
회사에서 대용량 데이터를 가진 테이블들을 다루면서 Index를 사용하는 일이 많아졌습니다. 지금까지 테이블의 동작 성능이 높은 자료구조 정도로 이해하고 사용했지만, 어떤 기능을 지원하며 어떻게 동작하는지에 대한 이해가 부족하다는 것을 느꼈습니다. 인덱스를 사용하며 궁금했던 부분들을 정리하며 인덱스의 장점과 단점들을 정리해보고자 합니다.
인덱스
인덱스를 설명하는 예시로 제일 많이 비유되는 것이 책의 목차/찾아보기 혹은 사전입니다. 수많은 데이터가 저장되어 있는 데이터베이스의 테이블에서 원하는 데이터를 찾는 것은 테이블에 저장된 레코드의 수가 많을 수록 부하가 크고, 응답이 늦어질수밖에 없습니다. 이러한 문제는 사전처럼 원하는 정렬 기준으로 테이블의 레코드를 정렬하거나, 원하는 데이터의 위치를 모아 저장해두어 사용하면 위와 같은 문제를 해결할 수 있습니다. 이처럼 원하는 기준으로 정렬된 데이터를 사용하거나 데이터의 위치를 정리하여 데이터베이스의 동작 성능을 향상시키는 것을 인덱스라고 합니다.
인덱스 종류
클러스터 인덱스
클러스터 인덱스는 앞에서 예시로 들었던 사전과 유사하게 동작하는 인덱스입니다. 데이터 자체가 정해진 기준으로 정렬되어 동작하며, 정렬의 기준이 되는 어트리뷰트를 지정하여 인덱스를 생성하게 됩니다. 이러한 클러스터 인덱스는 테이블당 한 개만 생성할 수 있으며, 별도의 인덱스를 지정하지 않는다면 Primary Key를 사용하여 인덱스를 생성하게 됩니다.
보조 인덱스
보조 인덱스는 책의 찾아보기처럼 각각의 아이템이 어디에 저장되어있는지 한 곳에 정리되어 있는 것을 말합니다. 데이터 자체가 정해진 기준으로 정렬되어 동작하는 클러스터 인덱스와는 달리 본래의 데이터 구조에 영향을 미치지 않고 아이템이 저장되어 있는 위치를 별도로 저장하여 사용합니다. 보조 인덱스는 테이블당 여러개의 인덱스를 생성하여 사용할 수 있고, 일반적으로 테이블의 Unique 제약조건에 의해 생성됩니다.
자동 생성 인덱스
앞서 Primary Key로 지정된 어트리뷰트를 기반으로 클러스터 인덱스가 기본으로 생성된다고 설명하였습니다. 클러스터 인덱스가 테이블 당 1개만 생성할 수 있으며, Primary Key는 테이블 레코드의 유일성을 보장하면서 각 테이블 당 1개만 설정할 수 있으므로 Primary Key를 기반으로 클러스터 인덱스가 자동으로 생성되는 것은 당연하고 자연스러운 것이라고 생각할 수 있습니다.
보조 인덱스는 테이블의 Unique로 설정된 어트리뷰트를 기반으로 생성됩니다. Unique 제약조건은 한 테이블에 여러개를 생성할 수 있습니다. 이에 따라 여러개의 Unique 제약조건이 설정된 경우, 각 제약조건에 따라 여러개의 보조 인덱스가 생성됩니다. Unique NOT NULL 제약조건의 경우 Primary Key가 지정된 경우에는 보조 인덱스를 생성하지만, 동시에 Primary Key와 같은 동작을 할 수 있으므로, Primary Key가 지정되지 않은 경우에는 해당 제약조건을 기반으로 클러스터 인덱스를 자동으로 생성하게 됩니다.
인덱스의 동작
B-Tree(Balanced Tree)
인덱스의 동작을 이해하기 위해서는 데이터베이스에서 데이터가 저장되는 자료구조인 B-Tree 구조에 대해 이해할 필요가 있습니다.
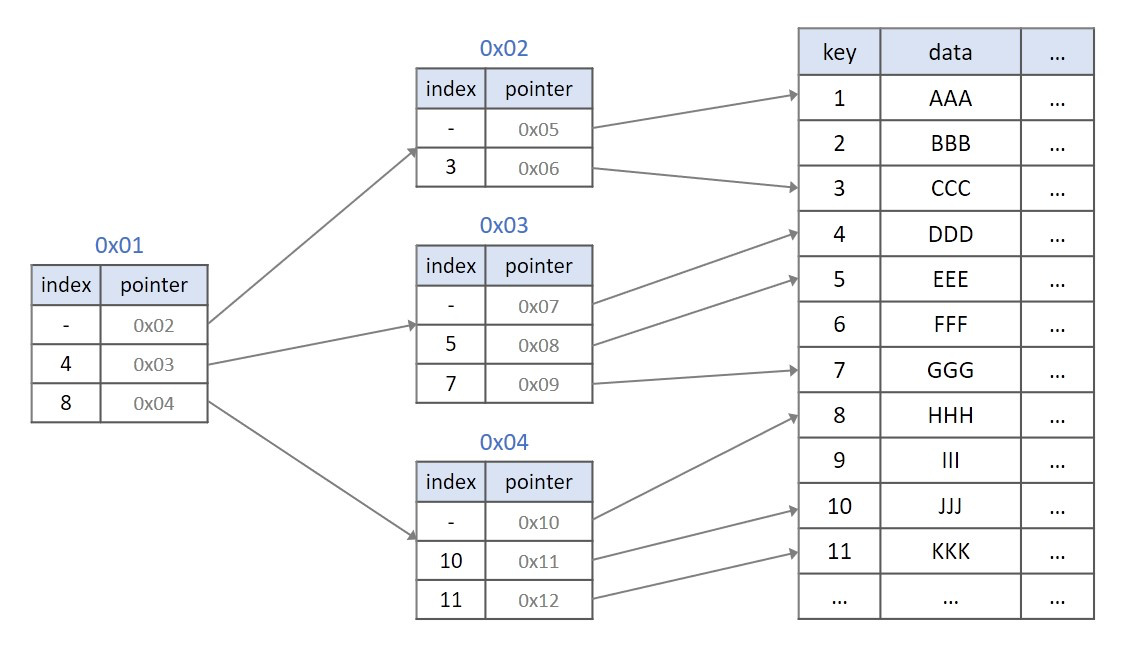
탐색
B-Tree는 기본적으로 트리 구조의 자료구조입니다. 트리의 각 계층에는 여러개의 페이지로 구성되어 있으며, 각각의 페이지는 페이지 크기에 따른 데이터들을 저장하고 있습니다. 위의 인덱스의 경우, key의 오름차순으로 인덱스가 생성되어있습니다. 만약 8번째 데이터에 해당하는 "HHH" 레코드를 Full-Scan 방식으로 찾기 위해서는 첫번째인 "AAA"부터 "HHH"가 저장되어있는 레코드까지 순차적으로 탐색해야합니다. 하지만 인덱스를 사용하게 된다면, 첫번째 페이지인 0x01에서 key가 인 레코드의 위치를 가진 페이지를 참조하고, 다시 key가 8인 레코드의 위치를 참조하고 있는 0x04 페이지의 데이터를 참조해서 key가 8인 레코드의 데이터를 탐색할 수 있습니다. 이와 같은 탐색 방법은 대용량 데이터를 지닌 테이블에서 좋은 성능을 발휘할 수 있습니다.
삽입
반대로 삽입 동작에서는 B-Tree는 오히려 좋지 않은 성능을 발휘할 수 있습니다. 그 이유는 제한적인 페이지의 크기로 인하여 데이터가 삽입될 때 크기가 부족하게 된다면 페이지 분할이라는 동작을 통해 새로운 페이지를 생성하여 데이터를 삽입하기 때문입니다. 데이터가 삽입될시, 페이지의 크기가 충분할 경우 해당 데이터는 페이지의 비어있는 공간에 삽입됩니다. 하지만 페이지의 용량이 부족한 경우에는 비어있는 페이지를 생성한 후, 공간이 부족한 페이지에 저장된 아이템들을 공평하게 반으로 나누어 저장하게 됩니다. 데이터를 삽입하는 것은 1개로 동일하지만, B-Tree 자료구조를 유지하기 위해 비어있는 페이지를 생성하고, 페이지에 저장된 데이터들을 복사/삭제한 후 삽입하는 복잡한 과정을 거치게 됩니다. 이러한 동작 방식으로 인해 B-Tree 구조로 저장된 데이터들이 왜 데이터 변경(UPDATE, DELETE, 특히 INSERT)에서 느리게 동작하는지 이해할 수 있습니다.
클러스터 인덱스와 보조 인덱스
클터스터 인덱스, 보조인덱스 모두 B-Tree 기반 자료구조이므로 탐색, 삽입, 수정과 같은 동작에서 비슷한 과정을 통해 동작하게 됩니다. 하지만 두 인덱스는 데이터를 실제 데이터를 정렬된 상태로 지니는가 아니면 실제 데이터의 위치를 참조하고 있느냐에 차이로 인해 명령에 따른 동작 성능의 차이를 가지게 됩니다.
클러스터 인덱스의 경우, 리프 페이지에 실제 데이터를 지니므로 인덱스 자체에 데이터를 포함하고 있다고 볼 수 있습니다. 하지만 보조 인덱스의 경우 리프 페이지에 해당 데이터가 저장된 고유 위치값을 포인터로 저장하고 있기 때문에, 이로 인한 탐색 과정에서 추가적인 탐색이 필요하게 됩니다. 따라서 보조 인덱스의 경우 일반적으로 클러스터 인덱스보다 탐색 동작에서는 성능이 떨어지게 됩니다. 하지만 오히려 데이터의 수정 동작의 경우, 실제 데이터를 가지고 있지 않다는 점으로 인해 클러스터형 인덱스보다 일반적으로 좋은 성능을 보이게 됩니다.
정리
인덱스의 자료구조를 기반으로 클러스터/보조 인덱스의 동작을 살펴보고 SELECT, INSERT, UPDATE, DELETE의 동작 성능을 살펴보았습니다. 위의 내용을 바탕으로 인덱스의 장점과 단점들을 정리하면 아래와 같이 정리할 수 있습니다.
장점
- 테이블 탐색 성능의 경우 월등히 뛰어난 성능을 보여줍니다. 이로 인해서 데이터베이스 자체의 부하가 줄어들어 전체적인 성능이 개선될 수 있습니다.
단점
- 데이터가 삽입되어있는 테이블에 인덱스를 생성하는 경우, 인덱스를 생성하는데 많은 시간이 소요될 수 있습니다.
- 데이터의 변경 작업의 경우 오히려 좋지 않은 성능을 보일 수 있습니다.
- 인덱스를 사용하기 위한 별도의 디스크 공간이 필요합니다. 일반적으로 인덱스를 사용하게 되는 경우 10%의 추가적인 하드웨어 장치의 공간이 필요하다고 합니다.
인덱스는 장점이 뚜렷한만큼 그에 따른 단점도 분명히 존재합니다. 따라서 단점을 최소화하고 장점을 극대화하기 위해서는 인덱스를 사용할 데이터베이스 테이블의 특징을 잘 파악하고, 인덱스로 사용할 어트리뷰트를 잘 선택하여 사용할 필요가 있어보입니다.
reference
- 이것이 MySQL이다(우재남/한빛출판사/2020.05)
