그리드 탐색(GridSearchCV)
하이퍼파라미터 조합을 찾을때까지 수동으로 하이퍼파라미터를 조정하는것은 시간적 소요가 많이걸린다. 그래서 사이킷런의 GridSearchCV를 사용하여 탐색하고자 하는 하이퍼파라미터와 시도해볼 값을 지정하기만 하면 된다. 그러면 가능한 모든 하이퍼파라미터 조합에 대해 교차 검증을 사용해 평가하게 됩니다.
GridSearchCV 예제 코드
from sklearn.model_selection import GridSearchCV param_grid = [ # 하이퍼파라미터 12(=3×4)개의 조합을 시도합니다. {'n_estimators': [3, 10, 30], 'max_features': [2, 4, 6, 8]}, # bootstrap은 False로 하고 6(=2×3)개의 조합을 시도합니다. {'bootstrap': [False], 'n_estimators': [3, 10], 'max_features': [2, 3, 4]}, ] rf = RandomForestRegressor(random_state=42) # 다섯 폴드에서 훈련하면 총 (12+6)*5=90번의 훈련이 일어납니다. grid_search = GridSearchCV(rf, param_grid, cv=5, scoring='neg_mean_squared_error', return_train_score=True, n_jobs=-1) grid_search.fit(data_prepared, labels)
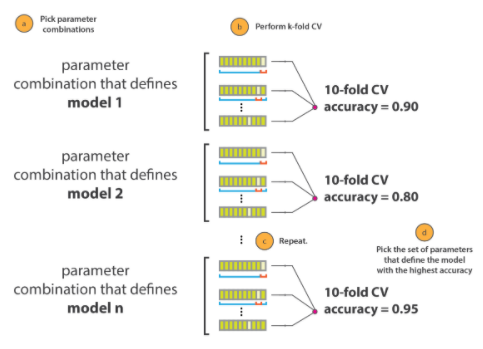
GridSearchCV 최적파라미터 결과
grid_search.best_params_ grid_search.best_estimator_ ##########################[결과]################################# {'max_features': 6, 'n_estimators': 30} RandomForestRegressor(max_features=6, n_estimators=30)
GridSearchCV 평가점수 결과
cv_result=grid_search.cv_results_ for mean_score,params in zip(cv_result['mean_test_score'],cv_result['params']): print(np.sqrt(-mean_score),params) ##########################[결과]############################### 63740.98319255503 {'max_features': 2, 'n_estimators': 3} 55450.174005185574 {'max_features': 2, 'n_estimators': 10} 53204.68614235501 {'max_features': 2, 'n_estimators': 30} 60687.25018368089 {'max_features': 4, 'n_estimators': 3} 53132.5866268961 {'max_features': 4, 'n_estimators': 10} 50442.638838299084 {'max_features': 4, 'n_estimators': 30} 58636.62151970057 {'max_features': 6, 'n_estimators': 3} 52632.733175513284 {'max_features': 6, 'n_estimators': 10} 49795.41803045568 {'max_features': 6, 'n_estimators': 30} 59273.463071358856 {'max_features': 8, 'n_estimators': 3} 52051.84993579092 {'max_features': 8, 'n_estimators': 10} 49977.91277723269 {'max_features': 8, 'n_estimators': 30} 62030.95505841916 {'bootstrap': False, 'max_features': 2, 'n_estimators': 3} 54046.26623315312 {'bootstrap': False, 'max_features': 2, 'n_estimators': 10} 60309.371682368066 {'bootstrap': False, 'max_features': 3, 'n_estimators': 3} 52854.394948426 {'bootstrap': False, 'max_features': 3, 'n_estimators': 10} 57989.33069447914 {'bootstrap': False, 'max_features': 4, 'n_estimators': 3} 51271.158658617 {'bootstrap': False, 'max_features': 4, 'n_estimators': 10}
각 특성의 상대적인 중요도(Feature_importances)
정확한 예측을 만들기 위한 각 특성의 상대적인 중요도를 확인
grid_search.best_estimator_.feature_importances_ ##########################[결과]################################### array([7.74707747e-02, 6.74048702e-02, 4.20024792e-02, 1.69208803e-02, 1.64403571e-02, 1.77919106e-02, 1.62757248e-02, 3.08768099e-01, 6.13812438e-02, 1.08024447e-01, 7.93752987e-02, 1.72209413e-02, 1.62673066e-01, 1.11165144e-04, 2.41650504e-03, 5.72223689e-03]) #각 특성 이름을 표시하여 중요도 확인 feature_importances=grid_search.best_estimator_.feature_importances_ extra_attribs = ["rooms_per_hhold", "pop_per_hhold", "bedrooms_per_room"] # cat_encoder = cat_pipeline.named_steps["cat_encoder"] cat_encoder = full_pipeline.named_transformers_["cat_encoder"] cat_one_hot_attribs = list(cat_encoder.categories_[0]) attributes = num_attribs + extra_attribs + cat_one_hot_attribs sorted(zip(feature_importances, attributes), reverse=True) ##########################[결과]################################### [(0.30876809941319167, 'median_income'), (0.1626730656489603, 'INLAND'), (0.10802444705357671, 'pop_per_hhold'), (0.07937529873972449, 'bedrooms_per_room'), (0.07747077469618362, 'longitude'), (0.06740487022298897, 'latitude'), (0.06138124379927702, 'rooms_per_hhold'), (0.04200247922202396, 'housing_median_age'), (0.017791910588744703, 'population'), (0.01722094130649845, '<1H OCEAN'), (0.016920880344629217, 'total_rooms'), (0.016440357094145416, 'total_bedrooms'), (0.016275724801112976, 'households'), (0.005722236886310904, 'NEAR OCEAN'), (0.0024165050381745575, 'NEAR BAY'), (0.00011116514445707611, 'ISLAND')]
랜덤탐색(RandomizedSearchCV)
GridSearchCV는 이전과 같은 비교적 적은 수의 조합을 탐구할때 괜찮습니다. 하지만 하이퍼파라미터 탐색공간이 커지면 RandomizedSearchCV를 사용하는 편이 좋다.
RandomizedSearchCV (#지정하지 않고 하이퍼파라미터 무작위 탐색)
랜덤 탐색을 1,000회 반복하도록 실행하면 하이퍼파라미터마다 각기 다른 1,000개의 값을 탐색한다.(그리드탐색에서는 하이퍼파라미터마다 몇개의 값만 탐색)
단순히 반복 횟수를 조절하는 것만으로 하이퍼파라미터 탐색에 투입할 컴퓨팅 자원을 제어할 수 있다.

데이터분석가를 위한 첫걸음