
명령어 병렬 처리 기법
성능이 좋은 CPU를 만들려면 클럭 속도를 높이거나 CPU가 지원하는 멀티스레드의 수를 높이는 방법이 있었습니다. 하지만 이러한 방법은 물리적인 제약이 존재하므로 CPU의 효율을 높여 성능을 높여 존재하는 자원의 효율성을 높이는 방법으로 CPU의 성능을 높일 수 있습니다. 명령어 병렬 처리 기법은 CPU가 명령어를 처리하는 시간을 극대화하여 CPU의 성능을 높이는 방법입니다. 이러한 방법에는 명령어 파이프, 슈퍼스칼라, 비순차적 명령어 처리가 있습니다.
명령어 파이프
명령어가 처리되는 과정을 클럭 단위로 나뉘어 보면 일반적으로 명령어 인출, 명령어 해석, 명령어 실행, 결과 저장의 단계로 실행됩니다.(절대적인 단계는 아닙니다.) CPU는 이러한 단계가 곂치지 않는다면 서로 다른 스레드를 동시에 실행할 수 있게 됩니다. 예를 들어 명령어1의 명령어 해석 단계를 실행중이라면 동시에 명령어2의 명령어 인출을 실행할 수 있게 되는 것입니다. 이와 같은 방법으로 명령어들을 동시에 넣고 처리하는 기법을 명령어 파이프라이닝이라고 합니다.
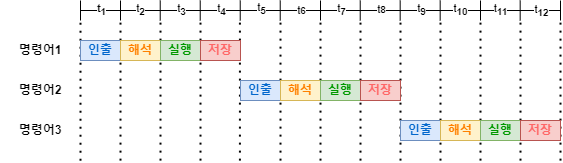
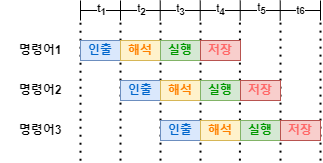
다만 이러한 기법은 CPU의 성능을 높여주지만, 특정 상황에서는 성능 향상에 실패할 수 있습니다. 이러한 상황을 파이프라인 위험이라고 하며, 종류에는 데이터 위험, 제어 위험, 구조적 위험이 있습니다. 자세한 내용은 아래에서 설명드리겠습니다.
슈퍼스칼라
오늘날의 대부분의 CPU에서는 여러개의 파이프라인을 사용하여 파이프라이닝을 구현하고 있습니다. 이처럼 CPU에 여러 파이프라인을 가지는 구조와 기법을 슈퍼스칼라라고 합니다. 이러한 슈퍼스칼라의 경우, 매 클럭마다 동시에 여러 명령어를 인출하거나 실행하는 등, 여러 명령어를 같은 실행 단계로 실행할 수 있어야합니다. 따라서 슈퍼스칼라를 구현하기 위해서는 여러 스레드가 필요하므로 멀티스레드 프로세서에서 슈퍼스칼라 기법을 사용할 수 있습니다.
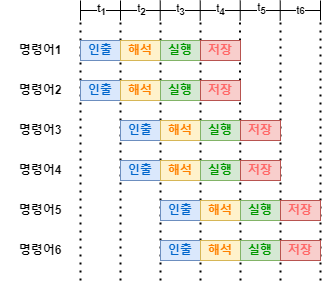
비순차적 명령어 처리
비순차적 명령어는 명령어들을 순차적으로 실행하지 않고, 우선순위에 따라 실행 순서를 효율적인 순서로 변경하여 실행하는 기법을 말합니다. 예를 들어 아래의 코드를 실행 순서를 비교해봅시다.
M(1001) <- 1 #1 메모리의 1001 주소에 1 저장
M(1002) <- 2 #2 메모리의 1002 주소에 2 저장
M(1003) <- M(1001) + M(1002) #3 1001, 1002 메모리에 있는 값을 더하여 1003 메모리에 저장
M(1101) <- 1 #4 메모리의 1101 주소에 1 저장
M(1102) <- 2 #5 메모리의 1102 주소에 2 저장
M(1103) <- 3 #6 메모리의 1103 주소에 3 저장위의 명령어들을 순차적으로 실행하게 되면, 3번 명령어는 1, 2번째 줄의 명령어가 종료되어야 실행할 수 있습니다. 하지만 4, 5, 6번째 명령어는 의존성이 없으므로 1, 2번째 명령어와 동시에 실행되어도 수행 결과에 영향을 미치지 않습니다. 따라서 3번째 명령어를 1, 2번째 명령어가 종료된 후에 실행하고, 그 전까지는 4, 5, 6번 명령어를 먼저 실행하여 효율성을 높일 수 있습니다. 이처럼 명령어의 실행 순서를 바꾸어 파이프라인의 명령어 처리 효율성을 높이는 방법을 비순차적 명령어 처리 기법이라고 합니다. 이처럼 명령어 처리 순서를 바꾸어 처리하기 위해서는 CPU가 명령어간의 의존성이 있는지 파악할 수 있어야하고, 순서를 바꾸어 실행 가능한지 판단할 수 있는 CPU가 이러한 기법을 사용할 수 있습니다.
파이프라인 위험
위에서 파이프라이닝을 통해 CPU의 성능을 높일때 발생할 수 있는 위험에는 3가지가 존재한다고 설명하였습니다. 각 위험은 어떻게 발생하는지 정리해보겠습니다.
데이터 위험(Data Harzard)
데이터 위험은 명령어 사이에 데이터 의존성이 있는 경우 발생할 수 있습니다. 특정 명령어의 결과를 사용하는 명령어의 경우 의존하는 명령어가 완료되고난 후에 실행되어야 합니다. 만약 의존하는 명령어가 종료되지 않은채 의존중인 명령어가 실행되는 경우, 실행 결과가 의도한대로 동작하지 않는 문제가 발생할 수 있습니다. 이러한 문제를 데이터 위험이라고 합니다.
제어 위험(Control Harzard)
제어 위험은 프로그램 카운터에 갑작스러운 변화로 인한 문제입니다. 일반적으로 프로그램 카운터는 현재 실행중인 명령어의 다음 메모리 주소로 갱신됩니다. 하지만 Jump, Call, Interupt와 같은 분기 명령어로 인해 프로그램의 실행 흐름이 바뀌어 프로그램 카운터의 값이 값작스럽게 변경될 수 있습니다. 이러한 경우, 명령어 파이프라인에 대기중인 명령어들은 필요없어질 수 있는데, 이러한 문제를 제어위험이라고 합니다.
구조적 위험(Structural Harzard)
구조적 위험은 서로 다른 명령어들이 동시에 실행되는 과정에서 동시에 ALU, 레지스터 부품을 사용하려고 할 때 발생하는 DeadLock과 비슷한 문제입니다. 이런 상황은 리소스의 공유와 관련이며, 하드웨어 설계에서 적절한 리소스 할당을 통해 최소화할 수 있습니다.
