✏️ TCP Brief
- 1:1 통신이다.
- full-duplex(양방향) 통신이다.
- Connection-Oriented
- Error Control을 제공한다. (Reliability)
- Flow Control을 제공한다.
- Congestion Control을 제공한다.
- Cumulative ACK 방식으로 동작한다.
- Sliding Window를 사용한다.
이 때, sequence number가 byte마다 부여되고 윈도우의 크기가 가변적이다.
용어 정리
-
MSS:
Maximum Segment Size -
Piggybacked ACK:
데이터 세그먼트의 Header에 ACK를 포함시켜서 보낸다.
Piggybacked ACK
ACK도 패킷이다.
ACK를 보내야하는데, 세그먼트로 만들어서 보내면 오버헤드가 매우 크므로 그냥 데이터 세그먼트를 보낼 때 ACK를 포함시켜서 보내는 방식이다.
하지만, 모든 상황에서 바로바로 데이터를 전송하는 것이 아니기 때문에, ACK를 포함시킬 데이터 세그먼트 조차 없을 수 있다.
이 경우에는 타이머를 사용해서, 일정 시간동안 세그먼트가 만들어지지 않으면 ACK를 위한 세그먼트를 만들어서 보낸다.
✏️ TCP Segment
sequence Number는 연속적이지 않을 수 있다.
TCP에서 sequence Number는 세그먼트의 첫 바이트를 기준으로 할당된다.
예를 들어, 1000 Bytes의 데이터를 보내는데 MSS가 100 Bytes인 경우, 세그먼트는 100개로 분할된다.
그럼 첫 세그먼트의 sequence Number는 0, 두 번째는 100, 세 번째는 200... 이런식으로 증가한다.
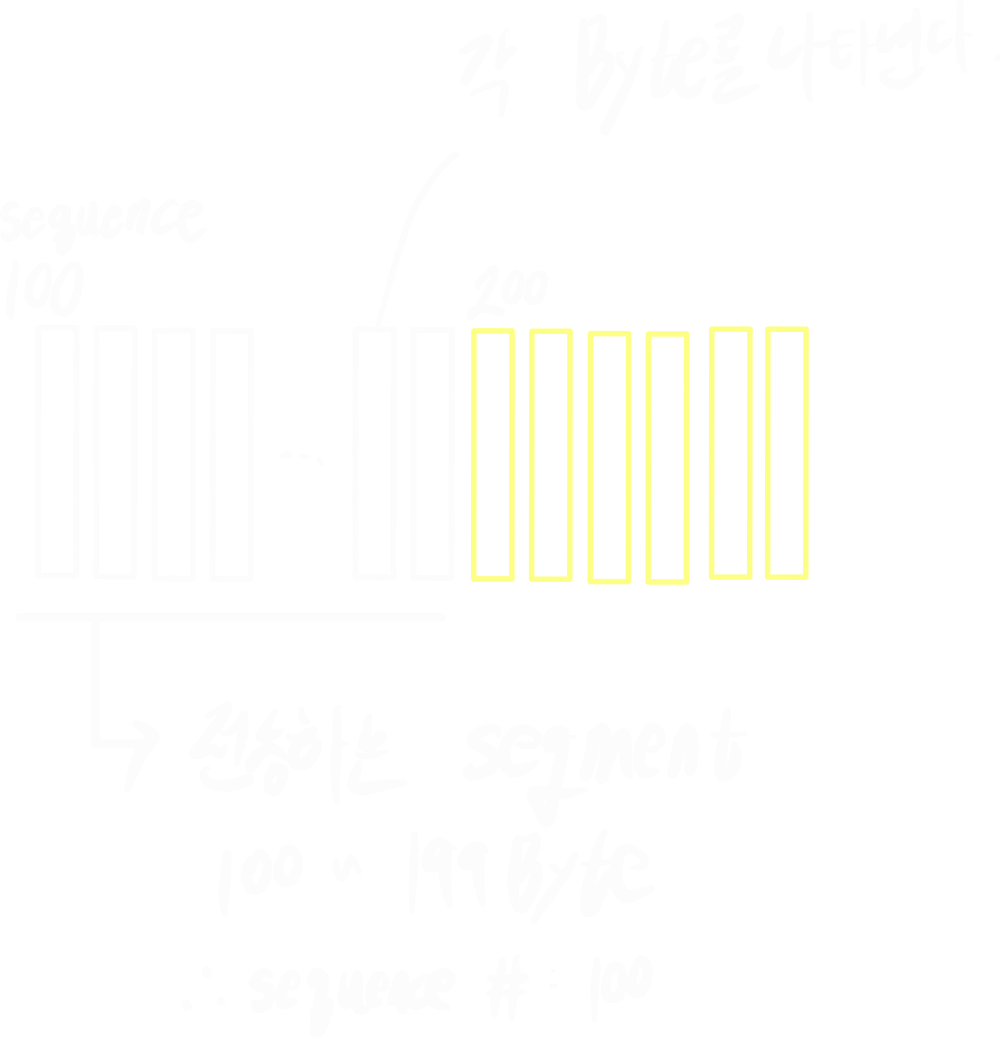

- sequence Number: 2^32-1 사용가능
- 송신하는 데이터의 가장 첫 Byte Number를 sequence Number로 넣어 보낸다.
- ACK Number: 2^32-1 사용가능
- 순서에 맞게 잘 받은 Byte 중 가장 마지막 Byte Number + 1을 보낸다.
- 헤더 길이: 고정 헤더와 가변 헤더의 길이의 합을 넣는다.
- Receive Window: flow Control을 위해 사용되는 영역
수신 buffer의 가용 Byte 수를 넣는다.
✏️ TCP Time out
TCP에서 재전송 타이머는 1개만 사용한다.
하지만, 이전에 보낸 세그먼트가 Time Out 되었다고 해서 다음 세그먼트 모두를 재전송하지는 않는다.
∴ TCP는 Go-Back-N이랑 Selective Repeat의 짬뽕
■ 적절한 Time out 시간
Time out 시간은 최소한 RTT보단 커야된다.
- 너무 작으면?
조기 Timeout - 너무 크면?
Loss 발생에 느린 대처
적당한 시간은 다음과 같이 EWMA 방식을 사용해서 도출한다.
EstimatedRTT_(n) = (1-a)*EstimatedRTT_(n-1) + a*SampleRTT_(n)
- EstimatedRTT_(n): 패킷의 RTT 예측 값
- SampleRTT_(n): 패킷의 실제 RTT 값
재전송인 경우 제외 - 오래된 것에는 가중치를 적게 주고 최근 것에는 가중치를 많이 준다.
하지만, 생각보다 값이 너무 작게 나오는 문제가 발생한다.
➜ DevRTT로 해결
예상 RTT = EstimatedRTT + 4*DevRTT
DevRTT = (1-b)*DevRTT + B*|sampleRTT-EstimatedRTT|
재전송 타이머의 값
➜ 오리지널 타이머의 2배가 된다.
✏️ Reliable Data Transfer
가정
No flow Control
No Congestion Control
TCP는 Loss에 어떻게 대처하는지 알아보자.
■ Sender
Sender에서는 한개의 Retransmission Timer를 사용한다.
| Event | Action |
|---|---|
| 상위 계층에서 데이터 전송 요청 | 타이머 시작(sequence Number는 세그먼트의 첫 Byte Number) |
| Time Out | 1. ACK 받지 못한 세그먼트 중 가장 작은 sequence Number를 가진 세그먼트 재전송 2. 타이머 시작 |
| ACK(n) 받음 | 1. ACK(n) 이전에 ACK 받지 못한 세그먼트들을 모두 ACK 받았다고 처리(Cumulative ACK) 2. sequence n 이후에 보낸 세그먼트가 있으면 Timer start |
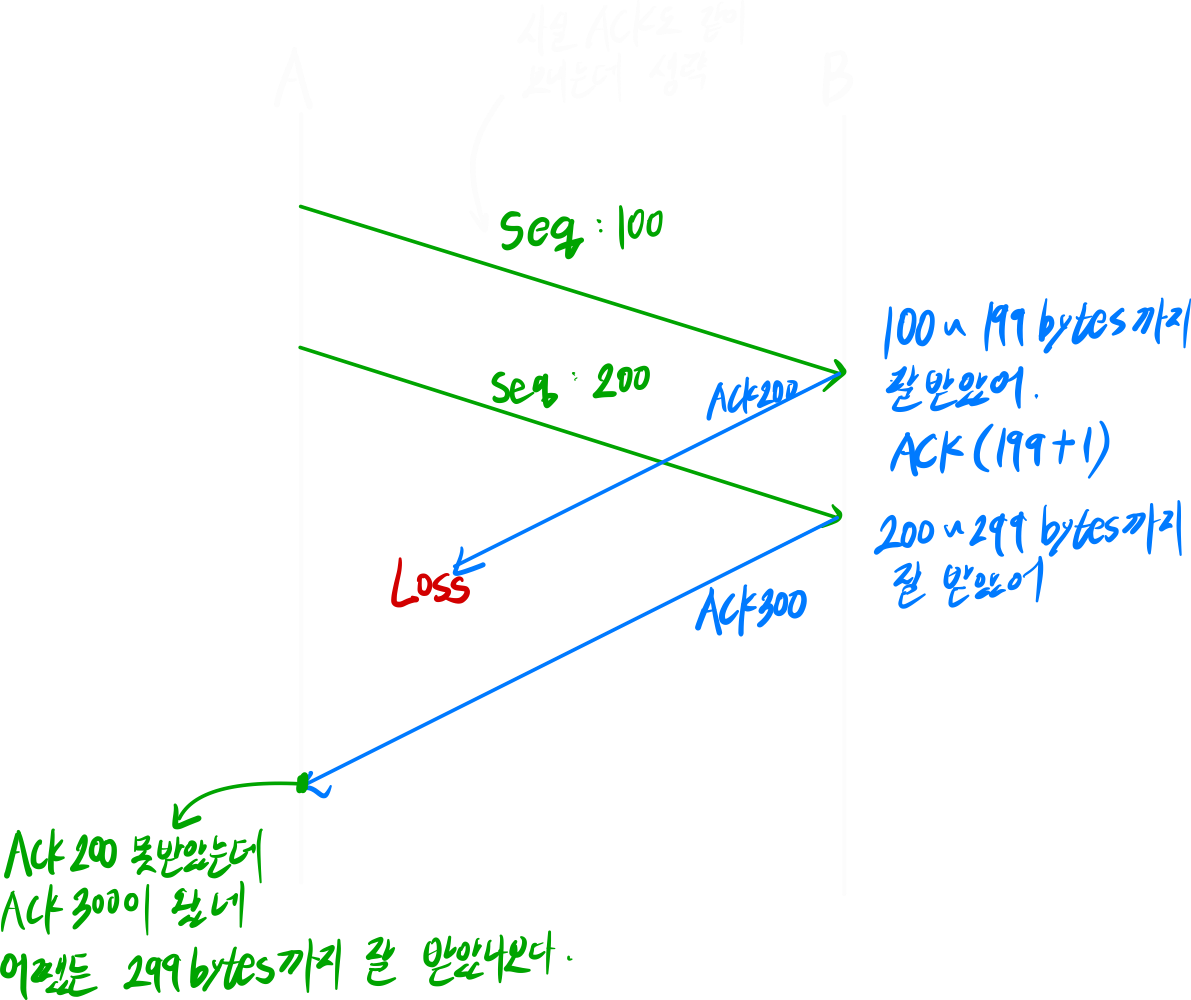
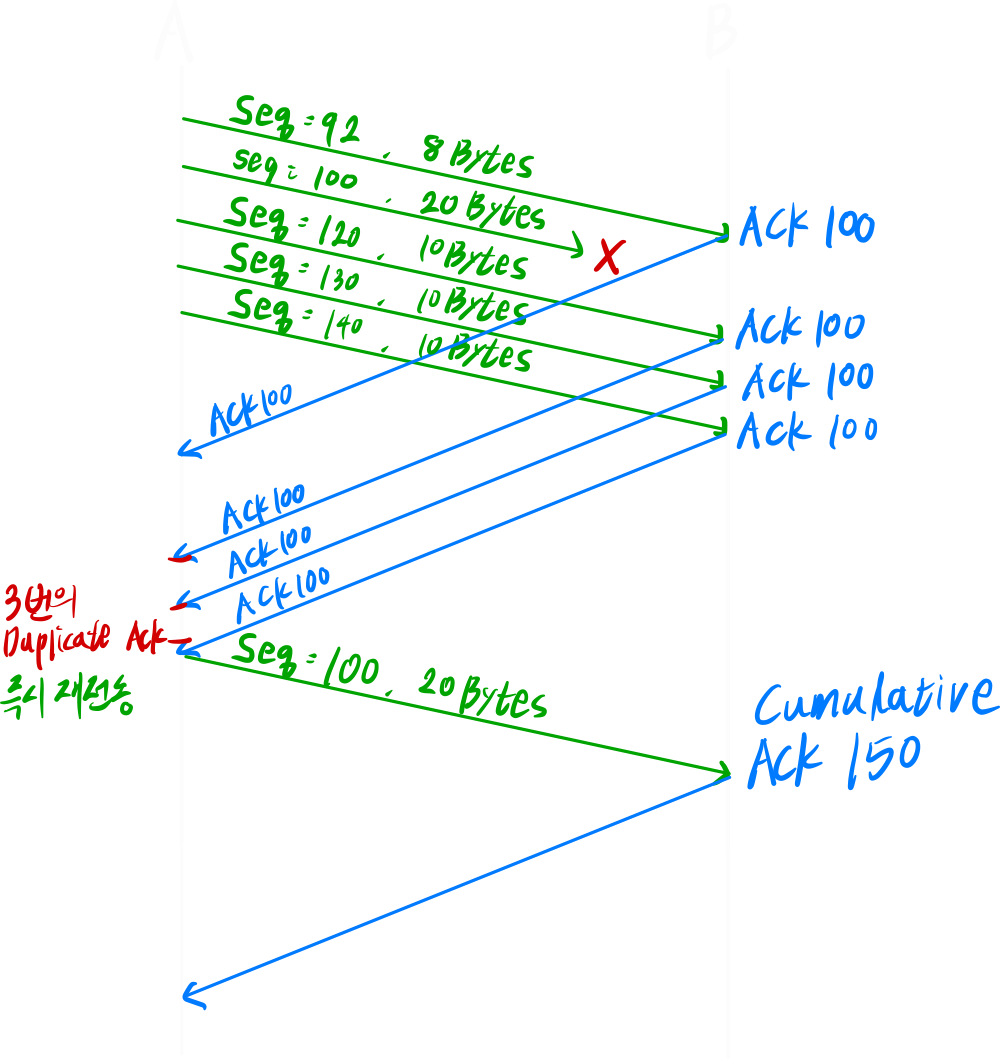
Event ③
A가 보낸 sequence 100을 잘 수신한 B는 ACK 200을 보낸다. 하지만, Loss가 발생한다.
A가 보낸 sequence 200을 잘 수신한 B는 ACK 300을 보낸다.
A는 ACK200을 받지 못했지만 TCP의 기본 동작은 Cumulative ACK이기 때문에 sequence 100, 200 패킷이 잘 전송되었다고 판단한다.
■ Receiver
Receiver 에서는 한개의 piggyback 타이머를 사용한다.
| Event | Action |
|---|---|
| 순서에 맞는 세그먼트 도착. 이전 세그먼트는 모두 ACK 보냈음 | Delayed ACK. ACK 보내는 것을 지연한다. - 보낼 데이터가 500ms 안에 생기면, ACK를 얹어서 보낸다.(PiggyBacked ACK) - 보낼 데이터가 안생기면, ACK를 위한 세그먼트를 만들어서 보낸다. |
| 순서에 맞는 세그먼트 도착. 이전 세그먼트 중 아직 ACK 전송을 기다리는 세그먼트가 존재 | 즉시 Cumulative ACK를 전송한다. |
| 순서에 맞지 않는 세그먼트 도착. 예상 했던 sequence Number보다 큼 즉, 이전에 송신측에서 보낸 세그먼트가 Loss 되었음 | 즉시 Duplicate ACK를 전송한다. 즉, 순서대로 잘 받은 Byte + 1 전송 송신측에서는 이미 해당 ACK를 받은 것이므로 Duplicate ACK이다. |
| 순서를 끼워 맞춰줄 세그먼트 도착. Event ③, ④가 순차적으로 발생하면, 중간에 못받은 세그먼트가 존재할 것이다. 그 세그먼트가 도착한 경우 | 즉시 ACK 전송 |
A가 보낸 sequence 100을 잘 수신한 B는 ACK 200을 보낸다.
A가 보낸 sequence 200은 Loss
A가 보낸 sequence 300을 잘 수신했지만, 순서대로 오지 않았기 때문에 순서대로 온 데이터 중 가장 큰 Byte + 1을 보낸다.(ACK200)
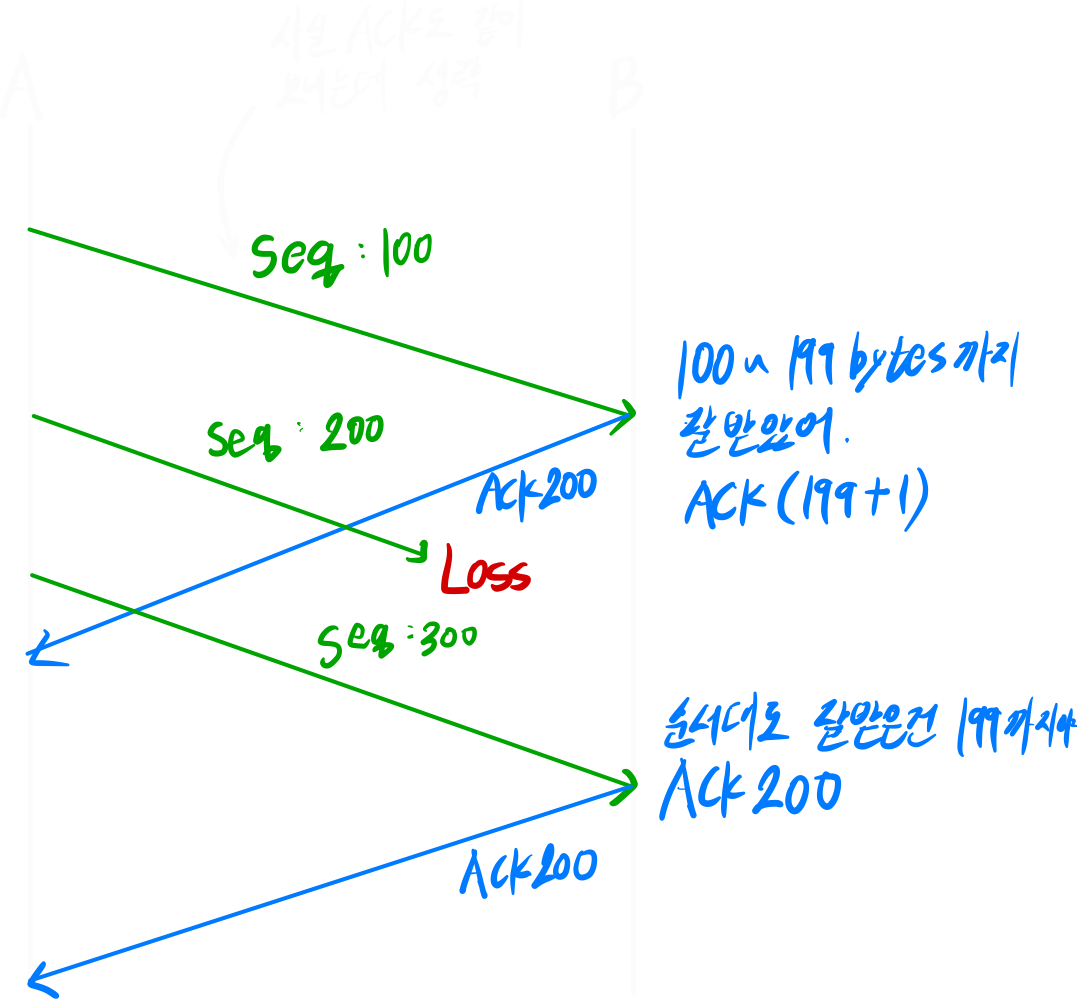
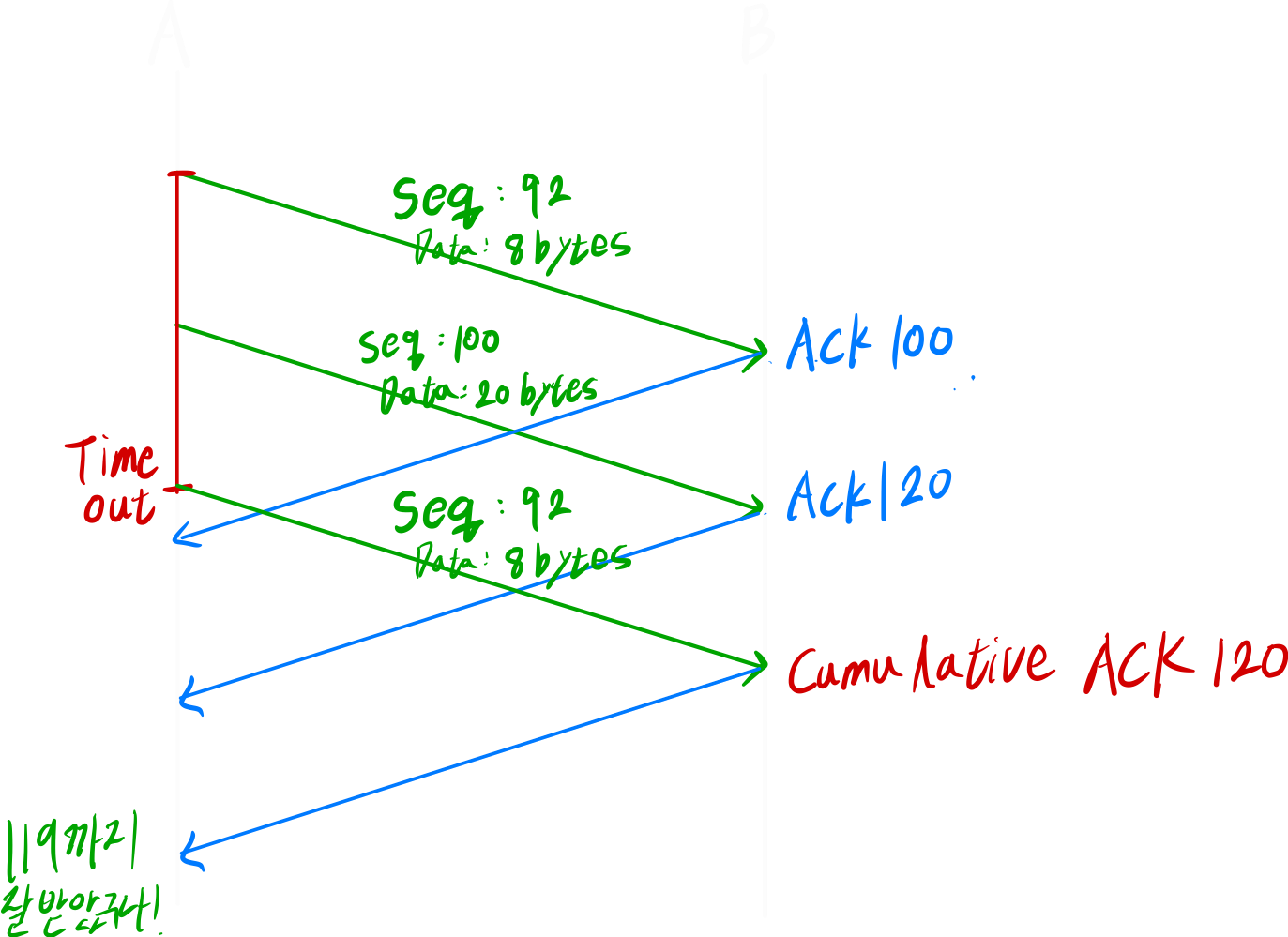
여러 시나리오들
- Premature Timeout 발생
- 3번의 duplicate ACK (fast Retransmit)
Original ACK + 3번의 duplicate ACK가 발생하면 Time out이 발생하지 않아도 즉시 재전송한다.// 송신측 fast Retransmit 알고리즘 ACK(y) 수신 if(y > sendBase){ sendBase = y if(전송했지만 ACK 못받은 패킷 존재) start timer } else { // 이 코드가 실행된다는 것은 duplicate ACK를 받았다는 것 duplicateACK_y++; if(duplicateACK_y==3){ retransmit(y); } }
✏️ Flow Control
Flow Control: 수신할 공간이 있는지 보고 보낼 양을 조절한다.
수신측의 가용 버퍼 공간을 초과하면 안된다!
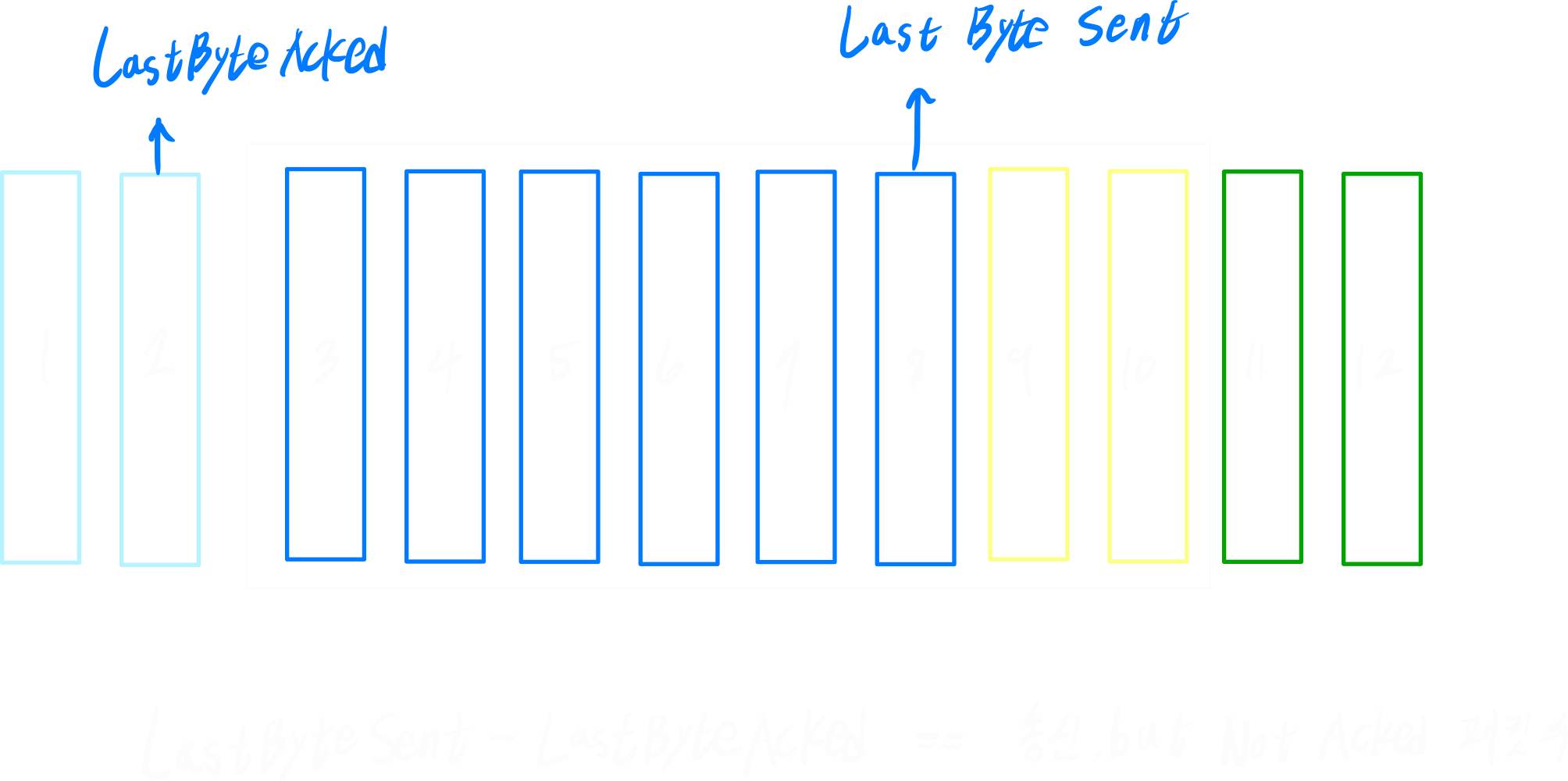
- 수신측의 가용 버퍼 공간(rwnd)
rwnd(Receive Window) = RcvBuffer - (LastByteRcvd - LastByteRead)- RcvBuffer: 총 수신버퍼 크기
- (LastByteRcvd - LastByteRead): 채워져 있는 수신 버퍼의 크기
- 송신할 때, 【 송신했지만 ACK를 받지 못한 패킷 】의 수가 rwnd를 넘지 말아야 한다.
LastByteSent - LastByteAcked <= rwnd
✏️ TCP Connection
TCP의 Connection을 Session이라 한다.
■ Session 설정
Session 설정할 때 주고 받는 정보는 다음과 같다.
- 서버측 sequence number
- 클라이언트측 sequence number
- 송신측의 Rcv Buffer Size
- 수신측의 Rcv Buffer Size
이 외에도 다양한 정보를 주고받는다.
■ 3 Way Handshake
- 송신: request Connection
- 수신: Roger
- 송신: good Copy
세그먼트 안에 3개의 Flag(R, S, F)가 존재한다.
그 중, S가 연결에 관한 플래그이다.
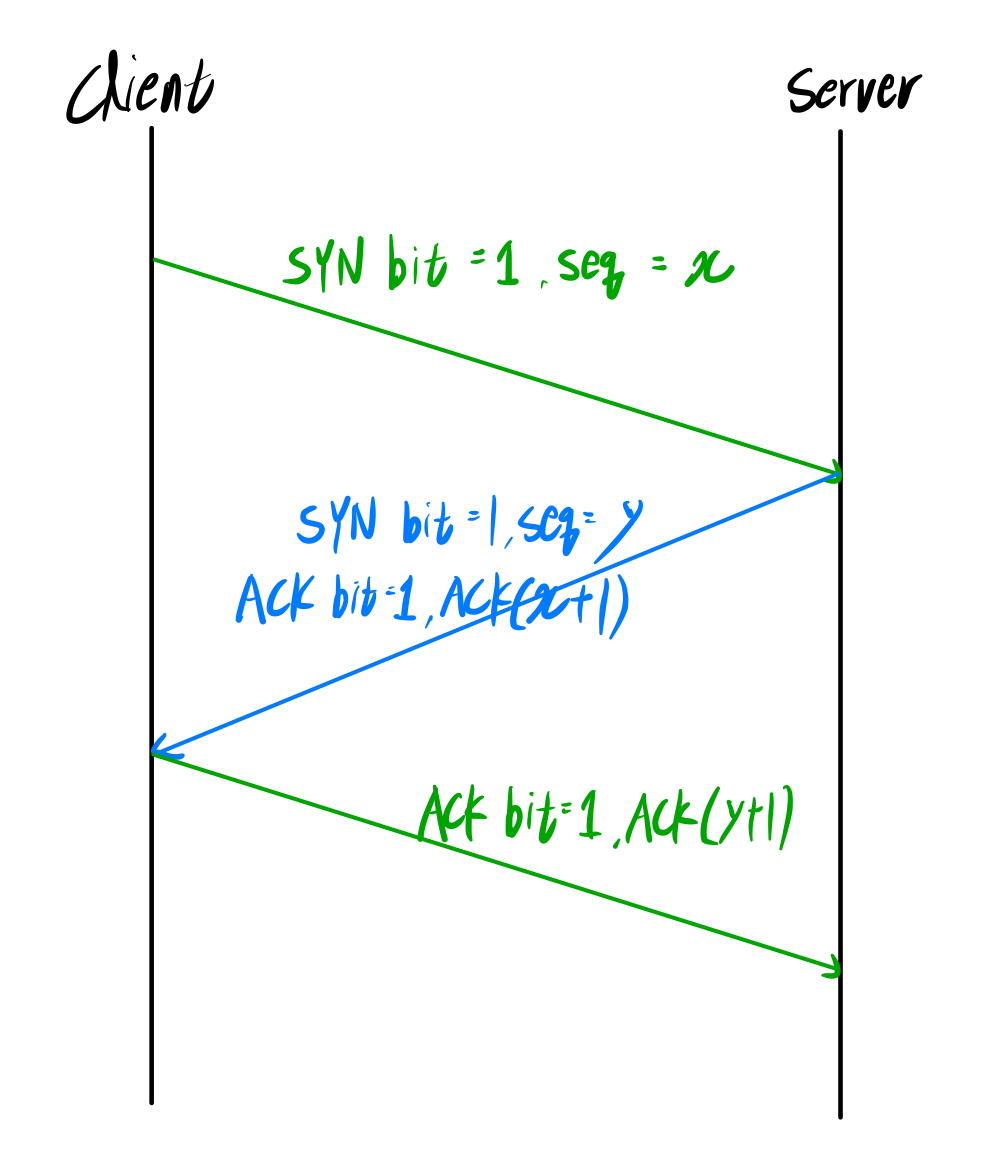
3 Way Handshake는 다음과 같이 이루어진다.
- 송신: SYNbit=1, 자신의 초기 sequnce number(x)
- 수신: SYNbit=1, 자신의 초기 sequnce number(y)
ACKbit=1, ACKnum=x+1- 송신: ACKbit=1, ACKnum=y+1
■ Closing Connection
F(Fin) flag(bit)를 1로 설정해서 보낸다.
- 송신: FIN
- 수신: ACK
- 수신: FIN (closed)
- 송신: ACK후 30초 대기
Time wait후 closed
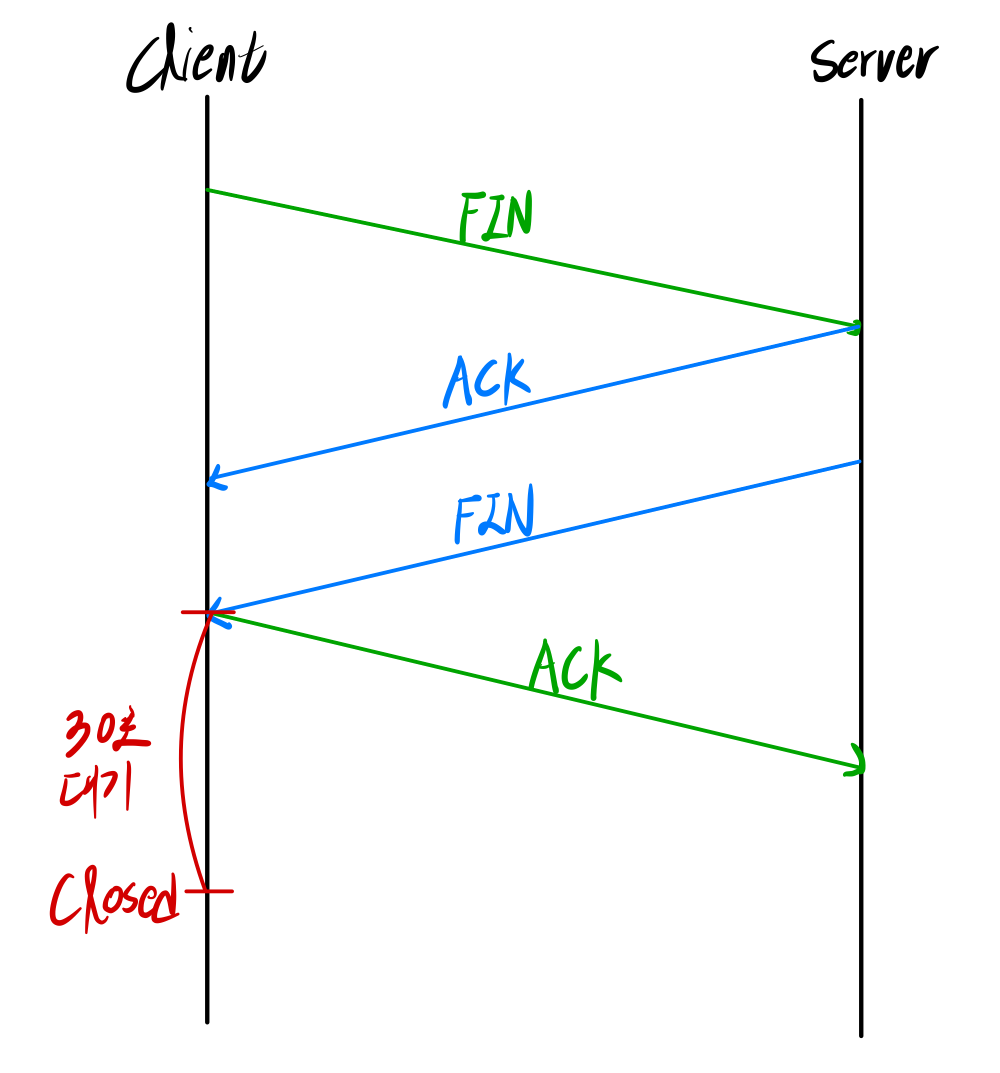
도착할 수 있는 오래된 패킷들을 처리하기 위해서 잠시동안 close를 대기한다.
✏️ Congestion Control
너무 많은 데이터를 "네트워크"로 보냈을 때 처리가 버겁다.
따라서, Congetsion Control이 필요하다.
- Flow Control: end-end 문제, 송수신자 간 속도 맞추기
- Congestion Control: network 전반의 문제
Congestion이 커지면
- delay가 커지고
- loss가 많이 발생한다.
Congetsion Control의 종류
-
Network-assisted Congestion Control
: 라우터가 개입하여 Congestion Control을 돕는다. -
End-End Congestion Control
: 라우터의 개입없이, end host끼리 문제를 해결한다.
■ Network-assisted Congestion Control
실제 TCP에서도 이 방법을 개선해서 사용한다.
라우터가 feedback 정보(choke packet)를 sender/receiver에게 보낸다.
congestion의 원인 제공자는 source이다.
➜ TCP sender 문제
-
ECN(Explicit Congestion Notification)이라는 프로토콜이 사용하는 방식이다.
TCP와 같이 사용하기도 한다. -
ATM, DECbit이라는 프로토콜도 있지만 ECN이 널리 사용된다.
■ End-End Congestion Control
router와 무관하게 동작하는 방식이다.
end host에서 loss, delay를 통해 Congestion을 추측한 뒤 조절한다.
다음 장에서 더 자세히 알아보자.
✏️ Network-assisted Congestion Control
ECN(Explicit Congestion Notification)을 사용한다.
Router의 역할
- 혼잡이 발생하는 경우, Router가 이를 확인한다. (혼잡의 기준은 표준으로 정해져있지 않다.)
- 혼잡을 확인한 router는 IP header에 존재하는 ECN 필드를 1로 바꾼다.
- router는 end point에 이 정보를 보낸다.
end point의 역할
end point는 어느 라우터가 이 필드를 설정했는지 알지 못한다.
- source - dest 경로간 문제가 있음을 파악한다.
- dest는 source에게 TCP ACK segment 중 ECE flag를 1로 해서 보낸다.
- source는 경로 상에 혼잡에 있는 것을 인지하고 sending rate(window 크기)를 줄인다.
⚠️ ECN은 3계층이고, TCP는 4계층이다.
⚠️ Router는 3계층 장비이기 때문에 IP 헤더의 ECN bit만 건드릴 수 있다.
✏️ End-End Congestion Control
TCP에서 실제로 사용하는 Congestion Control 방식에 대해서 알아보자.
■ AIMD
Additive Increase Multiplicative Decrease
TCP 송신 윈도우 크기가 Addictive(linear)하게 올라가다가, Multiplicative(half)하게 줄어들음
- 윈도우 크기가 작아지는 시점은 loss가 발생했을 때이다.
- 아래의 두 경우 중 하나가 발생하면 Loss로 판단한다.
- Time out
- 3 Duplicate ACK
■ Details
더 자세히 알아보자.
송신할 때, 반드시 다음과 같은 규칙을 지켜야 한다.
-
LastByteSent-LastByteAcked <= min(cwnd,rwnd)
즉,송신 윈도우 크기 <= min(congestion window 크기, receive window 크기) -
Congestion control을 공부하고 있는 중이므로, rwnd가 cwnd보다 크다고 가정한다.
∴LastByteSent-LastByteAcked <= cwnd -
loss가 detect되기 전까지는 윈도우 크기(cwnd)를 1MSS씩 증가시킨다.
➜ Addictive Increase -
loss가 detect되면 윈도우 크기(cwnd)를 반으로 줄인다.
➜ Multiplicative Decrease
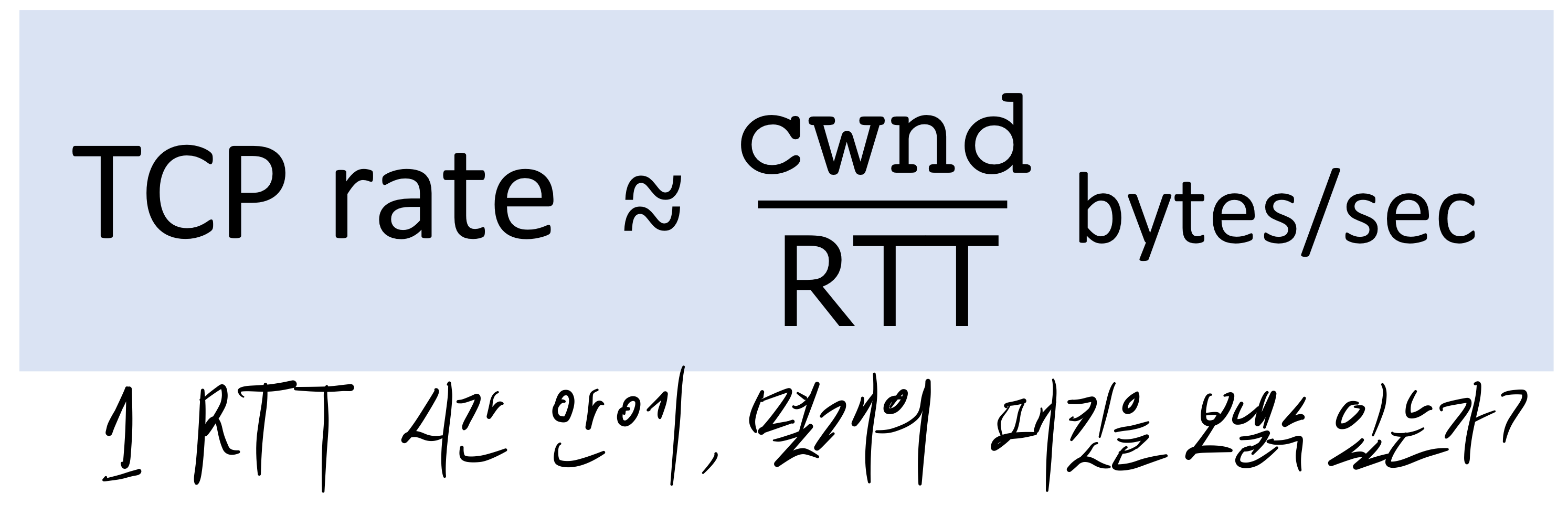
■ Slow Start
통신이 시작되면, first Loss가 발생하기 전까지 윈도우 크기를 Exponential하게 늘린다.
- 초기 윈도우 크기 1
- ACK 받으면 두배씩 윈도우 크기를 늘림
■ Congestion Avoidance
패킷의 개수가 일정수준(slow start threshold) 에 다다르면 더이상 Slow Start로 동작하지 않고, Congestion Avoidance로 동작한다.
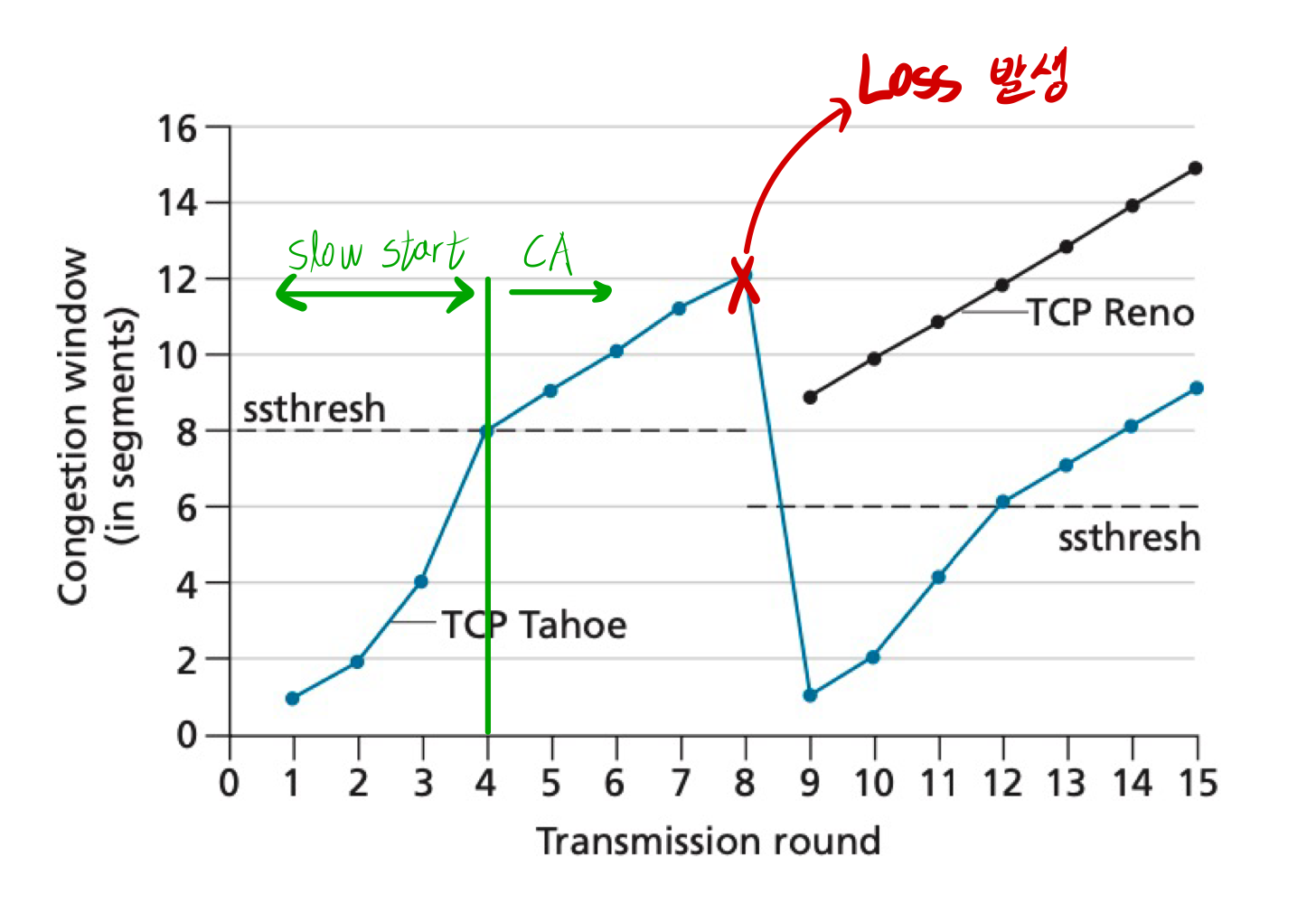
- slow start로 더이상 동작하지 않고, RTT마다 1씩 window 크기가 증가한다.
- loss가 발생하는 경우, loss가 발생된 시점의 cwnd의 절반으로 ssthresh가 설정된다.
∴ 위의 경우ssthresh == 6
- 초창기(TCP Tahoe)에는 loss가 발생한 시점에 window 크기를 1로 줄였다.
- 현재(TCP Reno)는 loss가 발생한 시점에 window 크기를
ssthresh + 3으로 줄인다.
■ Finite State machine
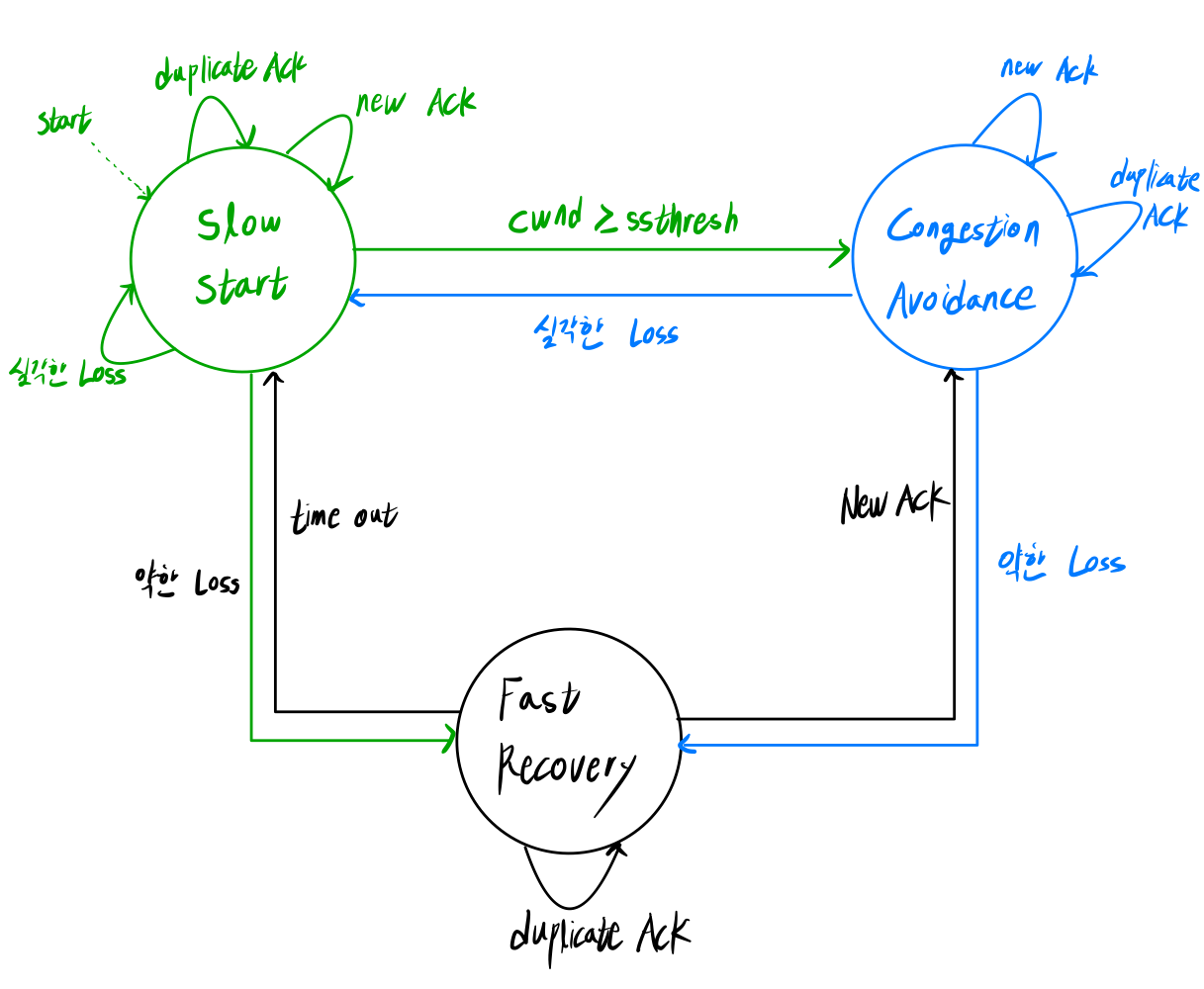
Slow Start
State Event Action ➜ SS start cwnd를 1MSS로 설정
ssthresh를 64KB로 설정
dup ACKcount를 0으로 설정루프 duplicat ACK 수신 dup ACKcount++ 루프 new ACK 수신 cwnd+=MSS
dup ACKcount = 0
새로운 세그먼트 전송SS ➜ fast Recovery 약한 Loss 발생(dup ACKcount == 3) ssthresh = cwnd/2
cwnd = ssthresh + 3
retransmit루프 심각한 Loss 발생(time out) ssthresh = cwnd/2
cwnd = 1MSS
dup ACKcount = 0
retransmitSS ➜ CA cwnd >= ssthresh NONE
Congestion Avoidance
State Event Action 루프 duplicat ACK 수신 dup ACKcount++ 루프 new ACK 수신 cwnd = cwnd + MSS*(MSS/cwnd)
dup ACKcount = 0
새로운 세그먼트 전송CA ➜ SS 심각한 Loss 발생(time out) ssthresh = cwnd/2
cwnd = 1MSS
dup ACKcount = 0
retransmitCA ➜ fast Recovery 약한 Loss 발생(dup ACKcount==3) ssthresh = cwnd/2
cwnd = ssthresh + 3
retransmit
cwnd = cwnd + MSS*(MSS/cwnd) 는 linear하게 증가함을 뜻한다.
예를 들어, cwnd가 100이고 MSS가 10이면 cwnd는 1만큼 증가한다.
즉, ACK가 10번 와야 1 MSS만큼 증가된다.
Fast Recovery
State Event Action FR ➜ SS Time out ssthresh = cwnd/2
cwnd = 1
dup ACKcount = 0
retransmitFR ➜ CA New ACK 수신 cwnd=ssthresh
dup ACKcount = 0루프 duplicate ACK 수신 cwnd += 1MSS
새로운 세그먼트 전송
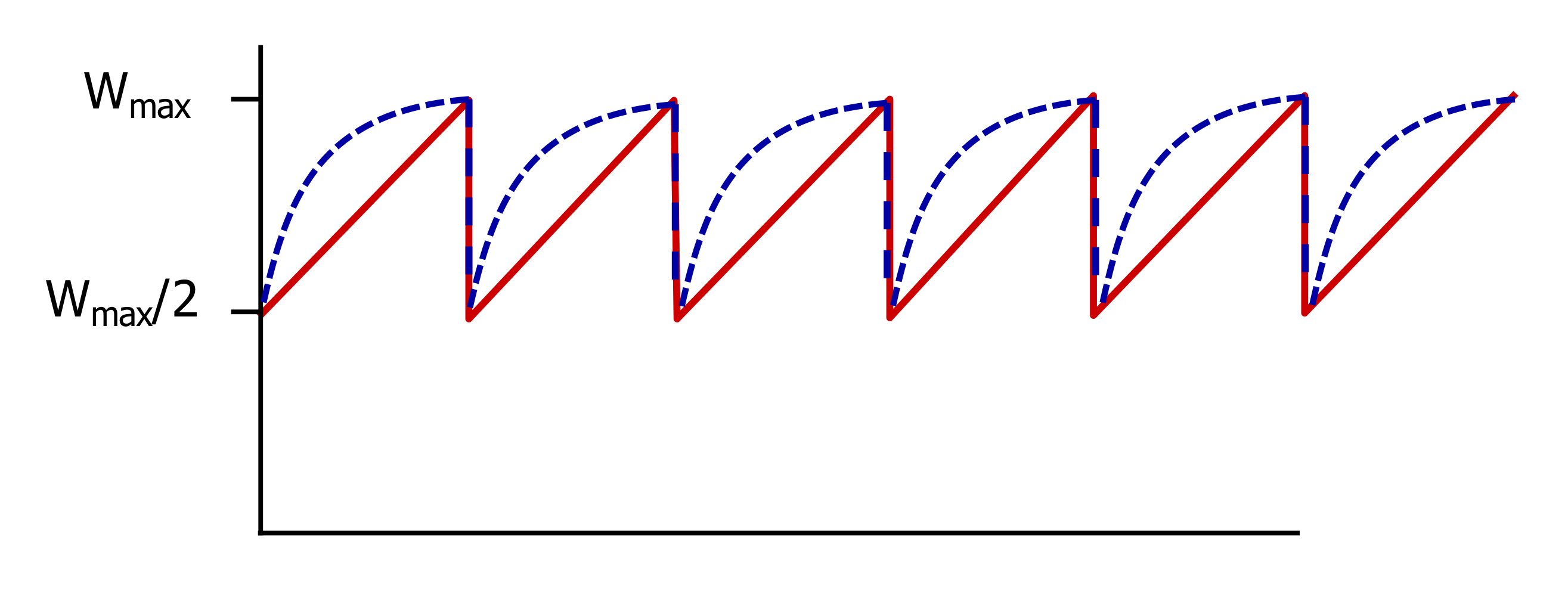
✏️ TCP CUBIC
W_max: Loss가 발생한 지점의 cwnd 값
여유가 있으면(Congestion이 일어나려면 한참 멀었다) cwnd를 많이 증가시키고, W_max와 가까우면 천천히 증가시키는 방법이다.
- K는 cwnd가 WMAX에 도달할거라고 예측되는 시점
- cwnd는 time과 K 사이의 거리의 3제곱으로 속도를 증가시킨다.
✏️ Delay Based Congestion Control
Congestion은 Bottleneck link에 연결된 라우터에서 발생한다.
sending rate를 늘려도 Bottlenect link 때문에 throughput은 증가되지 않는다.
이전까지의 알고리즘은 Loss를 경험한 뒤에 cwnd 값을 조정했다.
Delay Based Congestion Control은 Loss를 경험하지 않고, RTT를 기반으로 cwnd 값을 조정한다.
-
RTTmin: Congestion이 발생하지 않은 가장 좋은 상황
- 이 경우 Throuhput = cwnd/RTTmin
-
위의 Throughput에 가깝다
➜ 여유가 있다.
➜ cwnd를 증가시킨다. -
위의 throughput에 한참 못미친다
➜ 여유가 없다.
➜ cwnd를 감소시킨다.
Delay Based Congestion Control의 예시
- BBR 알고리즘
✏️ TCP fairness
TCP는 공평하다.
TCP Session은 공평하게 link를 공유한다.
처음에는 공평하지 못하지만, 통신을 지속하다보면 공평해진다.
ex) TCP Session이 2개 존재한다.
1. 처음에는 Throughput이 불공평하게 분배될 수 있다.
2. Addictive하게 증가하다보면 Loss가 발생한다.
3. 각각 cwnd를 절반으로
4. 조금 fair 해짐
5. 2-4 과정 반복
결국 fair 해진다.
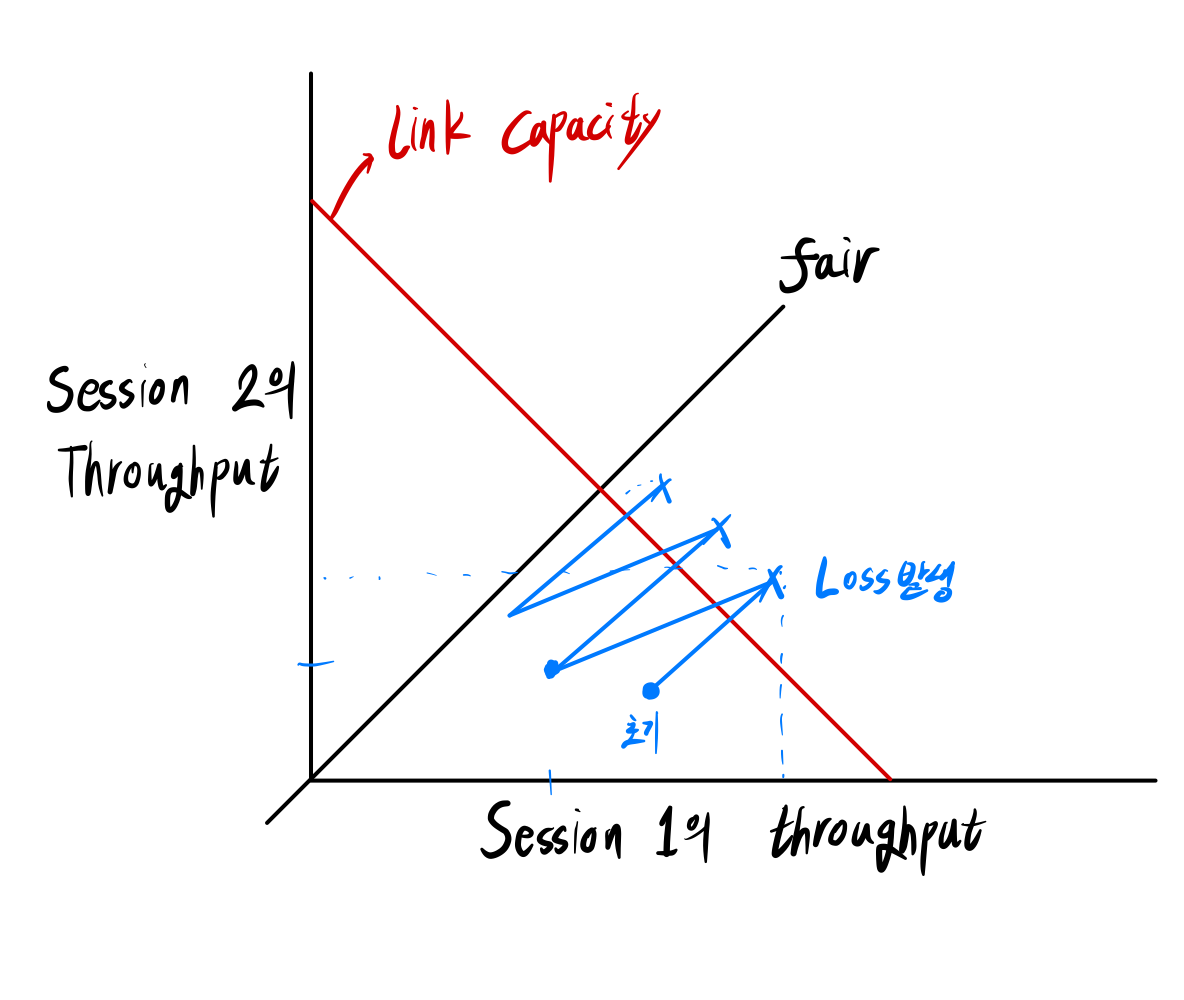
■ Fair의 조건
- Same RTT
- session의 개수 고정
- AIMD를 사용한다
■ TCP가 항상 공평한가?
이미 9개의 Session이 열려져 있는 경우,
- 하나의 app에서 1개의 Session을 추가로 연결
- 이 앱은 R/10을 받음
- 하나의 app에서 11개의 Session을 추가로 연결
- 이 앱은 R/2을 받음
Session을 많이 열수록 유리하다는 문제가 존재한다!
■ UDP
UDP는 Congestion Control이 없다.
따라서 fairness하지 않다.
✏️ New Transport Layer functions
TCP, UDP는 40년 전에 만들어진 protocol이기 때문에, 새로 발생한 문제점들을 해결하기 위해 Protocol을 각각의 link에 맞게 재설계 또는 수정했다.
| link | 문제점 |
|---|---|
| Long, high speed pipe | 너무 많은 패킷이 link안에 존재 |
| Wireless network | 간섭으로 인한 loss 발생 |
| Long-delay link | Long RTT |
| Data center Networks | Latency에 민감함 |
| Background traffic flows | 우선순위 낮음 |
따라서, 새로운 protocol들이 많이 나왔다.
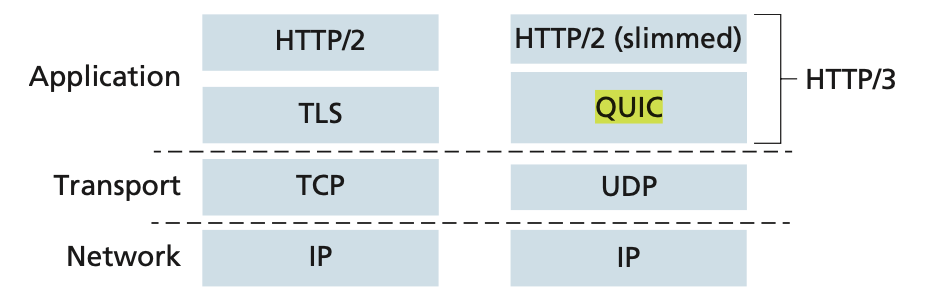
■ QUIC
QUIC는 application layer protocol이다.
실제로는 application layer에서 동작하지만 transport 기능을 해준다.
- Connection Oriented
- HTTP/3
- UDP 기반
- Congestion Control
- error control
- 보안있음 (TLS를 대체함)
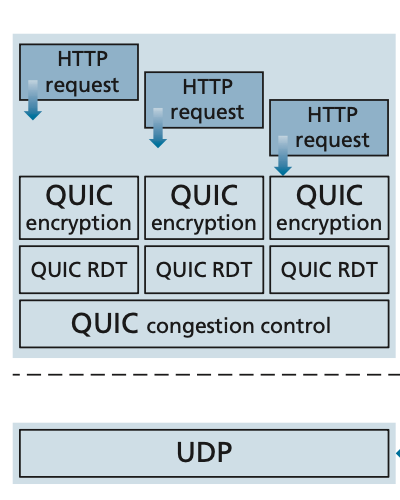
- multiplex: stream 여러개가 하나의 QUIC connection을 사용한다.
- Per Stream based Reliability
⚠️ TCP는 3 way handshake를 해야했지만, QUIC은 1RTT 안에 끝난다.
⚠️ Reliability는 stream 단위, Congestion Control은 connection 단위
REFERENCE
Computer Networking, A Top Down Approach - JAMES F.KUROSE
