
Redis에 값을 업데이트하는 Batch ItemWriter의 성능개선 과정을 소개합니다.
Fitdo에는 사용자의 운동점수를 등급으로 계산하여 조회하는 기능이 있습니다.
티어가 필요할때마다 모든 사용자의 운동기록을 조회하고, 계산하고, 정렬하는 것보다 매일매일 배치를 통해 점수를 미리 계산하고, Redis의 sorted set을 이용하여 빠르게 랭킹을 구하는 것이 효과적이라고 생각했습니다.
배치가 돌아갈때마다 Redis를 업데이트하는데, 많은 데이터를 저장해야하는만큼 Bulk insert 메서드가 존재하는지 찾아보았지만, RestTemplate에 구현된 메서드는 없었습니다.
Redis의 요청/응답 과정
Redis는 TCP 프로토콜을 이용한다. 따라서 요청/응답 모델을 사용한다.
1. 클라이언트가 서버에 쿼리를 보내고, 서버는 일반적으로 Blocking 방식으로 소켓을 통해 읽는다.
2. 서버가 명령을 처리하고 응답을 다시 클라이언트로 보낸다.
따라서 1000개의 데이터를 Redis에 저장하기 위해서는 1000번의 RTT과정이 필요하여, 요청이 많아진다면 배치 지연의 원인이 될수 있을것이라 생각했습니다.
해결과정
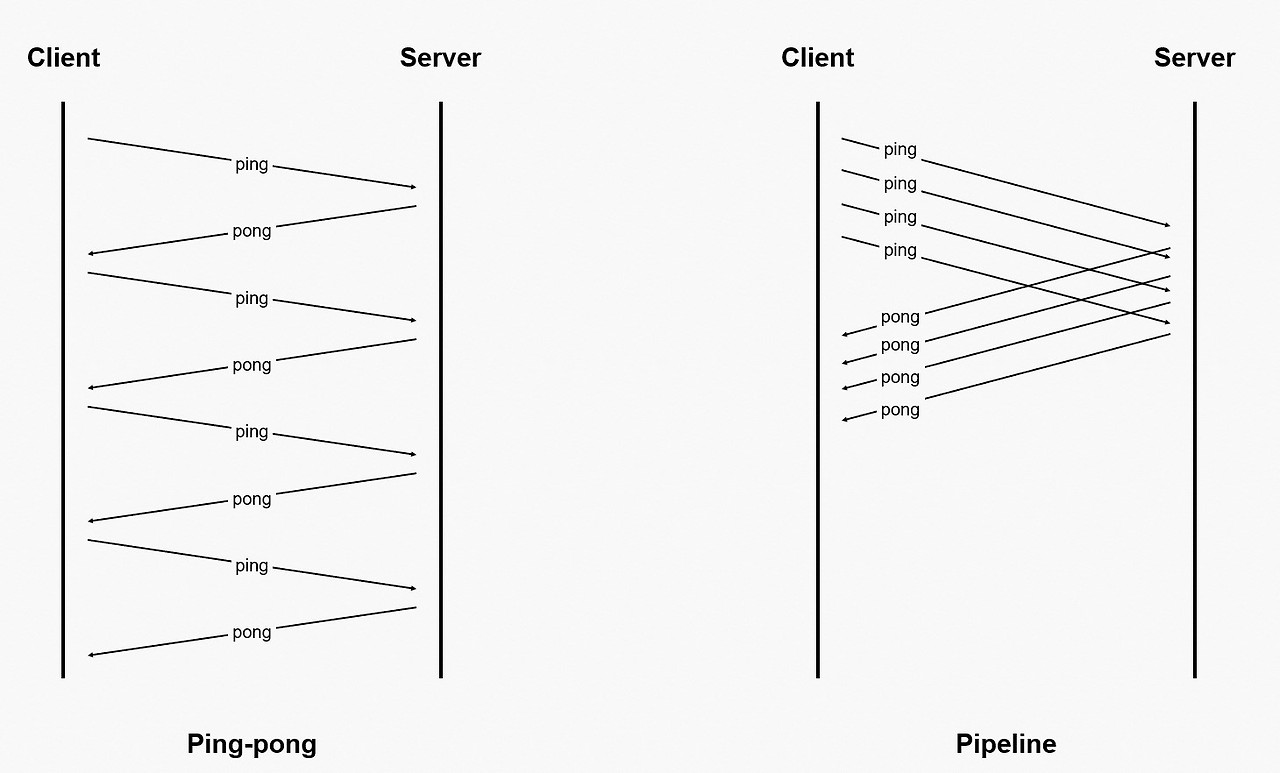
Redis의 Pipelining기능을 이용하면 이전 요청에 대한 응답을 받지 않았더라도, 비동기적으로 다음 요청을 보낼수 있습니다.
RedisTemplate의 executePipelined메서드를 이용하여 Pipelining을 사용할수 있습니다.
단순히 성능향상이 RTT횟수 차이뿐만 아니라, 통신하며 Redis 서버에서 일어나는 소켓IO작업의 횟수가 줄어드는 것도 성능개선의 이유라고합니다!
RedisItemWriter
public class RedisSortedSetItemWriter implements ItemWriter<UserScoreRow> {
private final RedisTemplate<String, String> redisTemplate;
public RedisSortedSetItemWriter(RedisTemplate<String, String> redisTemplate) {
this.redisTemplate = redisTemplate;
}
@Override
public void write(Chunk<? extends UserScoreRow> chunk) throws Exception {
redisTemplate.executePipelined((RedisCallback<Object>) redisConnection -> {
for (UserScoreRow item : chunk.getItems()) {
redisConnection.zAdd("userScores".getBytes(), item.getScore(),
String.valueOf(item.getUserId()).getBytes());
}
return null;
});
}
}결과
| 데이터수 | 적용전 | 적용후 |
|---|---|---|
| 10 | 62ms | 62ms |
| 100 | 70ms | 59ms |
| 500 | 138ms | 91ms |
| 1000 | 155ms | 80ms |
| 5000 | 437ms | 174ms |
성능을 비교했을때 확연한 차이가 보이는 것을 확인할수 있습니다. 저장하는 객체, 캐시서버의 성능에 따라 달라질수 있으니 도입전 테스트하는 과정이 필요하겠지만, 도입을 고려해볼만한 개선으로 생각됩니다.
주의점
원자성 보장X
Redis의 가장 큰 특징은 싱글스레드라는 점으로 명령어간의 원자성을 보장해줍니다. 하지만 Pipeline간의 원자성을 보장해주진 않습니다. 따라서 같은 데이터에 대해 여러 Pipelining을 사용하면 데이터 불일치가 발생할수 있습니다.
Fitdo에서는 해당 데이터에 대한 추가적인 연산이 없어 Pipelining을 적용하였습니다.
