최근 데이터의 양과 다양성이 급격히 증가하면서, 효율적인 데이터 파이프라인 구축의 중요성이 그 어느 때보다 커졌다. 특히, 실시간 데이터 조회와 수정, 운영 비용 절감, 스키마 진화의 간소화, 쿼리 성능 최적화와 같은 도전 과제들이 주요 이슈로 떠오르고 있다.
이미 데이터 레이크하우스에서 핵심 구성 요소로 Apache Iceberg를 사용하는 중이다.
Apache Iceberg 는 스스로를
"The Open Table Format for analytic Datasets" 이라고
소개하고 있다.
'테이블 포맷'은 쉽게 말해 "수많은 데이터 파일들을 어떻게 관리하고, 사용자에게 하나의 번듯한 표(Table)처럼 보이게 할 것인가"에 대한 규칙 모음을 적용해주는 도구다.
1. 테이블 포맷이란?
먼저 최근 비정형 데이터의 폭발적인 증가와 함께 로그, 이미지, IoT 센서 데이터 등등 RDBMS 로는 담을 수 없는 형식의 데이터들이 늘어나게 되면서 데이터를 있는 형태 그대로 , 또는 나눠서 저장하는 저장 방식이 자연적으로 따라 증가하게 되었으며 그 저장소도 다양하게 확장이 유연하고 비용이 저렴한 Object Storage , Document DB , Graph DB , HDFS 등도 사용률이 늘어나게 되었다.
데이터 레이크(S3, HDFS 등)에 데이터를 저장하면, 거대한 크기의 데이터 하나를 통째로 올리는 것이 아니라 성능과 관리 효율을 위해 parquet나 avro 같은 수만 개의 파일로 흩어져 저장된다.
예를 들어, sales라는 테이블이 있다면 S3 경로상에는
s3://my-bucket/sales/dt=2024-01-01/part-0001.parquet, part-0002.parquet식으로 파편화되어 존재하게 된다.
하지만 이렇게 저장할 경우 , 데이터 직군들 이나 데이터 사용자는 SQL로 SELECT * FROM table을 하고 싶어도 할 수 없는 상태가 된다. 이는 여러 문제 상황에 빠지게 된다.
-
파일 목록의 부재: "어떤 파일들이 sales 테이블의 최신 데이터인가?"를 알기 위해 수만 개의 파일을 일일이 스캔해야 한다.
-
트랜잭션 부재: ACID 가 보장되지 않아, 누군가 데이터를 쓰는 도중에 읽으면(SELECT), 파일이 생성 중이라 깨진 데이터를 읽거나 불완전한 결과를 얻게 된다.
-
스키마 불일치 문제: 1번 파일은 컬럼이 5개인데, 100번 파일은 컬럼이 6개라면 SQL 쿼리 엔진은 혼란에 빠지게 된다.
테이블 포맷은 이 무수한 파일들 위에 씌워진 '추상화 레이어'로써, 어떤 파일이 현재 테이블의 유효한 데이터인지, 스키마(컬럼명, 타입)는 무엇인지에 대한 정보를 관리한다.
결국 "수만 개의 파일 덩어리" = "하나의 논리적인 테이블"
처럼 보이게 해주는 소프트웨어가 필요해졌고,
그것이 바로 Apache Iceberg, Delta Lake, Huddle 같은 테이블 포맷(Table Format)이다.
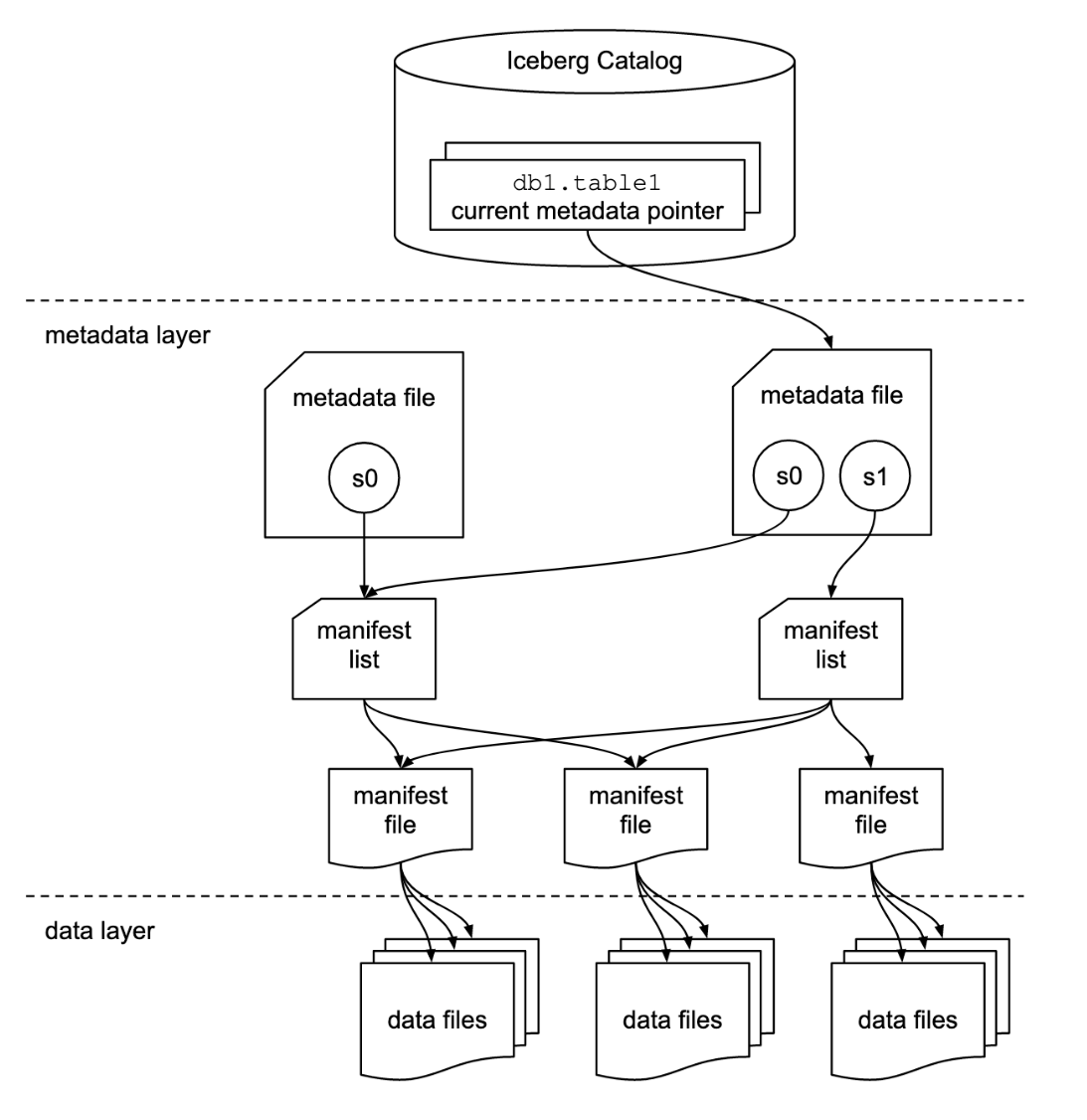
Iceberg의 Table Format 의 설계 핵심은 데이터와 메타데이터를 분리하여 저장하는 구조이다. 이를 통해 데이터의 파티셔닝, 스키마 진화, 트랜잭션 처리 등을 유연하게 관리할 수 있게 되었디.
| 계층 (Layer) | 주요 역할 | 대표적인 예시 |
|---|---|---|
| 1. 카탈로그 (Catalog) | 어떤 테이블들이 어디에 있는가? 를 관리하는 주소록 | AWS Glue, Hive Metastore, Unity Catalog |
| 2. 테이블 포맷 (Metadata) | 특정 테이블을 구성하는 파일 목록과 스키마는 무엇인가? 를 관리 | Apache Iceberg, Delta Lake, Hudi |
| 3. 데이터 (Storage/File) | 실제 로우 데이터가 저장된 물리적 파일 | Parquet, Avro, JSON, CSV (S3/HDFS 저장) |
기존 데이터 레이크의 문제
기존 데이터 레이크의 핵심은 '폴더 구조'에 의존했다.
1. 파티셔닝 문제
폴더 이름이 곧 데이터다
기존 방식(Hive)은 물리적인 디렉토리 구조로 파티션을 구분했다.
예: s3://my-bucket/sales/year=2024/month=03/day=05/data.parquet이 방식에서 발생하는 여러가지 문제가 있었다.
Directory Listing 부하
데이터가 수만 개의 파일로 쪼개져 있으면, SELECT * 를 할 때 엔진은 S3나 HDFS의 모든 폴더를 뒤져서 파일 목록을 가져와야 한다. 파일이 수백만 개가 넘어가면 List API 요청 비용 증가 및 성능 저하(Latency)가 발생, 목록 만들기 단계에서만 몇 분이 걸리게 된다.
Iceberg는 폴더를 뒤지지 않는다. Manifest File(Avro)이라는 메타데이터 안에 읽어야 할 파일 목록과 통계 정보(Min/Max 등)를 미리 적어둔다.
사용자 실수 유발
기존 방식은 보통 물리적 컬럼(year, month)과 비즈니스 컬럼(order_date)이 분리되어 있다. 사용자가 물리적 구조를 모르면 풀 스캔(Full Scan)이 일어나는 '데이터 아키텍처 노출' 현상이 발생한다.
분석가가 쿼리를 짤 때 WHERE year=2024 AND month=03처럼 파티션 컬럼을 정확히 명시해야만 속도가 빠릅니다. 만약 실수로 WHERE order_date = '2024-03-05'라고 쓰면, 엔진은 파티션 기능(Pruning)을 쓰지 못하고 전체 데이터를 다 읽어버리는 대참사가 발생한다.
Iceberg 에서 사용자는 그냥 WHERE order_date = '2024-03-05'라고만 쿼리해도, Iceberg가 내부적으로 "아, 이 날짜는 year=2024/month=03/day=05 파티션에 있구나"라고 알아서 판단해서 필요한 폴더만 찌른다. 이 덕분에 사용자가 물리 구조를 몰라도 최적의 성능이 나온다.
2. 스키마 변경 문제
파일 하나하나가 주인이다
기존 방식은 테이블 전체를 관리하는 '중앙 집권적 명세서'가 약했다.
만약 "일(Day)" 단위 파티션을 "시간(Hour)" 단위로 바꾸고 싶다면? 기존의 모든 데이터를 새 폴더 구조로 다시 다 옮겨 적어야(Rewrite) 했다.
Iceberg 에서는 테이블 스키마를 변경하듯 파티션 정책을 바꿀 수 있다.
과거 데이터: "일" 단위 유지
새 데이터: "시간" 단위로 적재
엔진은 메타데이터를 보고 "과거는 일 단위로 찾고, 최신은 시간 단위로 찾으면 되겠군"이라며 두 구조를 동시에 처리한다. 데이터를 옮길 필요가 전혀 없다.
물리적 강제성 부족
Parquet 파일 하나하나가 자기 스키마를 가지고 있다. 만약 테이블의 특정 컬럼 이름을 바꿨는데, 과거에 쌓인 수만 개의 파일들 속에는 여전히 옛날 이름이 들어있다면? 엔진은 이를 읽다가 충돌이 나거나, 사용자가 수작업으로 모든 파일을 업데이트해야 했다.
신뢰할 수 없는 메타데이터
기존 카탈로그(Hive Metastore)는 "이 폴더에 파일이 있다" 정도만 알 뿐, 그 안의 파일들이 정말 유효한지, 쓰다가 깨진 건 아닌지 실시간으로 추적하지 못했다.
해결책 Iceberg
Iceberg는 "데이터는 폴더가 아니라 파일 단위로 관리해야 한다"는 철학을 가지고 있다.
Iceberg 철학
“ 데이터는 immutable, 해석은 metadata로 한다 ”
Hidden Partitioning (숨겨진 파티셔닝)
뒤에 설명할 Schema Evolution 의 근본이 되는 원리이다.
Iceberg 에서는 물리적으로 Partitioning을 수행 하지 않아도, 내부적으로 Hidden Partitioning을 수행 하기때문에, 파일을 Dictionary 등을 이용 하여 물리적으로 Partitioning을 수행 할 필요가 없다.
사용자가 order_date만 조회해도, Iceberg 메타데이터가 알아서 "이 날짜는 2024-03-05 파티션 파일에 있네"라고 연결해 준다. 사용자가 물리적 폴더 구조를 몰라도 최적의 성능을 내게 한다.
Schema Evolution (스키마 진화)
Iceberg 는 Schema 대한 수정이 있어도 파일을 건드리지 않고 내부적으로 메타데이터(JSON)만 수정한다.
Iceberg를 사용 하는 각 Engine (Spark, Hive 등)에서는, Metadata에 저장 되어 있는 테이블 정보(메타데이터)를 제공하고 Engine이 Iceberg의 설계 표준(Spec)에 따라
- 메타데이터를 먼저 읽고,
- 메타데이터에 적힌 내용을 바탕으로 실행 계획을 수립.
- 계획된 파일들만 골라서 스토리지로부터 해당 파일을 Read 한다.
"앞으로 user_id 컬럼은 customer_id라고 읽어라"라고 메타데이터에 적어두면, 엔진이 읽을 때 실시간으로 매핑해준다.
Snapshot 기반 관리
Snapshot 기반 관리의 핵심은 "데이터 파일의 물리적 위치를 메타데이터가 완벽하게 장악하고 있다"는 점에 있다
Iceberg는
“파일 시스템을 탐색하지 않는 대신 “메타데이터 트리”만 읽는다 "
수만 개의 파일 목록을 메타데이터 파일(Manifest)에 미리 적어두기 때문에, S3 폴더를 일일이 뒤질 필요 없이 메타데이터만 읽어서 필요한 파일 경로만 골라낸다.
S3/
└── table/
├── data/ ← 실제 Parquet 데이터 파일
├── metadata/
│ ├── v1.metadata.json ← 현재 snapshot 포인터
│ ├── snap-1.avro ← snapshot 정보
│ ├── manifest-list.avro
│ ├── manifest-1.avro
│ └── manifest-2.avro1️⃣ 시작: metadata.json 읽기
엔진 (예: Apache Spark)이 제일 먼저 하는 것:
metadata/v1.metadata.json 읽기
여기에는:
- 현재 snapshot id
- schema
- partition 정보
- manifest list 위치
위의 정보들로 “이 테이블의 최신 상태가 어디 있는지” 알려준다
2️⃣ Snapshot 찾기
snapshot-id → snap-xxx.avro 이 파일에는:
어떤 manifest list를 사용할지
3️⃣ Manifest List 읽기
manifest-list.avro역할: “어떤 manifest 파일들을 봐야 하는지 목록”
manifest-1.avro
manifest-2.avro4️⃣ Manifest 파일 읽기 (여기가 핵심)
manifest-1.avro이 안에는:
파일 경로 + 통계 정보
s3://.../data/file1.parquet
s3://.../data/file2.parquet그리고 중요한 것:
-
min/max 값
-
partition 값
-
row count
5️⃣ 파일 필터링
WHERE date = '2024-01-01'엔진이 하는 일:
manifest에서
→ date 범위 안 맞는 파일 제거 , 필요한 파일만 선택한다
6️⃣ 실제 데이터 읽기
선택된 Parquet 파일만 S3에서 읽어서 반환한다.
지금 설명한 metadata → manifest → 파일 선택 과정 안에 “Hidden Partitioning”이 자연스럽게 녹아 있다.
Hidden Partitioning =
“사용자는 파티션을 몰라도, 엔진이 알아서 파티션 기반으로 파일을 걸러준다”
