DataEngineering
1.Hadoop

Hadoop > : 데이터를 블록이라는 기본 단위로 나누어 파일의 형태로 저장할 수 있는 분산 파일시스템 Hadoop 은 먼저 단일 소프트웨어가 아니라 분산 시스템을 구성하는 다수의 소프트웨어 집합체다. Hadoop 의 구성 요소 HDFS : 데이터를 저장하는 분산
2.Hadoop - MapReduce

분산 시스템엔 많은 소프트웨어와 드라이버가 존재하기 때문에 한정되고 분산되어 있는 자원을 관리하는 관리자는 필수 YARN은 여러 분산 컴퓨팅 리소스 관리자(Resource Manager) 중 하나일 뿐 YARN YARN은 애플리케이션이 사용하는 CPU코어와 메모리를
3.Hadoop - 실습 (1)
먼저 하둡 설정 파일에 대해 알아보자 hadoop-env.sh : 하둡이 실행하는 모든 프로세스에 적용되는 시스템 환경 스크립트 core-site.xml : 하둡 파일 시스템과 하둡 맵리듀스에 모두 적용할 수 있는 스크립트 hdfs-site.xml : 하둡 분산
4.HDFS - 실습 (3)
: 분산형 구축은 여러 대의 머신을 이용하여 구축하는 방법.실제로 데이터를 분산하여 저장할 수 있고, 각 노드들은 서로 다른 머신에 동작시켜 데이터를 분산해 저장할 수 있다. 실제로 많이 사용하는 방법이다.master : NameNode 와 Jobtracker 를 동작
5.Hadoop - 장애 복구
HDFS는 기본적으로 랙 인식(Rack Awareness) 기능을 통해 데이터 복제본을 지능적으로 배치하여, 랙 전체의 장애에도 대비하고 네트워크 효율성을 높이려고 한다. 로컬 환경이나 Rack 개념이 없는 소규모 클러스터에서 HDFS를 사용한다면, HDFS는 랙 인식
6.HDFS 2.0 - YARN
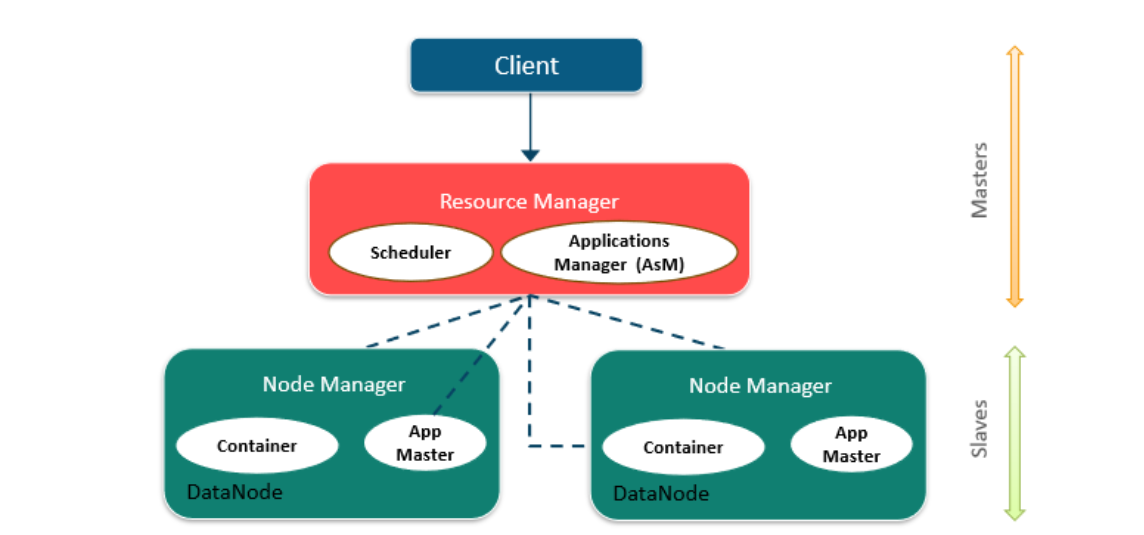
HDFS federation (연합) HDFS 연합 기능은 여러 개의 NameNode 와 NameSpace 를 독립적으로 관리할 수 있도록 도와준다. 겉으로 보기엔 완전 다른 파일 시스템처럼 작동한다는 것이다. 그러나 내부적으로는 데이터노드들이 모든 네임노드들을 위한
7.Hadoop - Client
HDFS Client File Reading JVM 기반의 Client가 NameNode에 원하는 데이터를 요청한다. NameNode는 메타데이터 안에서 해당 데이터를 담고 있는 DataNode들의 IP 주소(위치 정보)를 전달한다. 분산 네트워크의 코어 스위치(c
8.Spark - (1) Spark 개념
Spark 란? Apache Spark 는 데이터 센터나 클라우드에서 대규모 분산 데이터 처리를 하기 위해 설계된 통합형 엔진 속도 스파크는 질의 연산을 DAG로 구성 , 각각의 태스크로 분해 , 클러스터의 워커 노드위에서 병렬 수행된다. +모든 중간 결과는 메
9.Spark - (2) RDD
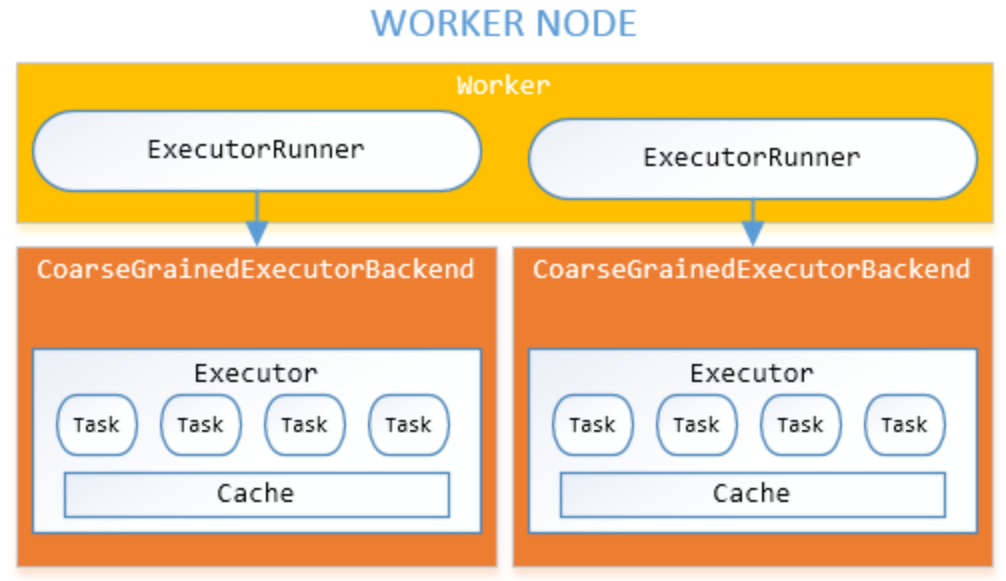
Spark RDD > Resilient Distributed Dataset Spark 의 가장 근본적인 Data 처리 방식이다. RDD API Immutable (불변성) Spark RDD 는 불변성을 가진다. 그 이유는 RDD 자체가 Read-Only 인 데이
10.Spark - (3) Dataset, DataFrame
특정한 타입(T)을 가진 JVM 객체들의 분산 컬렉션 (Distributed, Typed Collection). 타입을 가진 RDD + DataFrame의 최적화 기능을 결합한 APIDatasetPerson = Person 객체들의 분산된 컬렉션Dataset은 컴파일
11.Engine (엔진) 이란?
⭐ 결론: ‘엔진’ = 어떤 입력을 받아서, 일정한 규칙에 따라 실제 작업을 수행하는 핵심 실행 모듈(Execution Core) “엔진”이라는 단어는 어떤 시스템의 중심에서 실제 행동을 수행하는 실행기(executor)를 의미하는데 , 어디에서(어떤 객체) 수행되고
12.Data LakeHouse
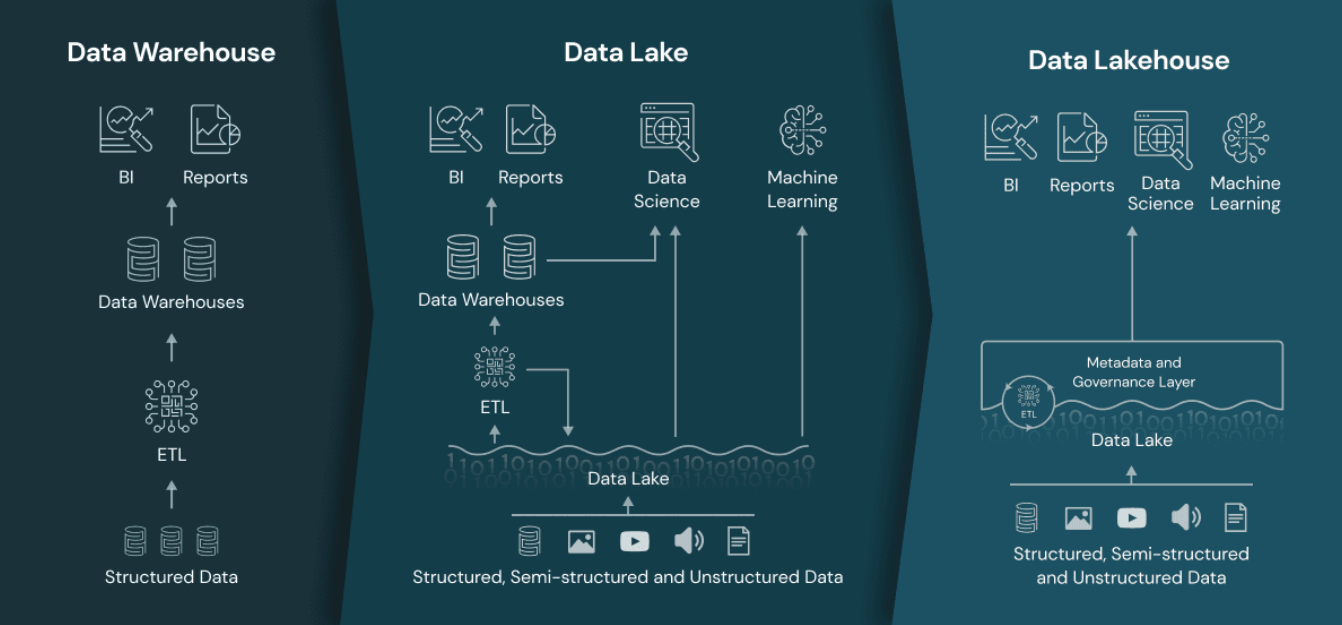
Data Warehouse란?기업에서 운영되는 여러 시스템(DB)에서 데이터를 모아분석 전용 저장소에 넣고 BI/리포트/결정 지원을 위해 사용하는 플랫폼.초기 1세대 데이터 분석 플랫폼은 데이터 웨어하우스다.OLTP 시스템에서 데이터를 모아 DW 에 저장했다.이렇게 모
13.HTAP
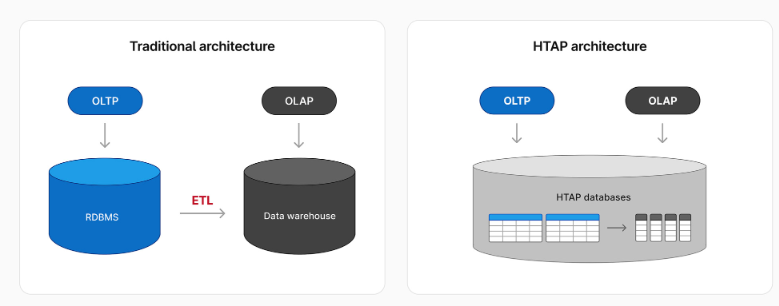
HTAP(Hybrid Transactional/Analytical Processing)는 하나의 데이터베이스 시스템에서 트랜잭션 처리(OLTP)와 데이터 분석(OLAP)을 동시에 수행하는 아키텍처를 의미한다.기존에는 OLTP 와 OLAP 를 나누어 사용했었다. OLTP
14.CQRS 아키텍쳐
우리는 일반적으로 DB 구조를 읽기(DB Read)와 쓰기(DB Write)를 단순히 분리하는 수준에서 그친다 Command ( = Transaction ) 시스템 데이터 변경하는 기능 ex) 주문 취소, 배송완료 쿼리 ( = Query ) ( SQL Query 아님 ) 시스템 데이터를 조회하는 기능 쿼리는 시스템의 상태를 단지 반환하기만 하고 상태...
15.CQRS - Apache Druid

CQRS 의 아키텍쳐로써 Druid를 사용해보자.https://toss.tech/article/payments-legacy-7토스 기술블로그를 참고하였습니다.1️⃣ 넓은 기간 조회 — 몇 개월, 혹은 몇 년치 데이터를 한 번에 보는 것.2️⃣ 특정 조건 검색
16.분산 시스템 - Zookeeper

데이터 엔지니어링 분야를 이것저것 공부하다보면 ( Hadoop, spark, kafka ...) 계속 나오는 Zookeeper 라는 것이 있다. 뭔진 모르는데 계속 나오니 그런가보다 하는게 있었는데 이번 기회에 정리해보자 Zookeeper 란? > Zookeeper
17.Parquet 저장방식

데이터를 저장하는 방식 중 하나로 하둡생태계에서 압축과 컬럼 기반 데이터 표현의 이점을 만들기 위해 개발한 파일 포맷이다. 공식문서에는 다음과 같이 나와있다.언어를 가리지 않습니다.컬럼 기반 형식 - 파일이 행이 아니라 열로 구성되어, 스토리지 공간이 절약되고 분석 쿼
18.Apache Iceberg
최근 데이터의 양과 다양성이 급격히 증가하면서, 효율적인 데이터 파이프라인 구축의 중요성이 그 어느 때보다 커졌다. 특히, 실시간 데이터 조회와 수정, 운영 비용 절감, 스키마 진화의 간소화, 쿼리 성능 최적화와 같은 도전 과제들이 주요 이슈로 떠오르고 있다. 이미 데이터 레이크하우스에서 핵심 구성 요소로 Apache Iceberg를 사용하는 중이다. ...
19.Parquet 저장방식 #2
Parquet 파일은 binary columnar format row group 단위 압축 파일 일부만 수정 불가 수정시 파일 전체 rewrite 한다 > row 1개 바뀌어도 parquet 파일 전체 다시 써야 함 > ❗ “사람이 직접 보고 의사결정” 단계라