✏️ File System
File System
: OS 내부에 존재하는 기능으로서, Long Term Storage에 존재하는 파일을 read/write 한다.
Long Term Storage Device의 특징은 다음과 같다.
- 용량이 크다.
- 비휘발성이다.
- 동시에 액세스가 가능해야 한다.
■ File
File은 Storage에 데이터를 저장하는 기본 단위이다.
File은 이름, 데이터, Attribute로 구성되어 있다.
- 파일은 Byte의 연속이다. (IBM은 record의 연속으로 판단하기도 했다)
- 운영체제가 관심있는 파일은 실행파일 밖에 없다.
- 각 파일은 유일한 Path 이름을 가진다.
(파일 이름이 유일한 것은 아니다. 디렉토리가 다르면 이름이 같을 수 있다) - 접근 제어가 가능하다
⚠️ 실행파일에 존재하는 header에는 Magic number, text size, data size, bss size, symbol table size, flags 등이 포함되어 있다.
파일의 데이터를 읽으려면, 이름을 File System에 전달해야 한다.
■ File System
File과 관련된 서비스를 제공하는 System software
- 【 파일 이름.확장자 】 로 파일에 이름을 부여한다.
MS dos 시절에는, 【 이름: 8글자. 확장자: 3글자 】 만 가능했다.
✏️ Semantics
■ File Access Semantics
File을 어떻게 읽어야 할까?
파일을 읽는 방식은 2가지가 존재한다.
-
Sequential Access
: 파일의 처음부터 Read/Write한다. -
Random Access
- 방법1: File open할 때 시작 위치(from)와 바이트 수를 제공한다.
- 방법2: offset을 사용하여 파일을 Read/Write 한다.
■ File sharing Semantics
여러 프로세스가 파일을 동시에 open해서 write 할 수 있다.
파일에 Write힌 내용이 언제 다른 프로세스에게도 적용될 것인가?
- UNIX: 즉시
- Andrew File System(분산 파일 시스템): file close 이후
✏️ Directory
Unix에서는 Directory라고 부르고, Windows에서는 Folder라고 부른다.
Directory도 파일이다!
Directory에는 테이블 형태로 subDirectory나 파일들이 들어있을 뿐이다.
- Directory의 존재 이유:
Directory에서 이름으로 Attribute(Inode 번호)를 찾는 것
■ File Name & Path Name
하나의 파일시스템에서 파일의 Path는 유일해야 한다.
- 절대 경로
: Root Directory에서 시작하는 경로- Unix는 슬래시
/를 루트로 사용한다. - 윈도우는 백슬래시
\를 루트로 사용한다.
- Unix는 슬래시
- 상대 경로
: 각 프로세스마다 Current Working Directory에서 시작하는 경로
하나의 파일시스템에서 파일의 Path는 유일해야 한다.
⚠️ Unix는 파일 시스템 트리는 단 한개이지만, windows에는 파일 시스템이 여러개 존재할 수 있다.
➜ 동일한 Path를 가진 파일이 존재할 수도 있다. (물론 파일 시스템 자체는 다르다.)
■ Directory 와 File의 연산
| Directory 연산 | File 연산 |
|---|---|
| Create | Create |
| Delete | Delete |
| Opendir | Open |
| Closedir | Close |
| Readdir | Read |
| Rename | Write |
| Link | Append |
| Unlink | Seek |
| Get Attributes | |
| Set Attributes | |
| Rename |
- Directory에는 write 연산이 존재하지 않는다.
Directory의 변경은 Kernel만 가능하다.
파일을 삭제하거나 생성하면 디렉토리 내용을 Kernel이 변경해준다.
✏️ File System Formatting
섹터: HDD의 최소 기억 단위
블록: 파일 시스템이 데이터를 저장하거나 관리하는 논리적 단위
- 섹터를 여러개 모아서 블록으로 만든다.
- 블록의 크기는 Formatting할 때 정해진다.
■ File System Layout
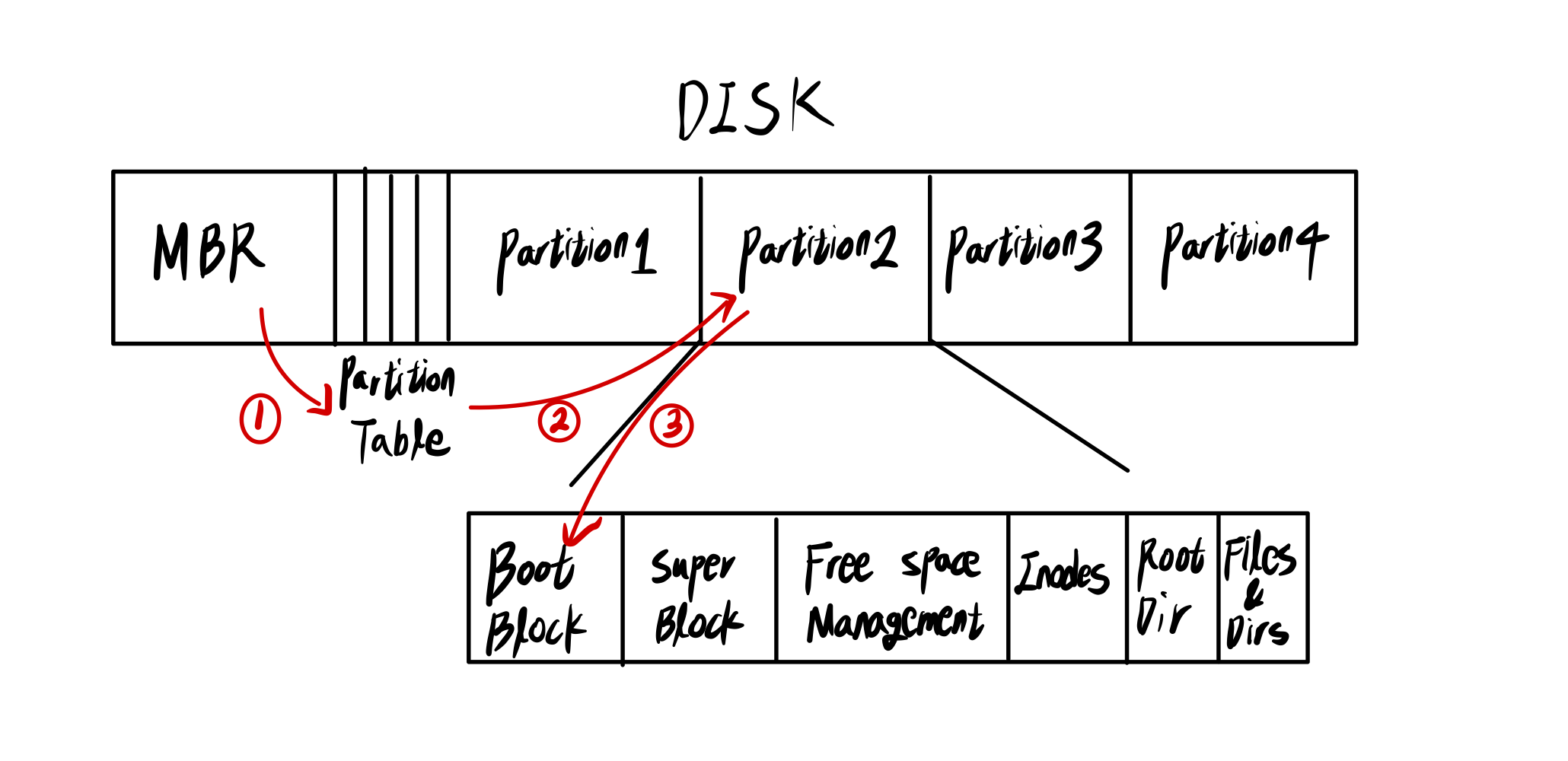
- HDD의 0번 트랙 0번 섹터에는 MBR(Master Boot Record)이 코드로 적혀있다.
- HDD 내부에 Partition은 4개까지 존재할 수 있다.
➜ 파일 시스템을 4개까지 설치 가능하다. - Boot Block에는 특정 운영체제의 부팅 Code가 적혀있다.
부팅 과정
1. Master Boot Record은 Partition table을 읽는다.
2. Boot Partition을 찾는다.
3. Boot Partition의 첫 블록을 읽음
- super block은 파일 시스템의 전체 형상정보이다.
- Free space management는 bit map을 사용한다.
■ Free Space Management
빈 공간 관리를 어떻게 할 것인가?
1. Bit Map
- 가장 많이 사용하는 방식이다.
- 하드 디스크에 존재하는 블록을 bit Map으로 관리한다.
사용중이면 1, Free이면 0으로 표시한다.bit map size = Disk Size / One Block Size
2. Linked List
- 빈 공간을 Linked List로 연결한다.
- 어차피 Free Space이기 때문에 어떤 내용(next 포인터)을 넣어도 상관없다.
- ex - Free Space 2번 할당:
2번 블록을 할당하고 3번을 Linked List의 head로 바꾼다.
<단점>- Free Space를 할당하려면 Linked List를 read/write 해야한다.
➜ 너무 비효율적이다!
3. Grouping
- Linked List의 개선 버전
- Index block으로 Free Space를 가리킨다.
- 해당 Index block의 Free Space를 모두 할당하면 마지막에는 Index Block 자체를 할당한다.
<단점>- 빈공간이 생기면 이러한 구조(Index block)를 다시 구현해야 함.
- Aging이 존재한다.
: 특정 그룹만 자주 사용되어 파일 시스템의 성능이 떨어지는 문제
- Disk Quotas를 사용해서 파일 시스템에서 사용할 수 있는 디스크 공간의 양을 제한할 수 있다.
- soft block limit: 초과할 수 있으나 경고 메시지 발송
- hard block limit: 사용자가 절대 초과할 수 없음
■ File allocation
파일을 생성하기 위해서는 디스크에 블록을 할당해야 한다.
블록 할당 방식은 3가지가 있다.
1. Contiguous Allocation: 연속적으로 할당
- 파일을 연속적으로만 할당한다.
- start Block과 size만 제공하면 블록을 할당 받을 수 있다.
ex) 0번 블록부터 3개- CD ROM에서 사용한다.
Contiguous Allocation은 다음과 같은 문제를 가지고 있다.
- 파일 크기를 키울 수 없다.
- Free Space가 존재해도, 크기가 크면 할당할 수 없다.
: Fragmentation 문제, 따라서 HDD에서는 사용하지 않는다.
2. Chained Allocation: 불연속적 할당
- Linked List 방식으로 블록을 할당한다.
- Contiguous와 마찬가지로, start Block과 size만 제공하면 블록을 할당 받을 수 있다.
- 블록에는 Data와 다음 블록의 인덱스가 존재한다.
Chained Allocation은 다음과 같은 문제를 가지고 있다.
- Linked List 구조이기 때문에 파일을 무조건 처음부터 읽어야 한다.
- Data와 MetaData를 한곳에 모았다는 단점이 존재한다.
위의 문제를 해결하기 위해 MetaData(다음 블록의 인덱스)만 모으는 방식을 고안했다.
이것이 FAT(File Allocation Table) 파일 시스템 구조이다.
3. Indexed Allocation: 불연속적 할당
- index block을 사용해서 블록을 할당한다.
- index block에는 Data block Table이 존재한다.
- ex) File A를 위한 블록을 할당하는 경우
- Index block 24 할당한다.
- Index block 24에는 block 【 1,8,3,14,28 】 의 포인터가 존재한다.
- 【 1,8,3,14,28 】 에 파일의 데이터를 적는다.
Indexed Allocation을 사용할 때, 파일의 크기가 너무 큰 경우
➜ index block을 Linked List로 구현한다.
✏️ 다양한 File System
■ FAT File System
FAT(File Allocation Table) 파일 시스템을 알아보자.
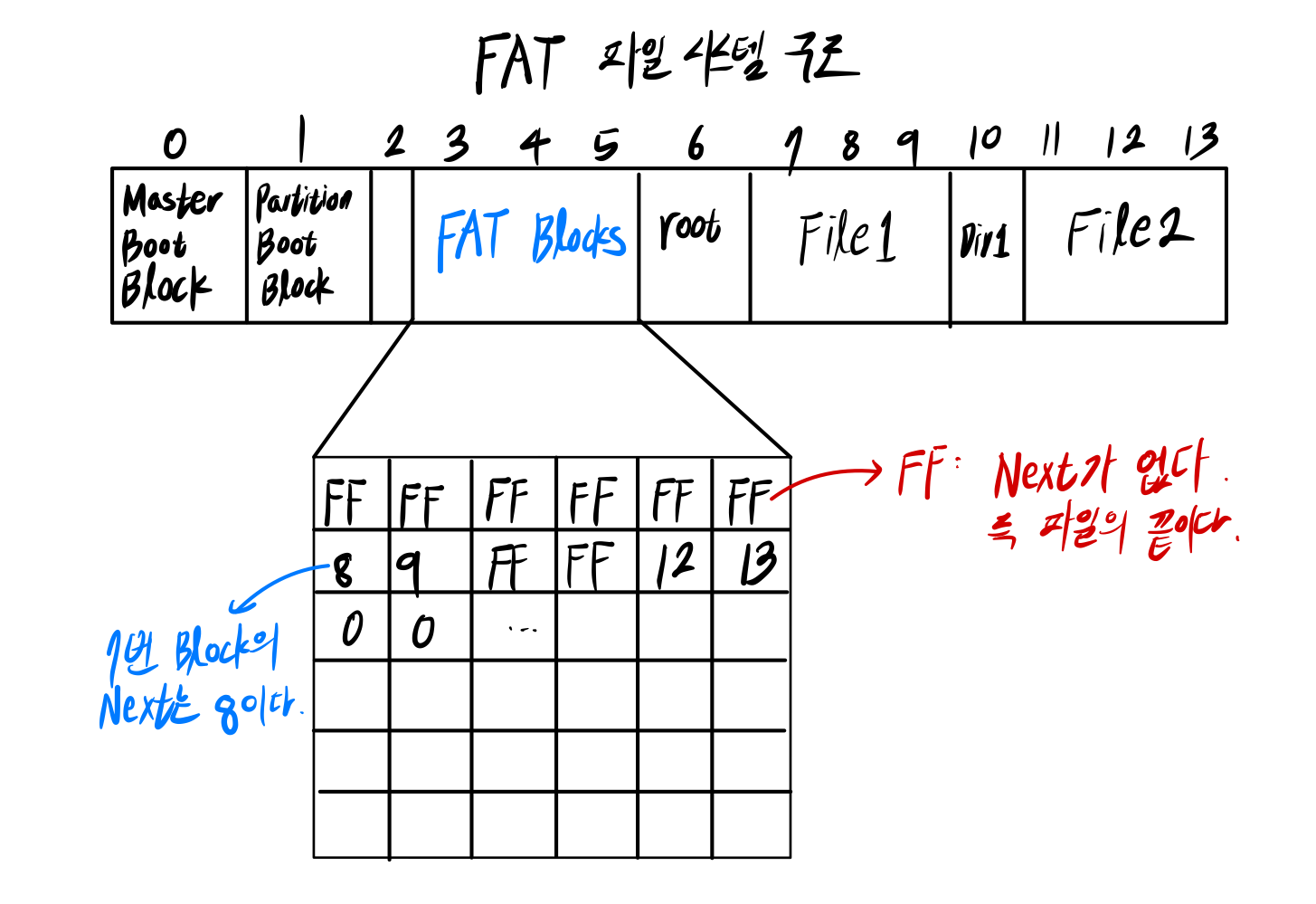
- FAT을 통해서 Free block을 찾을 수 있음
- FAT을 통해서 다음 블록을 찾을 수 있음
Find File1
1. Read Root Directory
2. 이름이 File1인 entry를 찾는다.
3. First address:7번 size: 3
4. 7번을 읽은 뒤에 블록 7에 대응되는 Entry를 FAT에서 찾는다.
5. 두번째 블록은 블록 8에 존재.
...
FAT 시스템의 단점
-
FAT이 메모리가 통째로 올라와 있어야 한다.
➜ 대용량이 되면 Overhead가 크다. -
파일의 뒷부분을 읽으려면 처음부터 계속 읽어야 한다.
■ Unix File System
Fast File System이라 부르기도 함
Unix File System은 Indexed Allocation 방식에서 Index Block 대신 Inode를 사용한다.
Inode = Index Block + File의 Attribute
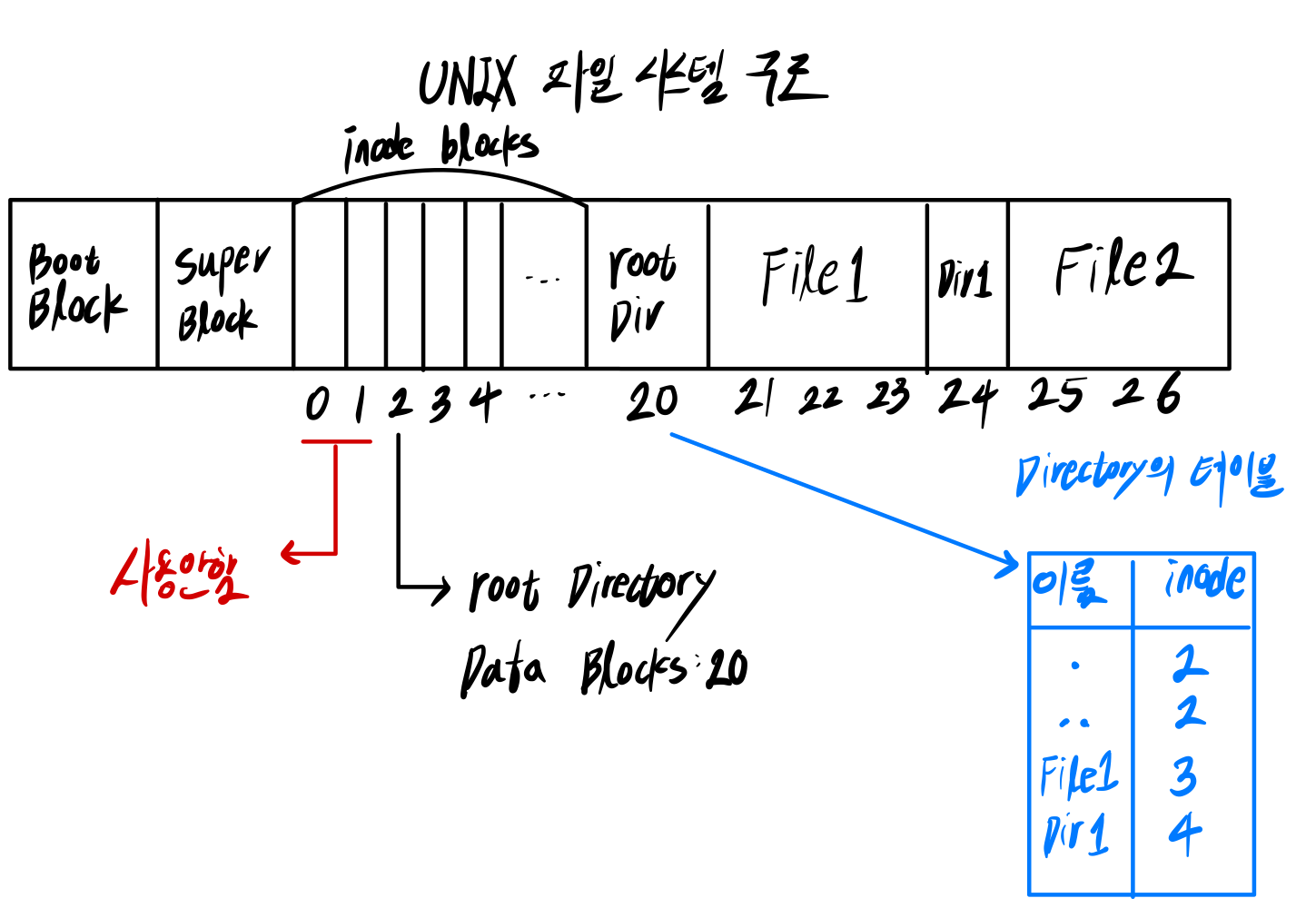
- inode의 크기는 256 Bytes 이다.
- inode list의 위치는 고정되어 있다.
➜ 바로 indexing할 수 있음 - inode 0번, 1번은 사용하지 않는다.
2번은 Root directory의 Inode 번호이다.
Inode에 존재하는 정보
Inode는 파일의 이름을 제외한 모든 정보가 들어있다.
- status(dir/file)
- size
- Creation, Modify, Access Date
- Permission bit
- Data Block
Block Addressing
Inode는 총 256Byte 이다.
➜ 데이터 블록의 주소를 무한정 넣을 수 없다. (최대 제한 13개)
if, 파일이 데이터 블록의 제한보다 크다면?
➜ indirect Indexing을 사용한다.
13개의 데이터 블록 주소 공간을direct indexing 10개 + single indirect 1개 + double indirect 1개 + triple indirect 1개로 분리한다.
FAT 파일 시스템과의 차이점
- Fat는 Root Directory에
.,..이 존재하지 않는다.
■ ISO 9660 File System
CD-ROM에서 사용하는 파일시스템이다.
- 연속할당 기법을 사용한다.
- 연속 할당이므로, 파일에 접근할 때는 시작 주소와 사이즈만 있으면 된다.
- 이름: 8, 확장자: 3을 사용한다.
⚠️ HDD와 달리, CD-ROM은 안쪽부터 사용한다.
■ Ext 2,3,4 File System
Ext 2,3,4 File System은 리눅스 운영체제에서 사용되는 파일시스템이다.
Ext-2 File System:
- 초기 버전
- No journaling
Ext-3 File System:
- fsck로 journaling 도입
Ext-4 File System:
- Extent 개념 도입 (저장 용량의 한계 극복을 위해서)
- 연속된 블록의 그룹을 하나의 단위로 관리하는 방법
- 파일에 공간을 할당할 때, 기본 단위가 Extent이다.
- 연속적으로 할당하려고 노력한다.
✏️ Shared files
Unix File System에서는 inode 번호만 같으면 같은 파일이다.
■ hard link
hard link를 사용하면, inode가 같은 파일을 새로 생성할 수 있다.
➜ 파일에 새로운 이름을 부여한다
- hard link를 사용해서 파일을 공유할 수 있다
- hard link는 부작용이 많다.
- 파일을 삭제해도 다른 link가 남아있을 수 있다.
- 파일들을 백업할 때 하나의 파일이 2번 백업될 수 있다.
- 하위에서 상위 폴더로 link 해서 루프가 발생할 수 있다.
∴ directory에 대한 링크는 Root 사용자만 만들 수 있음
■ symbolic link
위와 같은 문제점들을 해결하기 위해서 symbolic link 파일을 만들었다.
symbolic link 파일에는 자신이 가리키는 파일의 path가 적혀있다.
- 원본 파일과 inode가 다르다.
- 원본 파일 삭제하면 symbolic link도 사용 불가
- 백업할 때 원본 파일과 따로 백업된다.
✏️ Log-Structured File System
지금까지의 File System에서 파일은 위치가 고정되어 있다.
Log-Structured File System은 파일의 위치를 변하게 하여 Disk에 Write 하는 성능을 극대화 시킨다.
파일의 데이터 변경 시
기존 방식: Data를 새로운 block에 적고, inode도 업데이트 해야 한다.
Log-Structured: Writing Point에 순차적으로 기록한다.(log)
Log-Structured의 특징
- Disk에 데이터를 순차적으로 기록한다.
- Disk 헤드의 이동을 최소화 하여 Write 성능을 극대화 한다.
- 변경된 내용을 Write Point에 순차적으로 기록하므로, 별도로 기존 inode를 수정할 필요가 없더,
- inode map을 사용해서 Inode 위치를 추적한다.
- 동작 방식이 Flash Memory와 동일하다.
✏️ File consistency
파일의 데이터를 변경하면 얼마나 많은 블록을 바꿔야 하는가?
1. Free Space Bit Map을 바꿔서 Data Block 할당 받아야 한다.
2. Directory Entry도 바꿔야 한다.
3. Inode도 바꿔야 한다.
...
Disk의 수 많은 블록을 바꿔야 한다.
만약, 데이터 중 일부를 변경하다가 전기가 나간다면 일관성(Consistency)이 떨어지게 된다.
∴ 일관성을 회복한 뒤에 부팅된다.
- 파일 시스템은 일관성이 없으면 동작하지 않는다.
■ 일관성 회복
- Unix - fsck(File System Check) 사용해서 일관성 회복
- Windows: scandisk 사용해서 일관성 회복
현대 컴퓨터는 journaling 방식을 사용해서 일관성을 빠르게 회복한다.
■ journaling
File System을 변경하려면 Log Area에 변경 사항(journal)을 작성한 뒤, 변경. 변경이 끝나면 Log를 지운다.
변경중에 갑자기 전기가 나가면 파일 시스템 전체를 체크할 필요없이 Log만 보면된다.
위의 방식을 journaling이라 한다.
✏️ File System Backup
Backup Type
-
Physical Dump
: 하드디스크의 첫번째 블록부터 적는 방식 -
Logical Dump
: 파일 시스템 트리를 순회하면서 백업하는 방식- complete Dump: root에서부터 전부 백업하는 방식
- incremental Dump: 마지막 변경 이후의 Data만 백업하는 방식
■ Incremental Dump
파일을 Dump 하려면, 상위의 모든 Directory를 Dump해야 한다.
Incremental Dump 백업 과정
- bit map에서 Directory는 전부 1, 변경된 파일도 1로 세팅
- Dump 안해도 될 Directory는 0으로 변경
- Directory Dump(백업)
- File Dump(백업)
■ 복구 과정
- 마지막 complete Dump를 recovery
- 그 후로 실행된 incremental Dump를 recovery
■ 문제점
- file에 hard link가 존재하면 파일이 한개인데 dump가 2번 됨
- Hole(Data block을 가리키고 있지 않은 index 블록들)이 존재하면 Hole도 백업된다.
- 파이프 파일은 어떻게 백업할 지 정해지지 않음
✏️ File System Performance
File System의 성능을 높이는 방법
- Caching
- Read-ahead
- Reducing head Movement
- Disk Fragmentation
1. Caching
Dick Cache(Unix에서는 Buffer cache)를 사용하여 성능을 높이는 방법
- 디스크에서 자주 접근하는 데이터를 DRAM 에 캐싱한다.
- Write-through 방식과 Write-back 방식이 존재한다.
- Write-through: 변경 발생 시 buffer Cache에 적고, 바로 Disk에도 적음
- Write-back: 변경 발생 시 buffer Cache에 적고, maximum caching time 뒤에 Disk에 적음
Unix에서는 sync 시스템 호출을 사용해서 Cache에 있는 값을 디스크로 옮긴다.
2. Read-ahead
사용자가 앞으로 읽을 것으로 예상되는 데이터를 미리 읽는 방법
- 데이터를 읽어가면, 예상 데이터를 미리 읽어온다.
- 또 읽으면 예상 데이터를 이전보다 더 많이 읽어간다.
⚠️ 파일에 순차적으로 접근하지 않는 경우 손해이다.
3. Reducing Head Movement
HDD에서 데이터를 Read/Write 할 때, 헤드의 움직임을 최소화하여 성능을 향상시킬 수 있다.
- head는 실린더 단위로 움직인다.
- 기존의 파일 시스템은 Super Block이 단 하나이고, 첫번째 트랙에 적혀있었다.
- Super Block 오류 발생 시, 전체 파일 시스템이 다운
- 가장 바깥쪽 실린더에 inode list가 존재하기 때문에, 파일을 변경하는 경우 inode(바깥쪽)를 바꾸고 데이터(안쪽)를 바꿔야 하는데 이는 head의 움직임이 크다.
UNIX 파일시스템
위와 같은 단점을 해결하기 위해서 실린더 그룹을 도입했다.
- 실린더 그룹은 인접 실린더 여러개를 하나로 모은 것이다.
- 각 실린더 그룹마다 하나씩 super block, Group Descriptor(그룹의 형상정보)를 가지고 있다.
- 파일을 만들면 부모 디렉토리가 존재하는 실린더 그룹에 파일을 생성한다.
➜ 헤드가 거의 움직이지 않는다. - 파일이 특정 크기 이상 커지면 인접 실린더로 확장한다.
➜ 큰 파일이 실린더를 독점하는 것을 막는다
4. Disk Fragmentation
파일 시스템에서 데이터 조각들이 분산되어 있을 때, 이 데이터 조각들을 연속적으로 재배치하여 성능을 높인다.
✏️ File Access Control
Access Control 기법의 종류는 3가지가 존재한다.
- Access Control Matrix
- Access Control List
- Capability List
Access Control은 file을 Open할 때만 (Read용, Write 용 open) 검사한다.
➜ 그 후에 Read, Write할 때는 권한 검사가 이루어지지 않는다!
1. Access Control Matrix
파일과 유저의 접근 권한을 행렬로 저장
| User1 | User2 | User3 | |
|---|---|---|---|
| File1 | RWED | R-E- | ---- |
| File2 | ---- | RW-- | R--D |
| File3 | RWE- | R-E- | ---- |
- 너무 사이즈가 크다.
2. Access Control List
파일마다 접근 제어 리스트를 가지게 한다.
| File | Access |
|---|---|
| File1 | User1(RWED), User2(R-E-), WORLD(----) |
| File2 | User2(RW--), User3(R--D), WORLD(----) |
| File3 | User1(RWE-), User2(R-E-) |
3. Capability List
유저마다 접근 제어 리스트를 가지게 함
| User | Access |
|---|---|
| User1 | File1(RWED), File3(RWE-) |
| User2 | Fuke1(R-E-), File2(RW--), File3(R-E-) |
| User3 | File2(R--D) |
REFERENCE
📚 Modern Operating Systems, Third Edition - Andrew S. Tanenbaum

퍼가요 ^^