컬렉션 프레임워크?
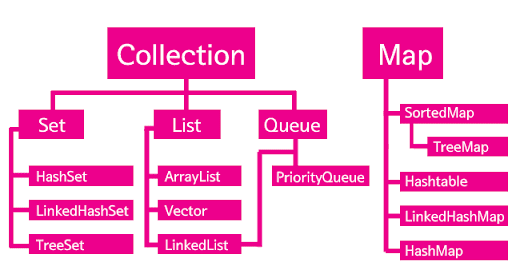
배열은 기본적으로 크기와 타입이 고정적이기 때문에 동적인 작업을 위한 자료구조로는 부적합하다. 자바에서는 이러한 배열을 문제점을 해소하기 위해 기본적인 자료구조 형태의 컬렉션 프레임워크를 지원하고 있다.
컬렉션 프레임워크는 특정 객체들을 저장, 검색, 삭제 등의 작업을 수행할 수 있는 역할을 한다. 컬렉션 프레임워크에서 제공하는 기본적인 인터페이스로는 List, Set, Map 등이 있다. 이 인터페이스들을 기준으로 각 컬렉션 클래스를 알아보자.
List
리스트는 저장된 객체들을 순서와 중복을 허용하는 컬렉션 인터페이스이다. 리스트 인터페이스를 구현하는 클래스로는 ArrayList, LinkedList, Vector가 있다.
ArrayList
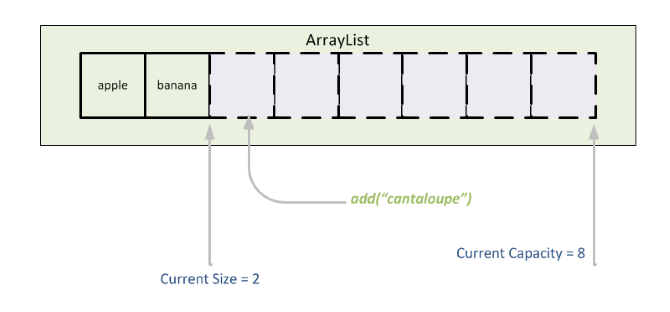
ArrayList는 객체의 참조 값을 순서대로 저장하는 컬렉션 클래스이다. 기본 생성자로 ArrayList를 생성하면 기본적으로 10개의 용량을 가진채로 생성된다. 여기서 추가적으로 데이터가 add된다면 동적으로 용량이 변한다.
특정 인덱스의 데이터를 삭제하는 경우에는 인덱스 관리를 위해 삭제된 데이터 이후의 인덱스를 가진 모든 데이터의 인덱스를 앞으로 당겨줘야한다. 데이터를 중간에 삽입하는 경우도 마찬가지이다.
이와 같이 인덱스로 관리된다는 특징 때문에 ArrayList는 검색 작업에는 강점을 보이나, 삭제, 삽입 작업에는 비효율적이다.
Vector
Vector는 ArrayList와 동일한 내부 구조를 가지고 있다. 하지만 ArrayList와 다른 점은 Vector는 메소드들이 동기화되어 있기 때문에 멀티 스레드 작업 시 Vector 인스턴스는 Thread Safe하게 사용할 수 있다.
LinkedList
LinkedList는 ArrayList와 사용 방법은 비슷하지만 내부 구조는 큰 차이를 가지고 있다. ArrayList는 내부적으로 인덱스를 가지고 객체를 관리하지만, LinkedList는 인접 참조를 활용해서 객체를 관리한다.
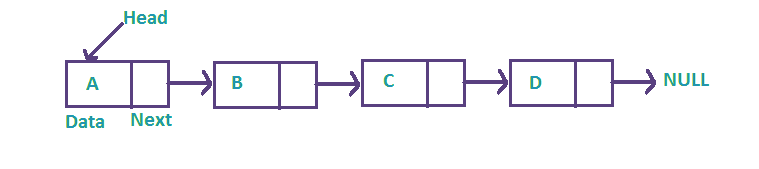
위의 그림을 보면 쉽게 이해할 수 있다. 각 노드는 객체의 참조값(데이터) 뿐만 아니라 다음 노드를 가르키는 참조값도 가지고 있다. 따라서 각 노드의 순서는 위와 같은 링크로 관리된다.
LinkedList는 검색 시 효율이 많이 떨어진다. 인덱스로 관리하는 ArrayList는 주어진 인덱스로 바로 접근할 수 있지만, LinkedList는 맨 처음 노드부터 순서대로 모든 노드를 방문해서야 원하는 노드까지 접근할 수 있다. 하지만 새로운 노드를 삽입하거나 삭제하는 경우에는 중간에 노드를 삽입 또는 삭제하고 양 옆의 노드의 인접 참조값만 수정해주면 손쉽게 작업을 수행할 수 있다.
이와 같이 인접 참조값으로 관리된다는 특징 때문에 LinkedList는 검색에는 비효율적이지만 삽입과 삭제에는 효율적으로 작업을 수행할 수 있다.
Set
Set은 List와 달리 순서와 중복을 허용하지 않는 컬렉션 인터페이스이다. 순서가 없기 때문에 인덱스를 매개변수로 가지는 메소드는 존재하지 않는다. 따라서 전체 객체를 검색하는 경우 Iterator를 활용해서 검색 작업을 수행한다. Set 인터페이스를 구현하는 컬렉션 클래스는 HashSet, LinkedHashSet, TreeSet이 있다.
HashSet
HashSet은 객체들을 순서없이 저장하고, 동일한 객체는 중복 저장하지 않는다. 여기서 중복 체크를 할 때 객체 사이의 동등 비교작업을 수행한다. 동등 비교 작업은 hashCode() 반환값 비교, equals() 반환값 비교를 순서대로 수행하고 동등한지 아닌지 결과를 도출한다.
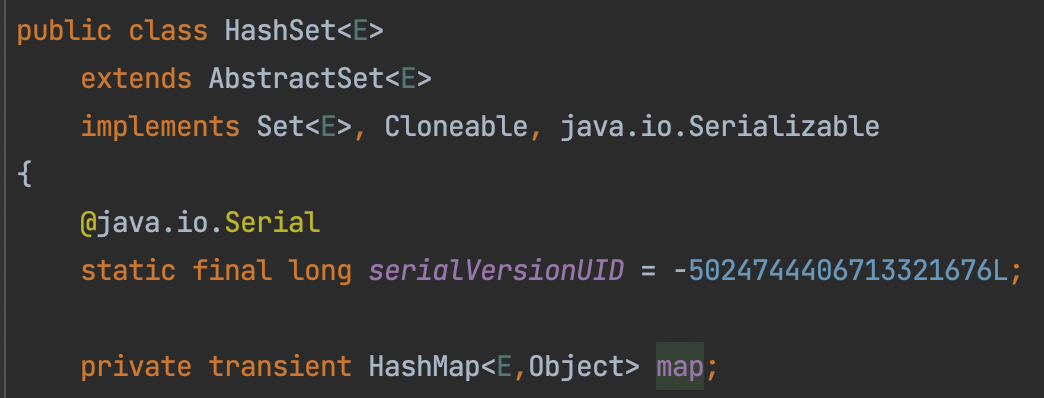
인텔리제이에서 HashSet 클래스에 접근해보았는데 내부적으로 HashMap 인스턴스를 하나 가지고 있고 Key에 데이터, Value에 더미 오브젝트를 넣어서 사용하고 있었다. iterator를 반환하는 경우에도 이 HashMap 인스턴스의 KeySet을 반환하는 방식으로 메소드가 구현되어 있었다.
LinkedHashSet
LinkedHashSet은 객체들의 저장 순서대로 반환하는 컬렉션 클래스이다. 클래스 내부 구조를 살펴보았더니 HashSet 클래스를 상속받고 있었고 모든 생성자도 super()메소드로 HashSet의 생성자를 가져다가 썼다. 그렇다고 다른 메소드가 오버라이딩 되어있지도 않아서.. 객체 저장 순서를 어떤 식으로 보존하는지 확인하기가 어려웠다. 결국 구글링으로 구조를 찾아보았는데 아래와 같은 그림을 찾을 수 있었다.

이 그림에 따르면 결국 Linked라는 접두어가 붙은 대로 각 노드가 인접 참조값을 가지고 순서를 유지하는 방식이었다.
TreeSet
TreeSet은 이진 트리를 기반으로 한 Set 컬렉션이다. TreeSet에서도 각 노드는 앞 뒤 노드의 인접 참조값을 가진다. 여기서 객체를 저장할 때 자동으로 정렬이 되는데 root를 기준으로 부모 노드보다 큰 경우 오른쪽, 작은 경우 왼쪽 노드로 나아가면서 정렬된다.
Map
Map 컬렉션 인터페이스는 Key와 Value로 이루어진 Entry를 저장하는 구조를 가지고 있다. Key, Value는 객체로 저장되며 키는 중복이 허용되지 않는다. Map 컬렉션에는 HashMap, HashTable, LinkedHashMap, Properties, TreeMap 등이 있다.
HashMap
HashMap은 저장된 Entry의 Key 중복을 허용하지 않는다. 따라서 Entry를 저장할 때 Key의 동등 비교 작업이 선행된다. 이 동등 비교 작업은 HashSet과 같다. 먼저 hashCode() 반환값을 비교하고 equals() 반환값을 비교한다.
HashTable
HashTable은 HashMap과 동일한 내부 구조를 가지고 있다. 유일한 차이점은 HashTable의 메소드들은 동기화되어 있다는 것이다. 이는 ArrayList와 Vector의 관계와 비슷하다. 따라서 HashTable은 Thread Safe한 작업이 필요한 경우에 사용된다.
