스트림이란?
스트림이란 컬렉션의 저장 요소를 하나씩 참조하여 람다식으로 처리할 수 있도록 해주는 반복자이다.
iterator와 비슷하다고 생각이 들 수도 있다. 하지만 iterator는 자체적으로 반복하지 않고 외부의 반복자가 필요하다. 반면에 스트림은 내부 반복자로 람다식으로 처리하기 때문에 자체적으로 멀티 스레드로 병렬 처리하여 더 좋은 성능으로 작업을 수행할 수 있다.
스트림 파이프라인
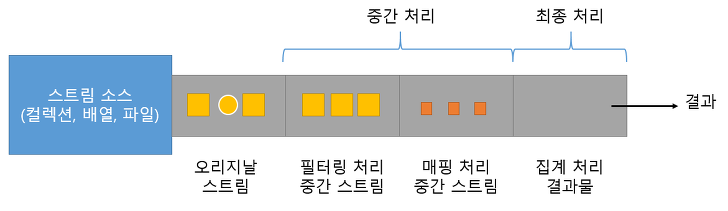
스트림은 위의 그림과 같은 파이프라인을 구성하여 원하는 결과를 도출할 수 있다. 초기 스트림에서 필터링 과정을 거치면 특정 데이터만 필터링한 중간 스트림으로 반환된다. 이 중간 스트림이 매핑 과정을 거치면 각 요소를 특정 타입의 특정 데이터로 새롭게 매핑한 스트림으로 반환된다. 최종적으로는 집계 처리 과정을 거침으로써 최종 스트림의 결과로 원하는 타입의 데이터를 반환받을 수 있다.
스트림 파이프라인에서는 중간 처리 과정과 최종 처리 과정이 구분된다. 최종 처리 과정이 없으면 중간 처리 과정의 모든 작업들이 수행되지 않고 지연(LAZY)된다. 따라서 원하는 결과를 얻기 위해서는 꼭 최종 처리 과정이 필요하다.
간단한 스트림 파이프라인 예제를 살펴보자.
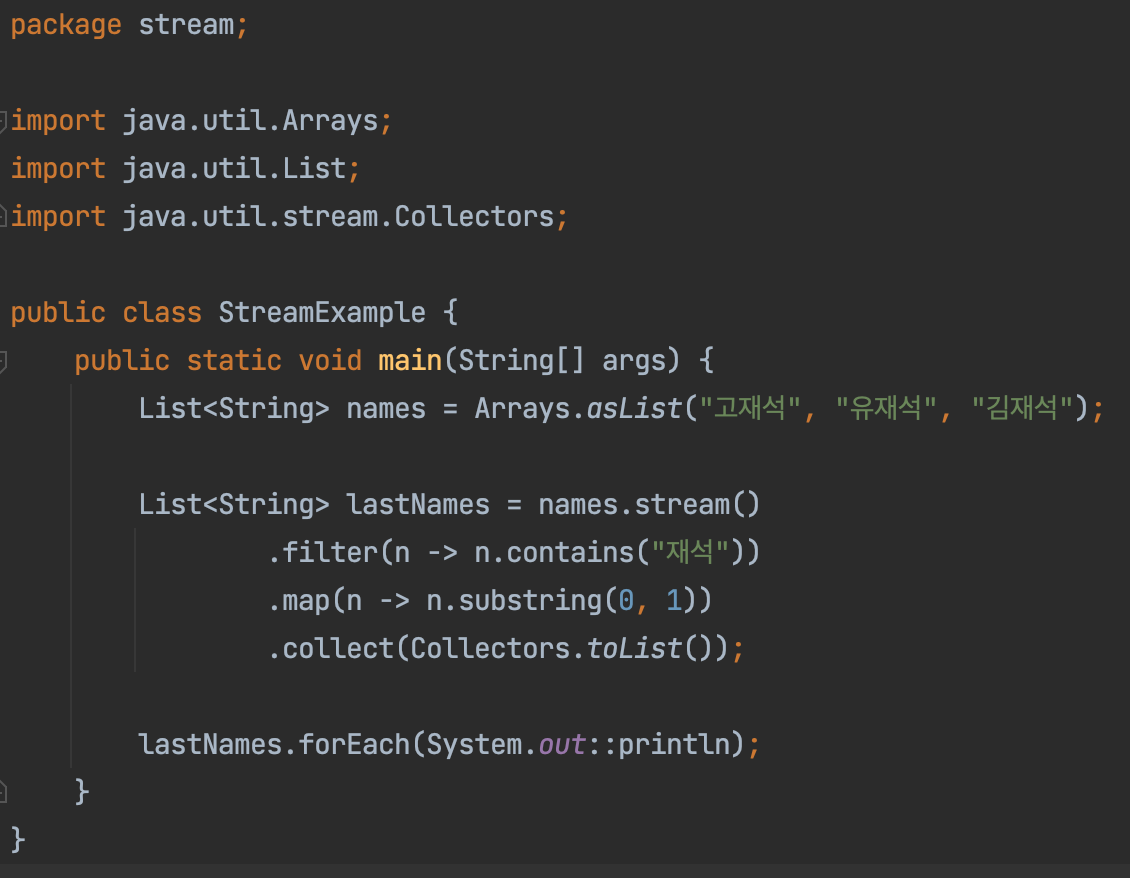
필터링 기법
스트림에서 원하는 데이터만 필터링하는 필터링 과정에서 사용하는 몇 가지 메소드가 있다. 그 중에서도 가장 대표적인 filter(Predicate) 메소드로 한번 알아보자.
filter 메소드의 매개 변수는 Predicate 타입으로 해당 함수형 인터페이스의 구현 객체가 true를 반환하는 요소만 남긴 중간 스트림을 반환한다.
위에서 실습해본 내용으로 확인해보자면 filter 메소드 안의 람다식은 n -> n.contains("재석")이였다. 그렇다면 기존 스트림에서 가지고 있던 문자열 중에 "재석"이라는 문자열을 포함한 문자열만 남긴 중간 스트림을 반환한다. 위의 실습에서는 모든 요소가 재석이라는 문자열을 포함하기 때문에 그대로 반환한다.
매핑 기법
스트림에서 컬렉션의 각 요소를 원하는 포맷이나 타입으로 바꾸는 과정으로 flatMapXXX(), mapXXX(), asXXXStream(), boxed() 등의 메소드를 활용할 수 있다.
flatMapXXX() 메소드는 하나의 요소를 여러 개의 요소로 바꾼 중간 스트림을 반환하는 메소드이다.

위 코드를 보면 flatMap 메소드의 매개변수는 Function 인스턴스를 람다식으로 구현하여 전달된다. 이 람다식은 String 타입의 데이터를 Stream 타입의 데이터로 반환하는 람다식이다. 이 Stream 타입으로 매핑된 각 데이터는 flatMap 메소드가 하나의 중간 스트림으로 반환한다.

위의 코드를 보면 mapToInt 메소드로 기존의 Student 타입이던 각 요소를 int타입으로 매핑하여 다시 반환한다.
정렬 기법
스트림의 각 요소를 특정한 기준으로 정렬하기 위해서는 Comparable 인터페이스를 구현해야한다. 이렇게 구현한 내용을 정렬하기 위해서는 아래와 같은 코드를 사용하면 된다.
.sorted();
.sorted((a,b) -> a.compareTo(b));
.sorted(Comparator.naturalOrder());그리고 반대로 정렬하고 싶으면 아래와 같은 코드를 사용하면 된다.
.sorted((a,b) -> b.compareTo(a));
.sorted(Comparator.reverseOrder());집계 기법
스트림에서 필터링하고 매핑과정을 거친 스트림은 최종 처리 단계에서 집계되어 최종 데이터를 반환할 수 있다. count(), sum() 메소드를 제외한 다른 집계 메소드는 Optional 타입으로 결과를 반환한다. 따라서 .orElse(), ifPresent() 메소드 등을 활용하여 NoSuchElementException을 피하는 처리를 해주어야한다. (스트림에 아무 요소 없이 집계되는 것을 생각하면 예외처리가 필요함을 느낄 수 있다.)
집계 기법 중에 커스텀 집계를 활용할 수 있는 reduce() 메소드로 한번 알아보자.
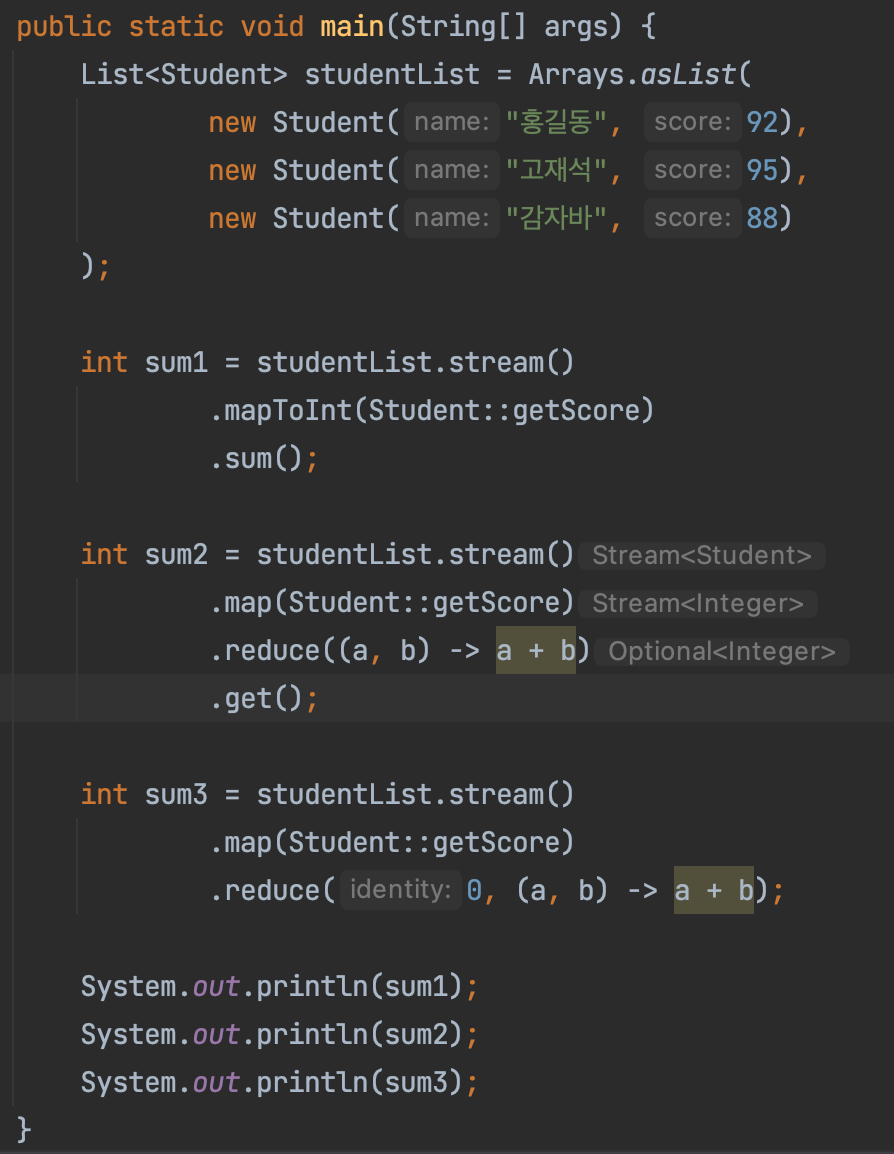
위의 코드를 보면 reduce() 메소드 안에 각 요소를 더하는 람다식을 매개변수로 주었다. 이 경우에는 반환값이 Optional 타입으로 반환되어 .get() 메소드를 추가로 사용했다. reduce 메소드에 두 개의 파라미터를 전달하는 경우에는 첫 파라미터가 identity 값으로 null인 경우를 명시하게끔 되어있다. 이 경우에는 반환 값 타입이 int 타입이다.
수집 기법
collect() 메소드는 필터링과 매핑이 모두 끝난 중간 스트림을 최종 처리하여 다시 컬렉션으로 수집하여 반환하는 메소드이다. 집계는 중간 스트림으로 기본 타입의 집계 결과를 반환하는 것에 비해 수집은 다시 컬렉션이 반환된다.
collect(Collector<T,A,R> collector) 메소드는 매개변수로 Collector 타입의 인스턴스를 전달받는데, 이 매개변수는 T요소를 R에 A가 저장한다는 의미의 제네릭을 가진다. Collectors 클래스에서는 이와 같은 Collector 타입의 반환값을 가지는 정적 메소드를 제공한다. toList(), toSet(), toMap(keyMapper, valueMapper)과 같은 메소드를 제공하여 수집된 컬렉션을 반환하게끔 할 수 있고, toCollection(Supplier<Collection<T>>)으로 Supplier가 제공하는 Collection에 저장할 수도 있다.
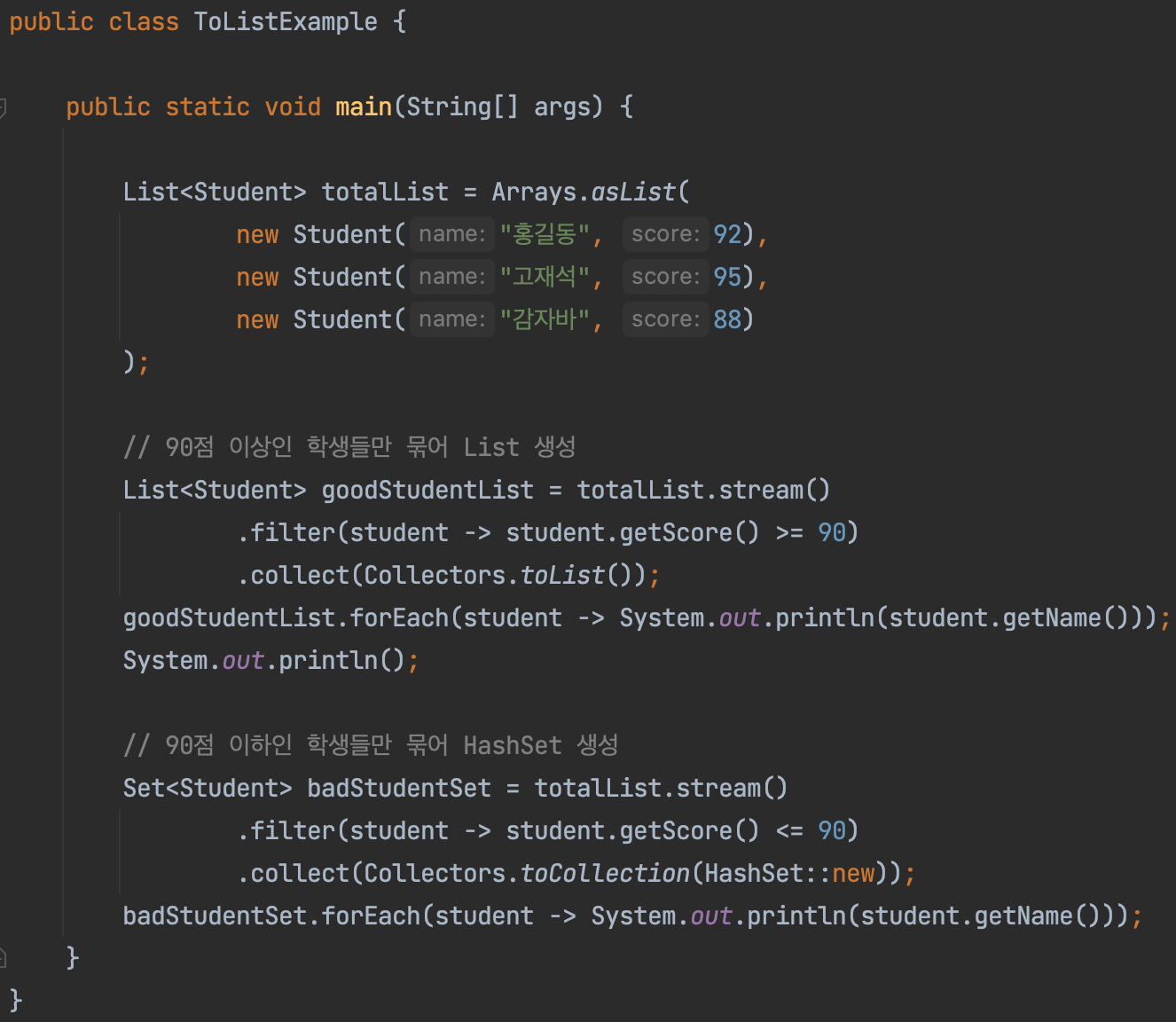

위의 코드를 보자. 90점 이상의 학생들만 필터링한 스트림을 List로 collect했다. 이 과정에서 Collectors 클래스의 정적 메소드인 toList() 메소드를 활용했다.
그리고 90점 이하의 학생들만 필터링한 스트림을 HashSet으로 collect했다. 이 과정에서는 toCollection() 메소드를 활용했으며 이 때 매개변수로는 HashSet 생성자 참조로 Supplier를 구현했다.
그룹핑해서 수집
그룹핑해서 수집하는 경우에는 무조건 Map 컬렉션에 저장된다. 이 때 반환되는 Map의 Key에는 그룹핑의 기준이 되는 데이터가 저장되고, Value에는 기준에 따라 분류된 데이터들이 컬렉션에 담겨 저장된다.
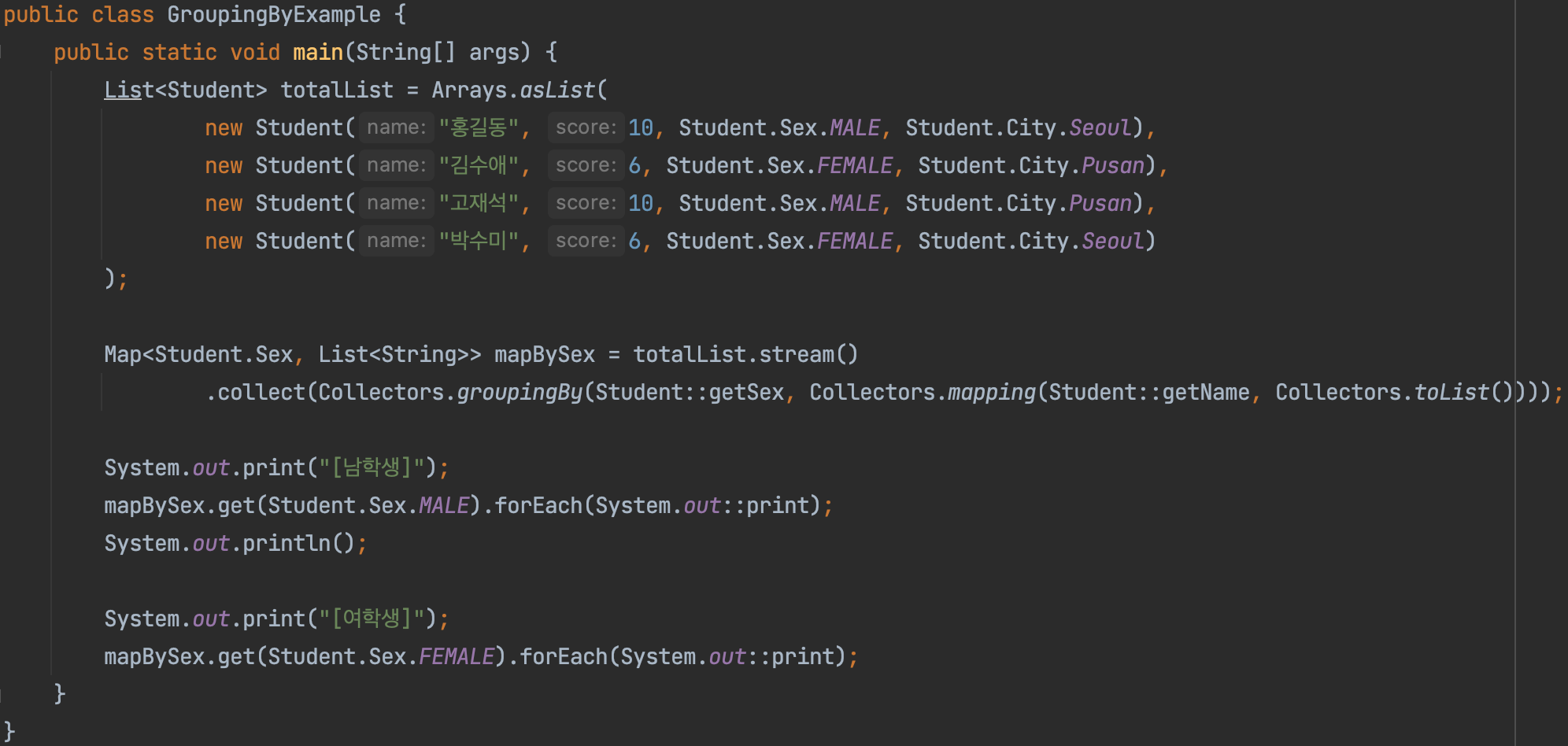

위의 코드를 보면 collect 메소드의 매개변수로 Collectors의 정적 메소드인 groupingBy 메소드의 반환값이 주어진다. 이 groupingBy 메소드의 첫번째 매개변수는 그룹핑 기준이 되는 데이터를 매핑하는 메소드를 참조하여 주어졌다. 그리고 두 번째 파라미터는 다시 Collections 클래스의 정적 메소드인 mapping 메소드가 주어졌다. 이 메소드는 groupingBy되어 Value에 저장될 데이터를 매핑하는 메소드이다. 여기서는 Student 객체를 다시 String으로 매핑하여 리스트로 저장함을 명시했다.
