨어를 결합한 구조를 취하고 있다.
하지만 이러한 시스템들은 인간이 사전에 정의한 워크플로우나 휴리스틱에 의존한다는 한계가 존재한다.
예를 들어, Dai et al.이 제안한 자율 플랫폼은
단순한 유기화학 실험을 사전 정의된 절차에 따라 수행하며, 유기화학자의 역할을 상당 부분 대체하는 수준에 머무른다.
기존 자율 플랫폼의 핵심적인 문제는 실험 과정을 이해하거나 지각(perceive)하지 못한다는 점이다.
이들은 여전히 과학자가 장비를 수동으로 설정하고, 실험 절차를 구성하며, 최적화를 위한 휴리스틱을 설계해야만 작동할 수 있다.
이는 대부분의 시스템이 'add-on' 아키텍처를 채택하고 있기 때문이다.
즉, AI 모델이 하드웨어에 본질적으로(native) 통합되어 있지 않으며, 단순히 보조하는(supplement) 방식에 불과하다.
결과적으로 이러한 시스템은 단일 목적(single-objective)과
잘 정의된 워크플로우(예: 화학 합성, 촉매)에서만 효과적으로 작동한다.
해결책 : AI-native 자율 실험실
이러한 문제를 해결하기 위해, 본 논문은 AI-native 자율 실험실(AI-native autonomous laboratory)을 제안한다.
이 시스템은 기존의 add-on 아키텍처를 모델–실험–장비 간의 공동 설계(co-design) 방식으로 대체하였다.
이러한 통합은 AI 모델이 실험 요구사항과 장비의 기능(instrument capabilities)을 정확하게 이해할 수 있도록 하며,
이를 통해 사전에 정의된 휴리스틱 없이도, 복잡한 작업에 대한 자율적인 최적화와 의사결정을 지원한다.
그리고 이 접근 방식은 closed-loop 시스템을 구현하여,
설계–실험–최적화(design–experiment–optimize)를 반복적으로 수행하도록 한다.
더 나아가, 이 자율 실험실은 장비의 실시간 상태에 기반하여 실험 절차를 동적으로 조정하고, 장비를 유연하게 관리한다.
이러한 기능은 다중 사용자 환경에서도 실험 효율(experimental efficiency)과 장비 활용도(instrument utilization) 모두 극대화할 수 있게 한다.
이러한 접근을 기반하여 본 연구에서는, AutoDNA라는 AI-native 자율 실험실을
핵산 과학(nucleic acid science) 분야에 맞춰 개발하였다.
AutoDNA는 합성(synthesis), 증폭(amplification), 전사(transcription), 시퀀싱(sequencing) 등 핵심 기능을 포함하며, 질병 진단, 약물 개발, 데이터 저장과 같은 응용 서비스도 제공한다.
이 모든 서비스는 비전문가(non-experts)도 자연어 명령(natural language requests)을 통해 접근할 수 있다.
또한, 공유 자원을 사용하는 다중 사용자 환경에서도, AutoDNA는 실시간 상태 인식 기반 스케줄링을 통해 기존 방식 대비 3배 향상된 experimental throughput)을 달성한다.
AutoDNA system architecture
AutoDNA는 두 가지 주요 모듈로 구성된다:
- 화학적 계획 모듈(Chemical Planning)
- 하드웨어 실행 모듈(Hardware Execution)
각 모듈은 여러 LLM 기반 에이전트(LLM-powered agents)로 구성되며, 이 에이전트들은 자연어를 통해 상호작용한다.
또한 LLM의 언어 이해 능력과 추론 능력을 활용하여, 에이전트들은 모듈 간 협업 및 (co-evolution)를 가능하게 한다.
이에 따라,
- 화학 계획 모듈은 실험 절차를 생성하고,
- 하드웨어 실행 모듈은 해당 절차를 기반으로 실험을 자율적으로 수행한다.
또한, 에이전트는 실시간 실험 피드백과 장비 상태를 지속적으로 모니터링하며,
이를 통해 절차를 자율적으로 최적화하여 yield와 efficiency를 향상시킨다.
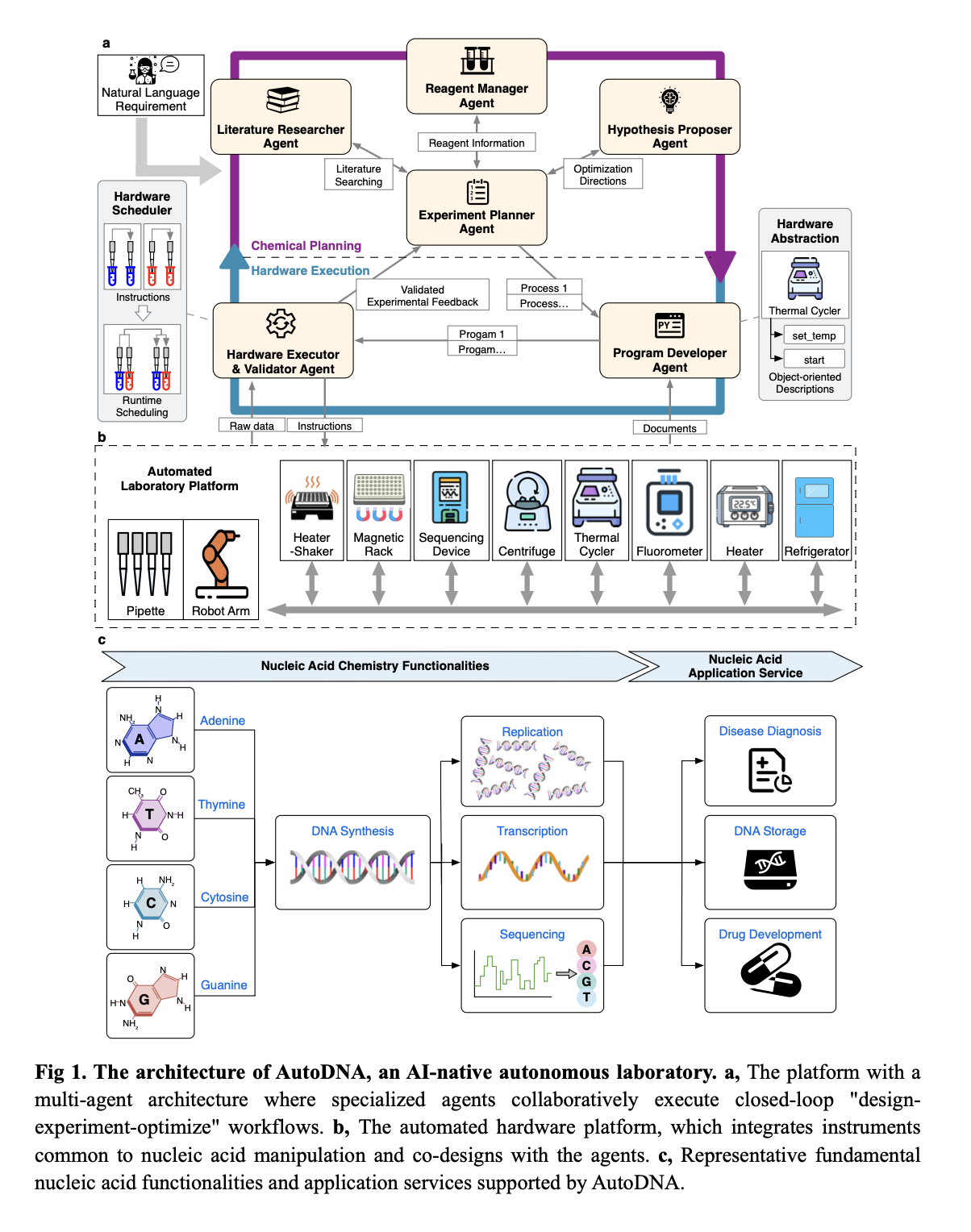
Chemical Planning Module의 4가지 에이전트
-
Experiment Planner Agent (EPA)
: 사용자 요구에 따라 실험 절차를 설계한다.
-
Hypothesis Proposer Agent (HPA)
: 기존 실험 절차에 대한 최적화 가설(hypotheses)을 생성한다.
-
Literature Researcher Agent (LRA)
: 과학 논문에서 핵심 정보를 검색하여, 그 정보를 EPA에게 전달해서 더 나은 실험 절차를 짤 수 있게 도와준다.
-
Reagent Manager Agent (RMA)
: 시약 inventory를 관리하고, 실험 절차 생성 시 resource constraints를 반영한다.
Hardware Execution Module의 2가지 에이전트
-
Program Developer Agent (PDA)
: 장비 기능(instrument functionalities)을 추상화하고,
고수준 실험 절차(high-level procedures)를 실행 가능한 코드로 변환하여 하드웨어 작업을 수행한다.
-
Hardware Executor & Validator Agent (HEVA)
: 코드를 배포(deploy)하고, 실험을 실행하며, 결과를 검증(validate)한다.
그 결과에 대한 feedback을 Chemical Planning Module에 전달한다.
PDA와 HEVA는 다중 사용자 요청이 있을 경우 협력적으로 하드웨어 자원을 관리하며,
time-sharing을 통해 utilization과 처리량(throughput)을 극대화한다.
Entire Workflow
사용자의 요청을 받으면,
- Experiment Planner Agent (EPA)는 먼저 Literature Researcher Agent (LRA)와 협력하여 후보 실험 절차(candidate procedures)를 생성한다.
- 이후 EPA는 Reagent Manager Agent (RMA)와 cross-reference를 진행하여, 사용 가능한 시약이 없는 실행 불가능한 절차(non-viable procedures)를 걸러낸다.
- 선별된 절차는 하드웨어 실행 모듈로 전달되며, 여기서 Program Developer Agent (PDA)가 해당 절차에 대응하는 control code를 생성한다.
- *Hardware Executor & Validator Agent (HEVA)는 실시간 장비 상태에 따라 코드 실행을 스케줄링 및 수행하며, 실행이 끝난 뒤 검증된 결과(validated results)를 EPA에게 다시 보고한다.
- EPA는 이 결과를 바탕으로 추가 최적화가 필요한지 판단하고, 필요하다면 Hypothesis Proposer Agent (HPA)를 호출하여 개선 경로(improvement pathways)를 탐색한다.
- 이후 EPA는 HPA의 도움을 받아 실험을 improvement pathway를 찾고,
사전에 정해둔 목표(preset objectives)에 도달할 때까지 개선된 실험 절차(refined procedures)를 반복적으로 생성한다.
이 모든 워크플로우는 인간의 개입 없이, 자율적인 agent coordination에 의해 실행된다.
PDA: 문서 기반 장비 제어 코드 자동 생성기
AutoDNA는 end-to-end 자율성(end-to-end autonomy)을 가능하도록,
수동 장비 모델링(manual instrument modeling)이나 제어 코드 개발(control code development) 없이 작동할 수 있도록 설계된 model-instrument 공동 설계(co-design) 방법론을 채택한다.
구체적으로, Program Developer Agent (PDA)는
기술 문서(technical documentation)에서 추출한 장비 기능을
'atomic service'라 불리는 AI-native 추상화(abstraction)로 변환한다.
예시로 thermal cycler 같은 경우, 온도 조절(set_temp), 반응 시작(start)이라는 두 가지 atomic service로 추상화된다.
각 atomic service는 자연어 설명이 포함된 Python 객체로 표현되며, 이는 에이전트의 자연어 이해 능력과 연동될 수 있도록 구성되어 있다.
더 나아가, PDA는 자율적으로 코드의 무결성을 검증하고, 필요 시 장비 문서(documentation)를 참조하여 error correction도 수행한다.
EPA, LRA, HPA의 협업 구조
기존 접근 방식인 사전에 정의된 휴리스틱(predefined heuristics)에 의존하는 방식과 달리, AutoDNA는 다중 에이전트 협업(multi-agent collaboration)을 통해 autonomous multi-objective optimization를 수행한다.
이러한 과정은 Experiment Planner Agent (EPA)가 Literature Researcher Agent (LRA)와 Hypothesis Proposer Agent (HPA)를 조율하며 진행된다.
- LRA는 문헌 분석을 통해 절차 설계에 활용할 수 있는 핵심 정보를 도출하고,
- HPA는 실험 결과가 기대에 못 미칠 경우(underperform), 데이터를 분석해 개선 가설(improvement hypotheses)를 생성한다.
그 후 EPA는 LRA의 문헌 기반 정보와 HPA의 가설을 통합하여, 개선된 실험 절차(revised procedures)를 설계한다.
또한, 다중 목표가 요구되는 실험에서는 EPA가 사용자의 요청에 따라 목표 간 우선순위(priority)를 설정한다.
HEVA 중심의 자율 하드웨어 자원 관리
AutoDNA는 자율 하드웨어 자원 관리(autonomous hardware management) 기능도 갖추고 있어, 여러 실험 요청을 동시에 병렬(concurrent)로 처리할 수 있다.
이를 통해 기존 자율 플랫폼과 비교하여, 장비 활용도(instrument utilization)와 실험 효율(experimental efficiency)을 크게 향상시킨다.
이 과정에서 Hardware Executor & Validator Agent (HEVA)는
장비 상태에 대한 실시간 인식(real-time awareness)을 유지하고, 최적의 자원 스케줄링 전략(resource scheduling strategy)을 수립한다.
이러한 설계는 제어 코드 생성(control code generation)과 물리적 자원 스케줄링을 분리(decouple)하는 특징이 있다.
- Program Developer Agent (PDA)는 장비 독점 사용을 전제로 코드를 생성하고, HEVA는 다중 사용자 요청을 통합(consolidate)하고, 이를 스케줄링한다.
장비 충돌(conflict)이 발생할 경우, HEVA와 PDA가 협력하여 절차를
기능적으로 동일한 장비(functionally equivalent instruments)로 우회(reroute)시킨다.
AutoDNA의 실제 구현: 범용 핵산 실험 플랫폼
본 논문은 AutoDNA 시스템을 물리적 실험 플랫폼(physical platform) 위에 구현하였다.
이 플랫폼은 여러 실험 장비들을 피펫과 로봇 팔로 연결하여, 임의의 두 장비 간에 시약을 전달할 수 있도록 구성되어 있다.
이 하드웨어는
마이크로리터(μL) 단위의 정밀한 부피 제어(volumetric precision)와
마이크로미터(μm) 수준의 위치 정확도(positional accuracy)를 달성하며,
이는 분자생물학 실험의 저용량·고정밀 요구를 충족시킨다.
또한 이 플랫폼은
합성(synthesis), 증폭(amplification), 전사(transcription), 시퀀싱(sequencing)을 포함한 핵산 실험 전반을 포괄적으로 지원한다.
이러한 플랫폼의 다재다능한(versatility) 성격은, AutoDNA가 다양한 응용 분야에서 end-to-end service를 제공할 수 있게 되었다.
(*end-to-end service : 사용자가 자연어로 실험 목표를 요청하면 → 그 뒤의 전 과정이 사람이 개입하지 않아도 완전히 자동으로 이루어지는 구조)
End-to-end autonomous nucleic acid test service
AutoDNA의 핵산 테스트: End-to-End 자율 서비스 시연

AutoDNA는 핵산 테스트(nucleic acid test) 응용 사례를 통해 end-to-end 자율 서비스를 실제로 시연하였다.
핵산 테스트는 특정 유전 서열(RNA/DNA)을 식별하는 과정으로, 바이러스 진단, 유전 질환 선별, 환경 모니터링 등에 핵심적으로 활용된다.
대표적인(common) 방법 중 하나는 RPA (Recombinase Polymerase Amplification)이며 빠른 속도와 절차의 단순성 두 가지 특징이 있다.
기존 접근
RPA의 절차가 단순하기 때문에, EPA는 문헌 검색 없이 직접 three-step workflow(시약 혼합 → 인큐베이션 → 형광 테스트)를 생성할 수 있었다.
이후 실험 코드를 생성할 때, hardware abstractions을 적용하지 않으면 PDA는 instrument-specific commands가 빠진 수도 코드(abstract pseudocode)만 생성할 수 있었다.
↔(Conversely) 하드웨어 추상화를 활용하면, PDA는 실행 가능한 장비 제어 코드를 생성할 수 있다. 이를 통해 AutoDNA가 완전한 자율 실험 실행이 가능해졌다.
특히, PDA는 incubation 단계에서 반응 튜브를 밀봉해야 한다는 요구를 스스로 인식하고, 로봇 팔의 lid-sealing 동작을 호출하였다. 이는 에어전트의 LLM이 증발 방지를 위한 RPA의 밀폐 환경 필요성(closed environment for RPA)을 이해하고, 하드웨어 추상화를 기반으로 실험 정확도를 높이기 위한 추론을 수행할 수 있었다.
또한 PDA는 장비 작동 설명서(documentation)를 활용해, 시약 전달 단계가 누락되어 있었던 치명적인 코드 오류를 감지하고 수정하였다. 이 오류는 thermal cycler와 fluorometer가 빈 샘플에 작동하게 만들 뻔한 문제였다.
자율 실험에서 얻은 형광 측정 결과는 수동 실험과 통계적으로 동등(statistically equivalent)했으며, 양성 샘플 판별에 있어서도 진단 일치도(diagnostic concordance)를 확보함으로써, AutoDNA가 자연어 명령만으로도 완전한 end-to-end 핵산 테스트를 수행할 수 있음을 입증하였다.
(요약)
기존에는 하드웨어 추상화가 없는 경우, PDA는 장비에 특화된 명령 없이 단순한 추상적 수도코드만 생성할 수 있었다.
그러나 하드웨어 추상화를 활용하면, PDA는 로봇 팔, 피펫, 열순환기, 형광측정기 등을 조정하는 실행 가능한 장비 제어 코드를 생성하게 된다.
특히 PDA는 incubation 동안 뚜껑을 닫아야 한다는 요구를 스스로 추론해 해당 장비 동작(capTubeGroup)을 호출했고, 장비 명세를 기반으로 reagent transfer 누락이라는 치명적 오류도 감지 및 수정했다.
이처럼 AutoDNA는 자연어로 실험 목표를 지시하면, 전 과정을 스스로 수행하여, manual 실험과 동등한 정확도를 보여주었다.
Multi-objective autonomous optimization services for enzymatic DNA synthesis
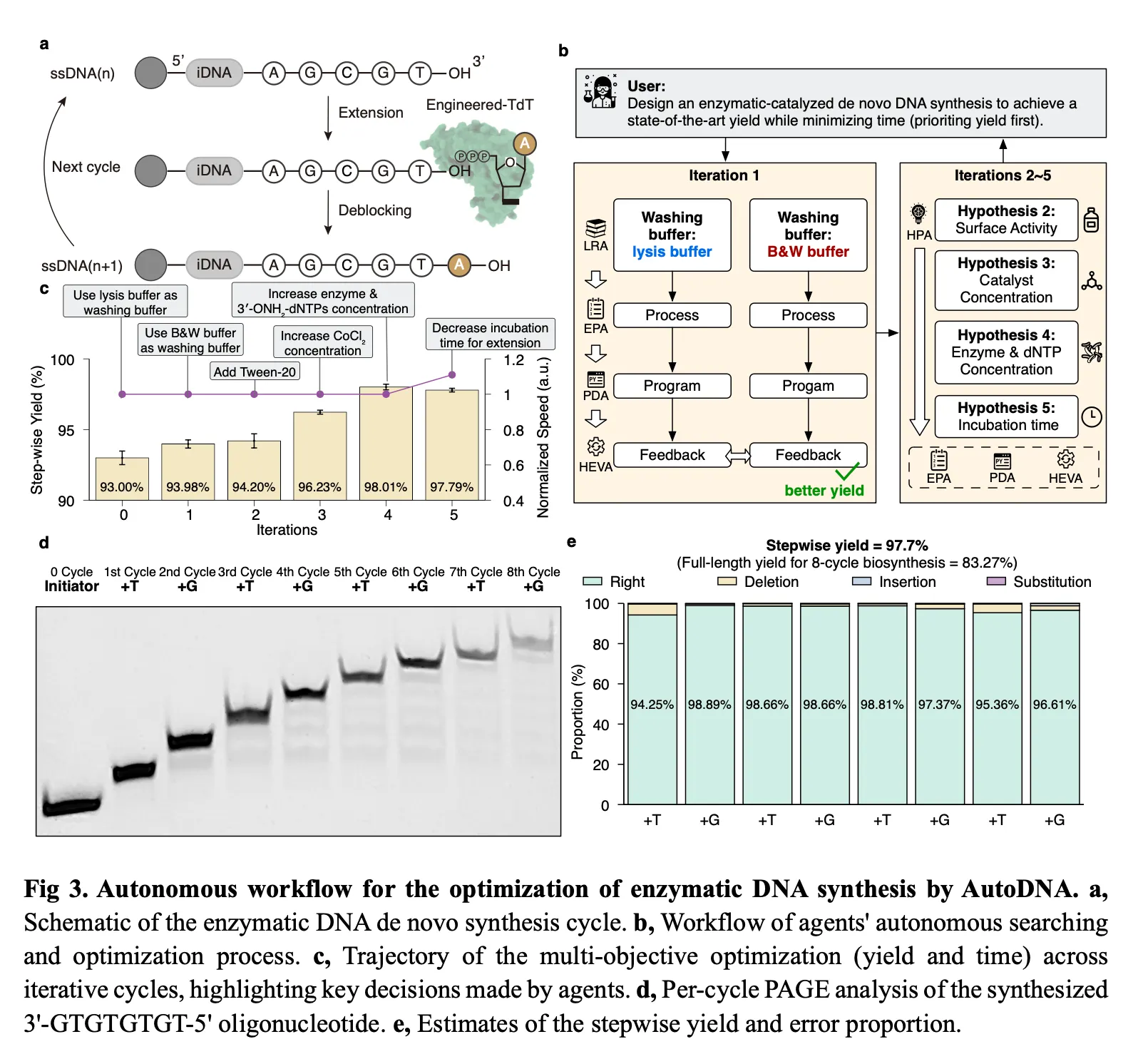
이 그림은 AutoDNA가 단순한 프로토콜 자동화 수준을 넘어서, 문헌 기반 제안 + 가설 기반 실험 설계 + 반복 최적화 + 실험 피드백 반영까지의 전체 사이클을 자율적으로 수행하며, 그 결과가 전문가의 수작업과 유사한 수준임을 실험적으로 입증했다는 점에서 자율 실험 설계·최적화의 정수를 보여준다.
실험 주제: 효소 기반 DNA 합성 (enzymatic DNA synthesis)
본 연구는 enzymatic de novo DNA synthesis를 사용하여 AutoDNA의 다중 목표 자율 최적화(multi-objective autonomous optimization) 기능을 입증하였다.
이 방식은 기존의 phosphoramidite 합성에 비해 더 우수한 결합 효율(coupling efficiency), 순한 반응 조건(milder reaction conditions), 그리고 더 긴 DNA 가닥 생성 능력을 제공한다.
핵심 과정은 다음의 두 단계가 교대로 반복되는 구조이다:
- TdT 효소에 의해 촉매되는 단일 뉴클레오타이드 연장 – growing strand에 reversible terminator를 추가
- 디블로킹(deblocking) – 보호기를 제거하여 다음 뉴클레오타이드 결합을 가능하게 함
이러한 반복적인 합성 과정은 맞춤형 염기서열 생성을 가능하게 하지만,
표준화되지 않은 시약과 반응 조건으로 인해 최적화 대상의 탐색 공간(search space)이 매우 크고 복잡해진다.
AutoDNA는 최대 수율(maximum yield)과 최소 실행 시간(minimal execution time)을 동시에 달성하기 위해, 반복적(iterative) 실험 워크플로우를 자동으로 생성하였다.
먼저 Experiment Planner Agent (EPA)는 문헌 조사 에이전트(LRA)의 도움을 받아, 세척 단계에 사용할 buffer 후보로 lysis buffer와 B&W buffer 두 가지를 선택하였다. 이후 하드웨어 기반 실험 피드백을 통해 B&W buffer가 더 적합하다는 결론에 도달해 이후 실험에 적용하였다.
하지만 여전히 합성 수율(synthesis yield)이 기대에 못 미치자(suboptimal), EPA는 가설 제안 에이전트(HPA)와 협업하여 최적화 전략을 강화하였다.
이 과정에서 다음과 같은 요소들이 조정되었다:
- Tween-20 계면활성제 도입
- CoCl₂, TdT 효소, reversible terminator 농도 증가
이 조정을 통해 수율은 98% 이상으로 증가하였다. 이후 EPA는 반응 시간 단축에 초점을 맞췄으나, 이는 수율 감소로 이어졌고, 에이전트는 최적화를 중단하였다.
이처럼 AutoDNA는 buffer, surfactant, 반응 시간, 시약 농도 등 다양한 최적화 차원을 탐색하며, 각 실험의 피드백을 반복적으로 반영하는 과정을 거쳤다. 기존 접근법들이 미리 정의된 최적화 공간(predefined optimization spaces)이나 고정된 실험 워크플로우(fixed workflows)에 의존하는 반면, AutoDNA는
에이전트 기반으로 최적화 탐색 공간을 직접 구성하고 확장한다.
→ 이로써 사람의 수동 개입 없이, 인간이 놓칠 수 있는 최적화 요인을 자동으로 발굴할 수 있다.
에이전트들이 반복적으로 수행한 자율 최적화 이후, 지정된 염기서열(3'-GTGTGTGT-5')에 대해 PAGE 분석을 실시한 결과,
step별 평균 수율은 97.7%로 나타났으며, 이는 이전에 수동으로 최적화된 결과와 유사한 수준이었다 (Fig. 3d).
더나아가, Nanopore sequencing을 사용하여 합성된 DNA의 error profile을 분석한 결과, 주된 오류는 삭제(deletion)로 전체 오류의 2.35%를 차지했다.
저자들은 이 오류가 자성 비드의 응집(magnetic bead aggregation)에서 기인했을 가능성이 있다고 추정하였다.
그 외 오류율은 삽입(insertion)이 0.25%, 치환(substitution)이 0.12%였다 (Fig. 3e).
이러한 결과는 AutoDNA가 복잡한 최적화 탐색 공간(search space)을 에이전트 주도 하에 자율적으로 탐색하며, multi-objective DNA synthesis 작업에서 기존 수작업 방식에 필적하는 성능을 달성할 수 있음을 보여준다.
요약)
1. 탐색 공간 설계까지 포함한 진짜 ‘자율 최적화’ 구현
- 기존 시스템은 사람이 미리 설정한 매개변수 범위 내에서만 최적화가 이루어졌음.
- AutoDNA는 에이전트가 실험 대상(search space)을 스스로 정의하고 수정하며 탐색.
- → 즉, 사람이 인지하지 못했거나 고려하지 않았을 수도 있는 새로운 변수 차원까지 최적화에 포함할 수 있음.
2. 모듈형 에이전트 협업을 통한 유연한 전략 변경
- EPA, LRA, HPA가 순차적으로 등장하며 문제를 해결함.
- 단순히 buffer를 고르는 초기단계 → 성능 미달시 가설 생성 및 실험 설계 수정.
- → 고정된 파이프라인이 아닌 상황에 따라 전략을 동적으로 조정하는 구조.
3. 실제 실험 장비와의 연동 및 반복적 피드백 적용
- 결과에 따라 다음 실험이 조정되는 진정한 의미의 closed-loop optimization이 이루어졌음.
- 이건 단순 시뮬레이션이 아니라, 실제 하드웨어 실험에 피드백을 적용한 사례.
4. 전문가 수준의 성능에 필적하는 자율 실험 가능성 확인
- PAGE 분석에서 97.7% 수율 달성 → 기존 수동 최적화 결과와 통계적으로 유의한 차이 없음
- Nanopore 분석 통해 결과 신뢰도 및 오류 특성까지 정량적으로 평가
- → "AutoDNA는 단순 자동화가 아니라, 연구자 수준의 실험을 대신 수행할 수 있다"는 근거 제시
Concurrent multi-request support
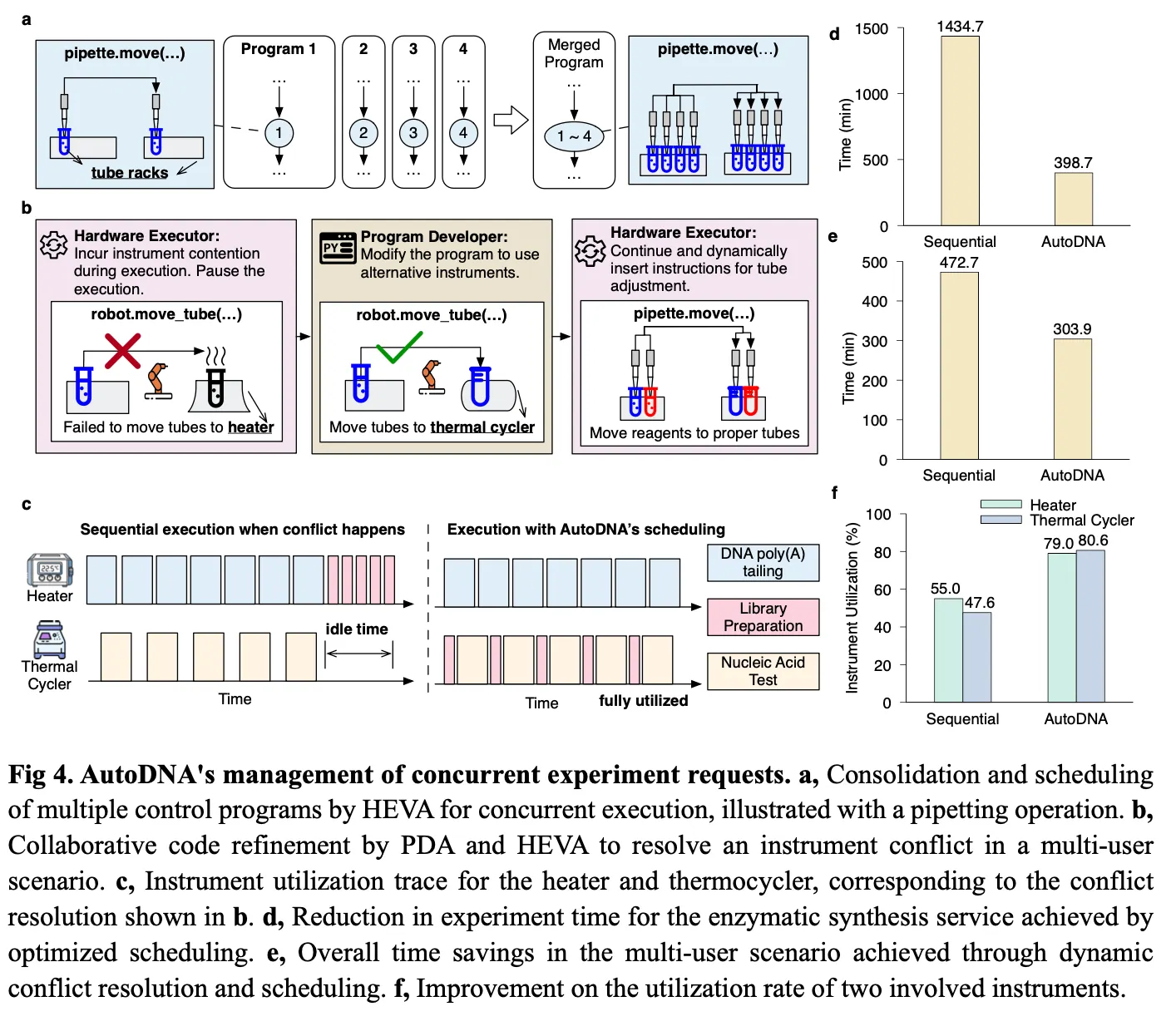
AutoDNA의 자율 장비 관리: 시나리오 1 - 단일 사용자, 병렬 요청 처리
AutoDNA는 단일 사용자(single user)가 동시에 여러 실험 요청을 보낼 때의 처리 능력을 평가하였다.
-
첫 번째 iteration에서, Experiment Planner Agent (EPA)는 두 가지 유사하고 실행 가능한 실험 절차를 생성하였다.
-
이후, Hardware Executor & Validator Agent (HEVA)는 이 두 절차를 병합(merge)하여 병렬 실행(concurrent execution)이 가능하도록 구성하였다.
-
이때, Program Developer Agent (PDA)는 각 실험에 대해 단지 ‘어떤 시약을 옮겨야 하는지’만 추상적으로 지정하고,
-
HEVA는 이를 물리적 실험 환경(가로 배열된 튜브 세트)에 맞게 매핑하여,
multi-channel pipetting을 통한 단일 동작(unified motion)으로 여러 실험을 병렬 수행할 수 있도록 구성했다.
-
이 병렬화 전략은 세척(washing), 첨가(addition), 보호기 제거(deprotection) 등 후속 단계까지 확장되었다.
⇒ 결과적으로, HEVA의 최적화된 스케줄링 덕분에 전체 탐색 시간은 약 3.6배 단축되었으며,
1434.7분 → 398.7분으로 감소하였다 (Fig. 4d).
AutoDNA의 자율 장비 관리: 시나리오 2 - 다중 사용자 동시 요청 처리
두 번째 시나리오는 동적인 다중 사용자 환경(multi-user environment)을 가정하여 수행되었다.
여기서 세 명의 사용자는 각각 다음과 같은 실험을 동시에 요청했다:
- DNA poly(A) tailing
- DNA library preparation
- Nucleic acid test
초기 단계에서, Program Developer Agent (PDA)는 library preparation 실험을 위해 heater를 사용하는 등온 반응(isothermal reaction) 절차를 스크립팅하였다.
하지만 Hardware Executor & Validator Agent (HEVA)는 해당 heater가 이미 poly(A) tailing 실험에 할당되어 있음을 감지하였다.
이에 따라 PDA는 HEVA로부터 피드백을 받은 후,
하드웨어 추상화(hardware abstraction)를 활용해 heater와 thermocycler 간의 기능적 등가성(functional equivalence)을 인식하고,
사용 가능한 thermocycler를 활용하도록 코드를 재작성(re-scripted)하였다 (Fig. 4b).
- *장비 활용도 추적 결과 (Fig. 4c)는 이러한 동적 스케줄링(dynamic scheduling)**이 heater와 thermocycler 모두의 효율성을 향상시켰음을 보여준다 (Fig. 4f).
- 또한, 이 방식은 큐 기반(serial, queue-based) 실행 방식에 비해 총 168.8분의 시간 절약을 달성하였다 (1434.7분 → 398.7분, Fig. 4e).
Service Integration for DNA Storage
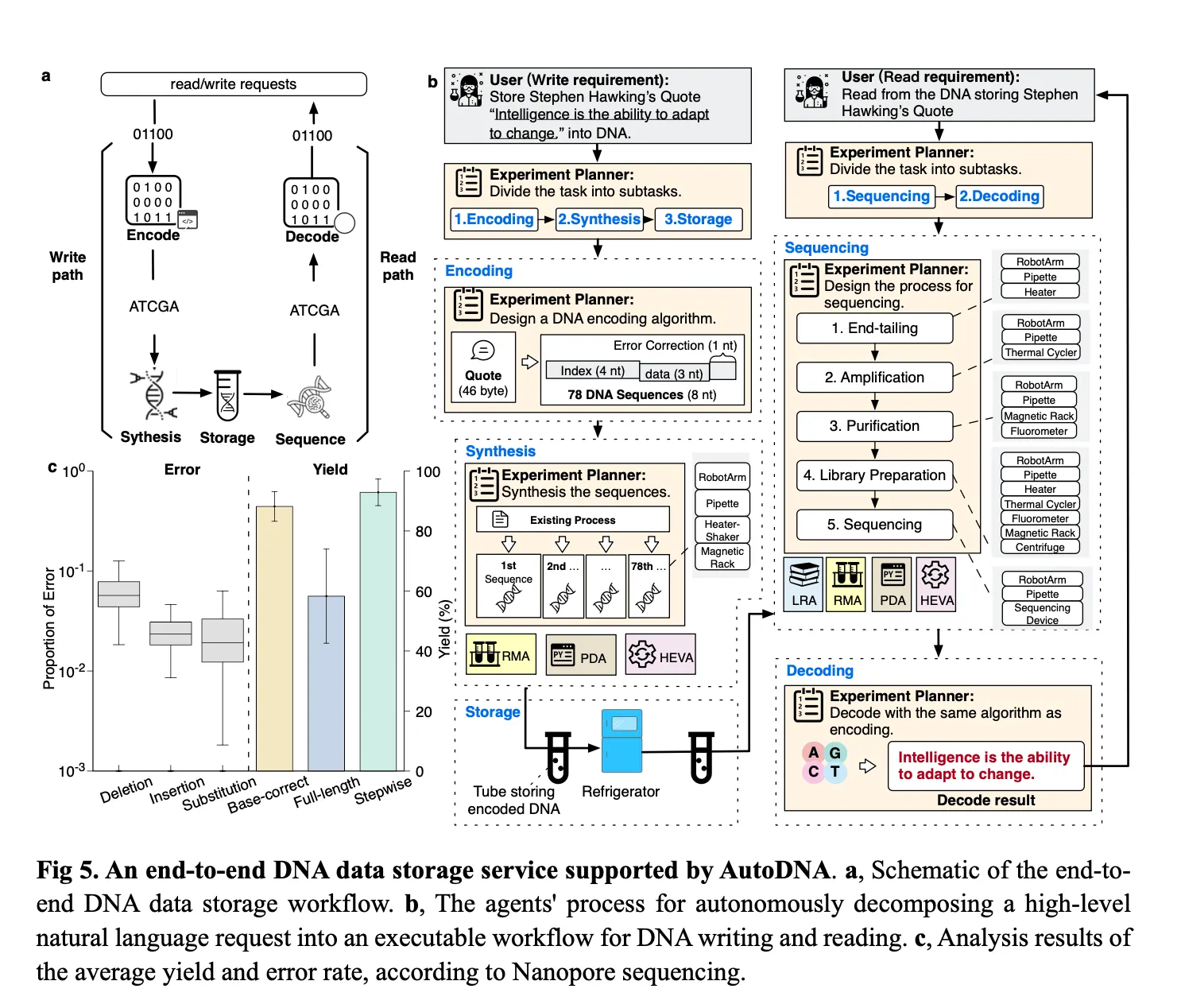
AutoDNA는 복잡한 실험 워크플로우를 자율적으로 하위 작업(subtasks)으로 분해하고 실행할 수 있다.
이러한 처리 능력은 end-to-end DNA 데이터 저장 서비스 사례를 통해 시연되었다.
DNA는 유전 정보를 저장하는 매체로서, 높은 정보 밀도, 장기적 안정성, 낮은 에너지 소비라는 장점 덕분에 대규모 데이터 저장을 위한 차세대 저장 기술로 주목받고 있다.
전형적인 시험관 내(in vitro) DNA 저장 워크플로우는 다음과 같은 5단계로 구성된다
- Encoding – 디지털 정보를 염기서열(nucleotide sequences)로 변환
- Writing – 지정된 DNA 가닥을 de novo 합성
- Storing – 합성된 DNA를 보존
- Reading – 시퀀싱을 통해 염기서열 정보 회수
- Decoding – 시퀀싱된 데이터를 원래의 디지털 포맷으로 복호화
또한, 이 전체 흐름은 시퀀싱 전 라이브러리 준비(library preparation)와 같은 중간 단계(intermediate step)도 포함한다.
AutoDNA는 Fig. 5b에 나타난 DNA 데이터 저장 전체 워크플로우를 자율적으로 실행하였다.
사용자가 데이터와 동작 종류(read/write)만을 지정하면,
Experiment Planner Agent (EPA)가 해당 요청을 여러 하위 작업(subtasks)으로 자동 분해한다.
이 중 encoding과 decoding 단계는 in silico에서 수행되며, EPA가 자체 지식을 기반으로 처리한다.
반면, wet-lab 단계(합성과 시퀀싱)는 앞서 설명된 방식대로 agent들이 처리한다:
문헌 검색, 시약 질의, 절차 생성, 코드 작성, 하드웨어 실행이 포함된다.
특히 de novo DNA 합성 절차는 이미 이전 실험에서 생성되었기 때문에,
해당 절차는 시스템의 knowledge base에 저장되어 있으며,
agent는 writing 단계에서 이를 직접 검색(retrieve)하여 실행(execute)할 수 있다.
AutoDNA는 시약 보충을 제외하고는 어떠한 수동 개입도 없이, 총 162.9시간에 걸쳐 read-write cycle 전체를 자율적으로 수행하였으며,
이 과정에서 총 25개의 장비와 9,365개의 하드웨어 단위 스텝을 조율하였다(각 스텝은 atomic service 호출 1회 기준).
실험 결과, 합성된 78개의 모든 DNA 가닥이 높은 정확도로 읽혔고, 저장된 정보는 자동으로 복구 및 디코딩되어 원래 작성된 콘텐츠와 완전히 일치하였다.
이전의 효소 기반 합성과 마찬가지로, 가장 두드러진 오류는 deletion이었으며, 이는 자성 비드 응집(magnetic bead aggregation) 문제 개선을 통해 향후 오류율을 낮출 수 있을 것으로 기대된다.
Disussion
AutoDNA는 AI-native 자율 실험 플랫폼(AI-native autonomous experiment laboratory)을 도입하여,
핵산 실험(nucleic acid experiments)과 같은 복잡한 과학 실험도 인간의 개입 없이 실행 가능하게 만들었다.
이 시스템은 사용하기 쉬운 자연어 인터페이스(Natural Language Interface, NLI)를 통해,
비전문가(non-expert)도 end-to-end 실험 서비스를 수행할 수 있도록 지원한다.
AutoDNA는 20개 이상의 실험 장비를 매끄럽게 연동하고, 실험 절차를 자율적으로 최적화함으로써,
- 전문가가 수동으로 최적화한 실험과 동등한 수준의 수율을 달성했고,
- 기존 시스템에 비해 병렬 처리량(parallel throughput)을 3배 향상시켰다.
이러한 기능은 9,000개 이상의 개별 하드웨어 작업(discrete hardware steps)을 포함하는 통합 실험 서비스를 가능하게 했다.
기존 접근법은 화학자가 직접 실험 절차나 의사결정 규칙(heuristics)을 정의해야 했다.
반면, 우리의 AI-native 접근법은 모델, 실험, 장비를 함께(co-design) 설계하는 구조를 바탕으로, 완전한 자율 실험(fully autonomous experimentation)을 실현할 수 있었다.
이러한 자율성을 가능하게 한 3가지 핵심 혁신은 다음과 같다.
1. 디지털-물리 세계를 잇는 에이전트 기반 인터페이스
Program Developer Agent(PDA)와 Hardware Executor & Validator Agent(HEVA)는
AI 모델과 물리적 장비 간의 지능적 연결 지점을 형성한다.
- 이 robust 인터페이스를 통해, 에이전트가 실험 장비의 운용을 이해하고, 실제 실험을 자동화할 수 있는 기반이 마련된다.
2. 과학적 방법론 기반의 다중 에이전트 아키텍처
다중 에이전트 구조는 과학적 방법론 원칙을 따른다.
대형언어모델(LLM)의 추론 능력을 활용해 문헌에서 지식 추출. 실험 가설 수립을 수행한다.
이로 인해 사람이 미리 정의한 heuristic 없이도, 풍부한 최적화 차원(richer optimization space)을 다룰 수 있으며,
설계–실험–최적화(closed-loop design-experiment-optimize) 사이클이 가능해진다.
3. 동적 자원 관리 기반의 동시 실험 처리
여러 실험 요청이 동시에 발생할 때, 에이전트는 장비 상태를 동적으로(실시간으로) 모니터링하여
중복 없는 동시 실험 실행(concurrent orchestration)을 수행한다.
이를 통해 장비 사용률과 전반적 실험 처리 효율이 크게 향상된다.
미래 방향
앞으로 AI와 자동화 플랫폼의 공동 설계(co-design)를 더 깊이 탐구할 것이다.
또한 자율 실험의 적용 영역을 신소재 발견과 같은 탐색 기반 과학 분야까지 확장할 계획이다.
궁극적으로는, AI 주도 과학 발견(AI-driven scientific discovery)을 실현하는 것이 목표이며,
동시에 비전문가도 쉽게 접근할 수 있는 실험 환경을 제공할 수 있도록 플랫폼의 범용성과 수용 능력을 확장해 나갈 것이다.
