✏️ I/O Device
■ Device의 종류
-
Block Device
: 빠르고 큰 단위로 입출력이 발생하는 Device- HDD
- CD-ROM
- USB
-
Character Device
: 느리고 작은 단위로 입출력이 발생하는 Device- Mouse
- Printer
- Modem
■ Device Controller
Device는 Device 자체(Mechanical Component)와 Controller(Electronic Component)로 구성되어 있다.
Controller의 역할은 다음과 같다.
- Command Register에 적힌 명령을 해석하여 I/O 장치가 이해할 수 있는 형태로 변환
- bit stream을 block of Bytes로 전환
- 입출력이 끝나면 CPU에 interrupt 전송
- Buffer 관리
- error Correction
■ CPU ↔︎ Device 상호작용
CPU는 I/O Device와 어떻게 상호작용 하는가?
2가지 방식이 존재한다.
Memory Mapped I/O:
메모리와 입출력 장치의 주소를 구분하지 않음
메모리 주소의 일부분을 I/O Register에 부여한다.
CPU는 마치 메모리에 접근하는 것과 똑같이 입출력 장치에 접근한다.
I/O Mapped I/O (Seperate I/O):
메모리와 입출력 장치의 주소를 구분함
I/O Register에 접근하는 명령어가 별도로 존재한다.
입출력을 하기 위해서는 별도의 주소 입력 버스를 사용해야 한다.
⚠️ 두 방식을 혼합한 Hybrid도 존재한다. - Pentium에서 사용
✏️ DMA
DMA (Direct Memory Access)
: CPU의 직접적인 개입 없이 I/O 장치와 메모리 간에 데이터를 전송하는 방법
Buffer에 존재하는 데이터를 DRAM을 COPY 할 때, CPU라는 비싼 자원을 사용하는게 아깝다.
➜ Copy 기능만 해주는 DMA 회로를 사용하자.
■ DMA의 작동 과정
-
프로그램에서 Read 시스템 호출
-
CPU가 DMA Controller에 세팅을 한다.
- address: 어디서부터 어디로 (ex. buffer->main memory)
- Count: 전송할 데이터의 크기
- Control: 제어 정보
-
데이터 전송
-
Cycle Stealing
-
데이터 전송이 끝나면 DMA가 CPU에 interrupt 전송
■ 데이터 전송의 방식
-
Fly-by-mode
: Buffer ➜ 메모리로 데이터 전송, 중간 단계 없이 바로 데이터를 옮긴다. -
대체 모드
: Device Controller ➜ DMA Controller로 데이터 전송
■ Cycle Stealing
DRAM에 CPU와 DMA가 동시에 Access 요청을 하면, DMA의 요청을 먼저 처리한다.
✏️ Interrupt
I/O Device 들은 Interrupt Controller에 연결되어 입출력을 한다.
- CPU에 Interrupt 칩은 딱 하나 존재한다.
- 모든 Interrupt(I/O 포함)는 Interrupt Controller에서 받는다.
- Interrupt Controller는 Interrupt 우선순위를 중개해주는 역할을 한다.
- Clock Interrupt이 가장 우선순위가 높다.
■ Interrupt Handling
인터럽트가 발생하면, CPU는 현재 실행중인 작업을 마친 후 인터럽트 서비스 루틴(ISR)로 점프한다.
ISR이 끝나면 CPU는 Interrupt Controller에 ACK를 보낸다.
■ Precise Interrupt
CPU는 PipeLineing과 SuperScalar로 여러 명령어를 한꺼번에 실행중이다.
이 경우에 Interrupt가 발생하면, 각 명령어의 완료 수준을 그대로 Save해야 된다.(imprecise interrupt)
➜ 너무 어려워
따라서, 일부 명령어까지만 다 실행한 다음에 ISR로 점프하는 precise interrupt를 사용한다.
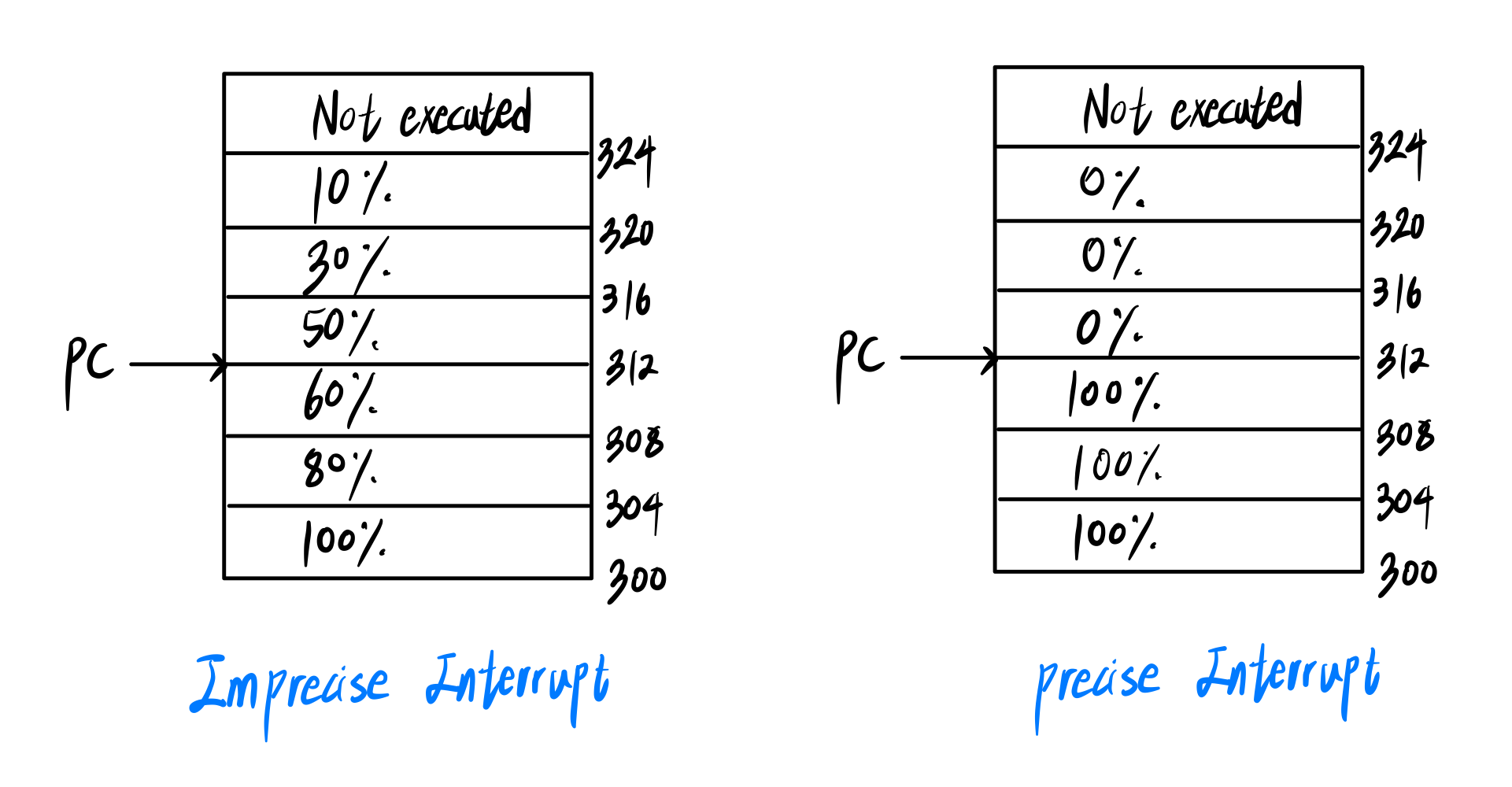
Precise interrupt의 조건
-
PC의 정확한 위치
: 인터럽트가 발생할 때, PC의 위치가 정확히 알려져 있어야 한다. -
PC 이전의 모든 명령 실행 완료
: PC가 가리키는 주소보다 낮은 주소에 있는 모든 명령은 인터럽트 시점에서 완전히 실행되어야 한다. -
PC 이후의 명령 미실행
: PC가 가리키는 주소보다 높은 주소의 명령은 하나도 실행되지 않아야 한다. -
PC가 가리키는 명령의 상태
: 인터럽트 발생 시 PC가 가리키는 명령의 상태는 명확히 알려져 있어야 한다.
✏️ I/O software의 Issue
-
Device Independency
Device에 관계없이 똑같은 방식으로 입출력할 수 있어야 한다. -
Uniform Naming
: Device에 일관성 있는 이름 부여 -
Error Handling
-
Synchronous vs Asynchronous
- 입출력을 하는 동안 대기한다 - Synchronous (Blocked)
- 입출력을 하는 동안 다른 작업을 한다. - Asynchronous (interrupt-driven)
-
Buffering
- No Buffering: 운영체제를 패스하고 I/O 장치로부터 사용자 프로세스가 지정한 메모리로 바로 전달된다. (네트워크 Device 이외에는 거의 사용되지 않는다)
- Single Buffering/Double Buffering: 입출력 내용을 OS의 버퍼에 저장한 뒤에 프로세스가 지정한 메모리로 전달된다.
사용자 프로그램은 입출력을 요구하면 멈춘다.
운영체제는 사용자 프로그램을 언제든지 Swap Out할 수 있다.
➜ 데이터를 전달할 메모리 공간이 없어지는 문제가 발생할 수 있다.
- Sharable vs Dedicated
- Disk는 공유
- Tape는 공유 안한다.
✏️ I/O의 종류
입출력 작업을 처리하는 방식은 세 가지가 존재한다.
1. Programmed I/O
CPU가 모든 I/O 작업을 제어하고 status를 반복 검사한다.
CPU는 Status Register를 보면서 루프를 돈다.
ex) User Process A에서 "ABCD"를 USB에 Write 하는 경우
1. 사용자 버퍼에서 Kernel Buffer로 내용 복사
2. 장치 상태 폴링
: status가 busy면 대기, status가 ready면 Write
Programmed I/O는 CPU의 낭비가 심하다는 단점이 있다.
2. Interrupt-Drivent I/O
입출력 장치에서 작업이 완료되면 CPU에 인터럽트 신호를 보낸다.
그 시간동안 CPU는 자신이 해야 할 작업을 한다.
3. I/O Using DMA
DMA 컨트롤러가 메모리와 장치 간의 데이터 전송을 관리
✏️ I/O software Layers
| Layer | 기능 |
|---|---|
| User-level I/O software | 스캐너나 프린터 같은 외부 장치들과 직접 상호작용 I/O call |
| Device independent software | Naming, Buffering, Blocking, Allocation |
| Device drivers | 특정 하드웨어 장치를 관리(register 세팅) |
| Interrupt Handler | 하드웨어로부터의 인터럽트 신호를 처리 |
| HardWare | 데이터 처리, 입출력 수행 |
Interrupt Handler
Interrupt Handler는 데이터가 오면 버퍼에 넣고, 사용자 프로세스를 깨워주는 역할을 한다.
동작 방식은 다음과 같다.
- CPU 내부의 다른 레지스터를 스택에 저장한다. (PC 뿐만 아니라 다른 레지스터들도)
- ISR로 점프한다. (커널 모드로 바뀐다는 뜻)
- User Stack ➜ Kernel Stack
- interrupt controller에 ACK 전송
- Copy Registers
- ISR 실행
I/O 작업을 마친 뒤에는 Scheduling을 통해 어떤 프로세스로 돌아갈 지 결정한다.
⚠️ 원래 실행하던 프로세스에서 다른 프로세스로 가려면 MMU를 세팅해야 한다.
✏️ Magnetic Disk
■ Delay
Magnetic Disk에서 Delay는 3가지 이유로 인해서 발생한다.
- 헤드가 원하는 Track으로 움직이는 시간
: seek Time - 디스크가 회전하는 시간
: Rotational delay - 디스크에서 데이터 전송 시간
: Transfer Time
■ RAID
Disk는 신뢰성이 낮은 장치이다. (고장 확률이 높다)
➜ RAID를 사용해서 해결한다.
RAID(Redundant Array of Independent Disks)
디스크의 성능과 신뢰성을 증진시키는 디스크 조직 기법
- 다수의 저가 소형 디스크를 이용한다.
- Data Striping을 통해서 성능을 높인다.
: 데이터를 똑같은 크기로 분할하여 여러 디스크에 분산 저장한다.- Bit Level Striping - 각 비트를 여러 디스크에 분할 저장
- Block Level Striping - 각 블록을 여러 디스크에 분할 저장
| level | Striping | Detail |
|---|---|---|
| Raid 0 | Block Level Striping | 데이터를 여러 디스크에 분산 저장 추가 정보가 없기 때문에 성능 👍 디스크 하나만 고장나도 데이터 손실 ➜ 신뢰성 낮음 |
| Raid 1 | Block Level Striping | 똑같은 데이터를 두 군데에 저장(Mirroring) 성능 👍, 신뢰성 👍 |
| Raid 2 | Bit Level Striping | Bit 단위로 데이터를 쪼개서 분할 저장 4 bit는 데이터, 3 bit는 error correction bit |
| Raid 3 | Bit Level Striping | Level 2에서 3 bit의 Error Correction을 했던 것과 달리, Level 3에서는 Parity Bit만 사용한다. |
| Raid 4 | Block Level Striping | Parity Disk 사용 데이터 하나 바꾸면 Parity Disk도 바꿔야 한다. ➜ Parity Disk가 너무 바쁘다는 단점이 존재한다. (고장 잘남) |
| Raid 5 | Block Level Striping | 각 Disk마다 Parity 블록을 하나씩 저장한다. |
실제로 Raid Level 5를 많이 사용하지만, 속도는 높지 않다.
Raid Level 5에는 Small Write Problem이 존재한다.
: 데이터의 어느 한 블록만 변경하는 Small Write의 경우, 해당 블록이 존재하는 디스크 뿐만 아니라 데이터가 분산되어 있는 모든 디스크에 액세스하여 Parity를 계산해야 한다.
-
레이드 레벨 5에서는 단일 디스크가 고장나도 나머지 디스크의 데이터와 패리티 정보를 사용해 데이터를 복원할 수 있다.
-
레이드 레벨 6,7은 2개의 디스크가 고장나도 복구가 가능함.
-
성능면에서는 Raid Level 1이 가장 좋다.
근데 가격이 비싸다.
✏️ HDD
Magnetic Disk에는 CD-ROM, DVD, HDD 등이 존재한다.
그 중에서 HDD에 대해서 알아보자.
■ 트랙과 섹터
실제 디스크에 존재하는 트랙의 개수는 알 수 없다. (디스크 제조 회사에서 비밀로 한다)
∴ virtual geometry를 사용한다.
- 디스크의 안쪽으로 갈 수록 트랙 당 섹터의 개수가 줄어든다.
- 각 트랙마다 섹터의 시작 위치가 다르다!
➜ cylinder skew: 헤드가 다음 트랙에 도달했을 때 바로 다음 섹터의 데이터를 읽거나 쓸 수 있도록 섹터들을 조정
■ interleaving
- No interleaving: 데이터를 연속된 섹터에 저장하는 방식
- Single interleaving: 데이터를 한 칸씩 뛰어서 저장하는 방식
- Double interleaving: 데이터를 두 칸씩 뛰어서 적장하는 방식
왜 이렇게 사용할까?
n번 섹터 읽고 전송하는 사이(Transfer Time)에 n+1번 섹터를 지나가버리는 상황을 방지하기 위해서.
⚠️ 현재는 interleaving 대신에 트랙 버퍼를 사용한다.
- 헤드가 특정 트랙에 도착하면, 무조건 트랙 버퍼에 저장한다.
- 해당 데이터를 요구하면 트랙 버퍼에서 전송한다.
■ Disk Arm Scheduling
- 헤드가 원하는 Track으로 움직이는 시간
: Seek Time - 디스크가 회전하는 시간
: Rotational Delay - 디스크에서 데이터 전송 시간
: Transfer Time
Seek time > Rotational Delay > Transfer Time
Seek Time을 최소화 해보자!
➜ 디스크 헤드의 움직임을 최소화 하는 알고리즘을 찾자
| 알고리즘 | 설명 |
|---|---|
| FIFO | 요청이 도착한 순서대로 처리 요청이 들어온 순서대로 트랙 번호만 적어놓는다.(섹터에는 관심이 없다) |
| SSTF(Shortest Service Time First) | 현재 헤드 위치에서 가장 가까운 요청부터 처리한다. 특정 트랙 집합의 요청만 계속 처리하는 기아 문제가 발생할 수 있다. |
| SCAN(elevator algorithm) | 현재 트랙에서 헤드 번호가 커지는 방향으로 요청을 처리 한뒤에, 번호가 작아지는 방향으로 쭉 내려가며 서비스한다. - 서비스 타임의 편차가 발생한다. - 사이드 트랙은 오래 기다리고, 가운데 트랙은 조금만 기다리면 된다. |
| C-SCAN(Circular SCAN) | 한 방향으로만 헤드를 움직이며 요청을 처리한다. - 서비스 타임의 편차를 줄일 수 있다. |
| N-Step-SCAN | 큐를 여러 개 사용하며(가변), 각 큐는 최대 N개의 요청을 담을 수 있다. 한 번에 하나의 큐에 존재하는 요청들만 SCAN으로 서비스한다. |
| FSCAN | 큐의 개수는 2개로 고정하고, 각 큐는 가변적으로 요청을 받는다. 하나의 큐가 완전히 처리될 동안 다른 큐가 요청을 수집한다. |
헤드의 움직인 거리가 가장 작은건
SSTF
SCAN
C-SCAN
FIFO 순
■ Error Handling
-
Spare Sector 사용
➜ bad sector가 발생하면, spare sector로 데이터를 옮긴다. -
데이터를 한 칸씩 뒤로 옮기기
➜ bad sector가 발생하면, 데이터를 한 칸 씩 뒤로 민다.
데이터는 순차적으로 저장하는 것이 좋으므로, 2번의 handling 방식이 더 성능이 높다.
하지만, 현재는 트랙 버퍼를 사용하기 때문에 순차적으로 저장할 필요는 없다.
■ Stable Storage
HDD는 Transaction을 지원하지 않는다. 즉, roll back & roll forward를 지원하지 않는다.
➜ HDD는 Stable하지 않다.
ex) HDD에 데이터를 적다가 전기가 나가면?
충돌이 발생한 데이터를 처리해줘야 한다.
즉, old data(바꾸기 전 데이터) 또는 new data(비꾼 후의 데이터)로 roll back 또는 roll forward 처리를 해야한다.
기존의 HDD는 이런게 불가능 함.
But! HDD를 두개 사용하면 가능하다.
HDD 1번에 New Data를 적는다.
HDD 2번에 New Data를 적는다.
이 때, 발생할 수 있는 상황은 총 5가지 이다.
-
1번에 적기 전에 전기가 나감
➜ 아무런 조치 필요 없음 -
1번에 New Data를 적다가 전기가 나감.
➜ ECC를 통해서 오류가 발생했음을 확인
➜ 2번에서 Old data를 가져와서 1번에 적는다. (roll back) -
1번 다 적고 2번 적기 전에 전기가 나감.
➜ 1번의 New Data를 2번에 덮어쓰기 -
2번에 New Data를 적다가 전기가 나감.
➜ ECC를 통해서 오류가 발생했음을 확인
➜ 1번에서 New data를 가져와서 2번에 적는다. (roll forward) -
1,2 번을 다 New Data로 바꾼 뒤에 전기가 나감.
➜ 아무런 조치 필요 없음
✏️ Clock Hardware
■ Clock Interrupt
Clock Interrupt의 발생 과정
- 하드웨어 내부에 존재하는 crystal에 전기를 가하면 perse 신호를 보낸다.
- perse가 올때마다 clock 값을 하나씩 감소시킨다.
- clock이 0이 되면 CPU에 Clock Interrupt를 건다.
- Clock 인터럽트가 걸리면, ISR로 점프한다.
➜ 주기적으로 CPU가 운영체제 코드를 실행하도록 한다.
Clock Interrupt Service Routine에서 운영체제가 해야하는 것
- 시간 유지
- 스케줄링
- CPU 사용정보 업데이트
- alarm 시그널을 요청한 서비스들이 있으면, 해줌 (Time service)
- Watchdog timer 서비스
- profiling, monitoring, statistics gathering
■ 시간 유지
시스템은 1970년 1월 1일을 기준으로 시간을 유지한다.
시간 유지 방식은 3가지 존재한다.
- 64 bit로 초 단위 유지
- 32 bit로 초 표현 + 나머지로 current seconds 표현
- 32 bit로 counter in ticks + boot 이후로 timer interrupt가 몇번 걸렸는가
■ Time Service
Timer Service
: 운영체제가 프로세스들이 특정 시간에 요구한 작업들을 수행한다.
Time Service를 어떻게 제공할 것인가?
➜ linked list를 사용한다.
- 요청들을 linked list로 연결한뒤, 각 요청은 몇 tick 후에 처리될 지 명시된다.
- 시간이 지날 때마다 가장 앞에 있는 요청의 tick 수를 감소시킨다.
- tick이 0이 되면 해당 요청을 수행한다.
■ Soft Timer
Linux에서 초당 timer interrupt는 100번 발생한다.
➜ time service의 처리 단위는 1/100초
∴ 1/1000초 단위 정확도로 요청한 것은 수행 불가
정확도를 위해 1/1000 단위로 timer interrupt 하기에는 overhead가 큼
∴ 가상으로 timer interrupt가 걸린 것처럼 실행하자 (soft timer)
운영체제 코드 실행 중간 중간에 요청이 있는지 검사하고, 요청이 있으면 가상 인터럽트를 걸어 처리
REFERENCE
📚 Modern Operating Systems, Third Edition - Andrew S. Tanenbaum
