Query Processing이란?
DB 에서 Data 를 추출하는 모든 활동의 범위를 의미.
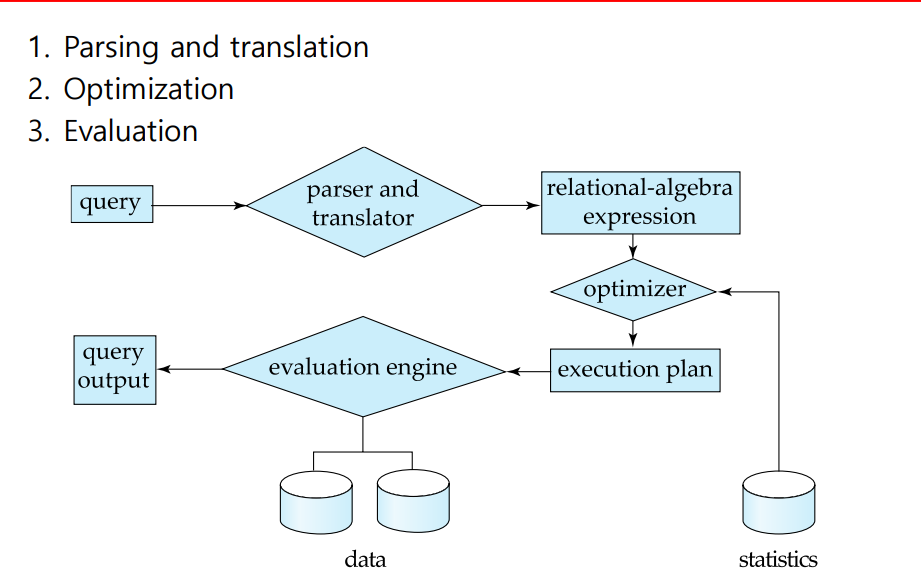
쿼리 → 구문 트리 → 관계 대수 → 실행 계획 → 실행
주요 단계:
- Parsing & Translation (구문 분석 및 변환)
- Parser 가 SQL 쿼리를 내부 형식으로 변환
- Translator 가 SQL 을 Relational Algebra(관계 대수)로 변환
- 구문 검사 및 릴레이션 확인
- Optimization (최적화)
- Optimizer 가 Execution plan(이론에서는 Evaluation plan)을 계획
- 동일한 결과를 내는 여러 실행 계획 중 최저 비용의 계획 선택
- Database Catalog의 통계 정보를 활용 (튜플 수, 블록 수 등)
- Evaluation (실행)
- Query Execution Engine (Executor) 이 실행 계획을 연산 수행
전통적인 SQL 기반 RDBMS들은 모두 Parser–Translator–Optimizer 구조를 명확히 갖고 있다.
Query Cost 측정
DBMS 성능의 70~90%을 차지할정도로 중요하다. SSD에서는 디스크 접근 비용(Disk Access Cost)의 계산 방식이 전통적인 HDD 방식과 다르다. 그러나 이 글에서는 전통적 하드디스크를 접근 기준으로 한다. 최근 AI 시대에는 또 HDD가 대용량을 저장할 수 있어 각광받고 있다고도 한다.
비용 측정 기준
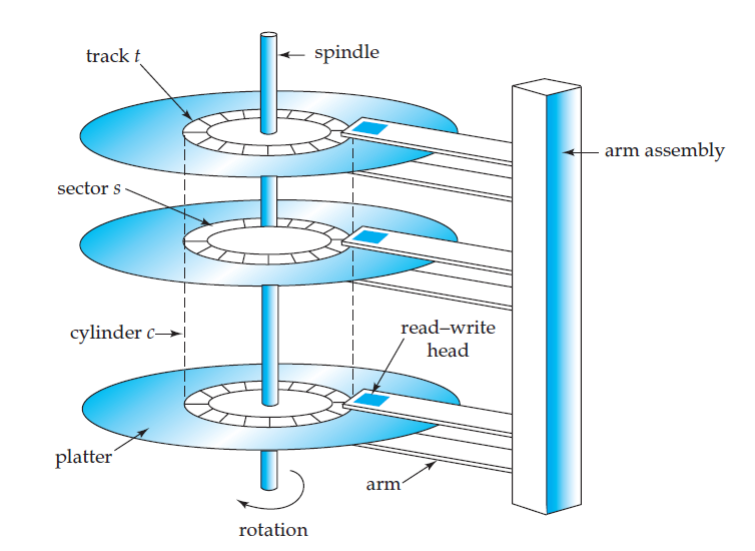
디스크 접근(Disk Access)이 가장 중요한 비용 요소를 알아내기 위해선 디스크의 구조
디스크(HDD 기준)는 기계적으로 다음 순서로 동작한다
Seek (탐색)
👉 액추에이터 암이 현재 트랙에서 목표 트랙으로 이동하는 데 걸리는 시간. 이는 가장 큰 비용 요소 중 하나이며, 여러 플래터에 걸쳐 있는 데이터에 접근할 때도 전체 암의 움직임으로 모델링
Rotational Latency (회전 지연)
👉: 플래터가 회전하여 목표 섹터가 헤드 아래로 올 때까지 기다리는 시간
→ (보통 평균 1/2회전 시간, 약 3~5ms)
Transfer (전송)
👉 실제로 디스크에서 RAM 으로 데이터를 읽거나 쓰는 데 걸리는 시간
→ 실제 데이터가 물리적으로 흘러 들어오는 시간 (~0.1~0.5ms)
HDD (Hard Disk Drive)**의 플래터(platter) 간의 이동 시간 비용은 일반적으로 직접적으로 고려되지 않거나, 다른 비용 항목에 포함되어 추정된다.
I/O cost = (탐색 횟수 × seek_time) + (블록 개수 × transfer_time)
Seek은 “위치 찾는 데 걸리는 고정비용” -> 최소 한번은 존재
,
Transfer는 “데이터량에 비례하는 가변비용” -> 오래 걸릴수도 , 안 걸릴 수도 있음
Selection Operation
관계대수 6가지 연산의 Query Cost 특징을 알아보자
1. Linear Search
모든 플래터의 표면을 순차적으로 활용하며 데이터를 읽는 방법
특징 : Index 를 사용 X
1-1. 일반 Linear Search ( Key 값 사용 X )
Ex) salary > 50000 이런 식으로 모든 레코드를 검사해야 하는 경우
Cost : Ts + ( Br x Tt )
= 한번의 Seek + 레코드 개수 만큼의 블록 * 읽어들이는 시간
1-2. 특수 Linear Search ( Key 값 사용 O )
Ex) WHERE id = 12345 이 경우 하나의 튜플만 찾으면 탐색을 중단할 수 있다.
Cost : Ts + ( Br / 2 x Tt )
= 한번의 Seek + 레코드 절반 개수 만큼의 블록 * 읽어들이는 시간
Br / 2 값은 최선 , 평균 , 최악의 시간을 모두 고려한 평균 시간(Mean Time)이다.
2. Index Scan
Index에는 두 종류가 있다.
Primary Index ( = Clustering Index ) : 파일 안에서 레코드가 순서대로 읽힐수 있도록 하는 Index (표시)
Secondary Index : Primary Index 가 아닌 Index.
특징 : Index 를 반드시 사용한다.
2-1. Dense Index
정의: Dense Index 는 데이터 파일의 모든 검색 Key 값에 대해 Index 항목(Index Entry) <키-밸류> 쌍을 생성한다.
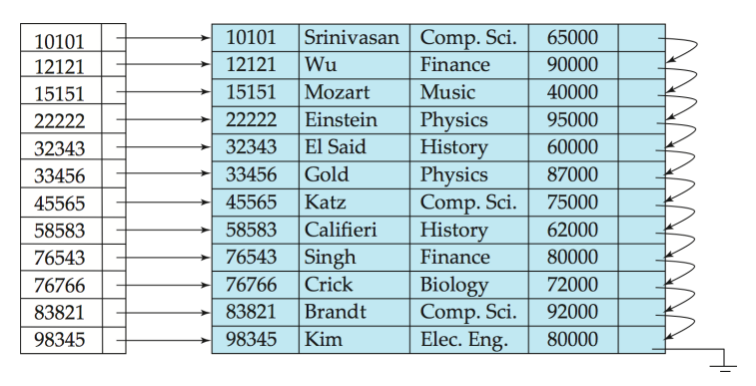
모든이 중요. 모든 엔티티가 Index를 가짐 - Index 크기 큼
Key : Index -> Value : 해당 키 값을 가진 실제 레코드 데이터의 포인터 (값 X)
2-2. Sparse Index
정의: Sparse Index는 데이터 파일의 일부 검색 키 값(일반적으로 데이터 블록당 하나, 블록의 첫 번째 레코드)에 대해서만 Index 항목을 생성.
특징 :
- 데이터 정렬 : 데이터 파일은 인덱스 키 순서대로 물리적으로 정렬되어 있어야 함. (Clustering Index 에 주로 사용).
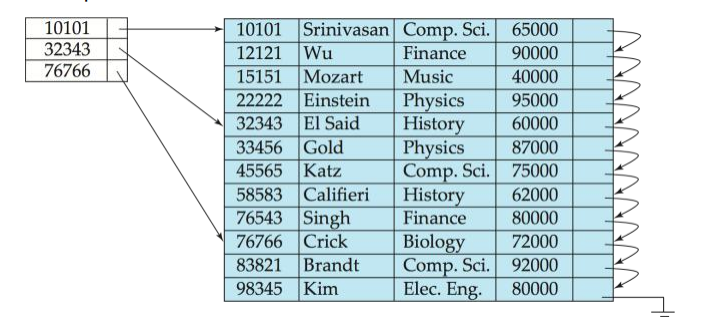
일부 엔티티가 Index를 가짐 - Index 크기 작음
2-3. Secondary Index
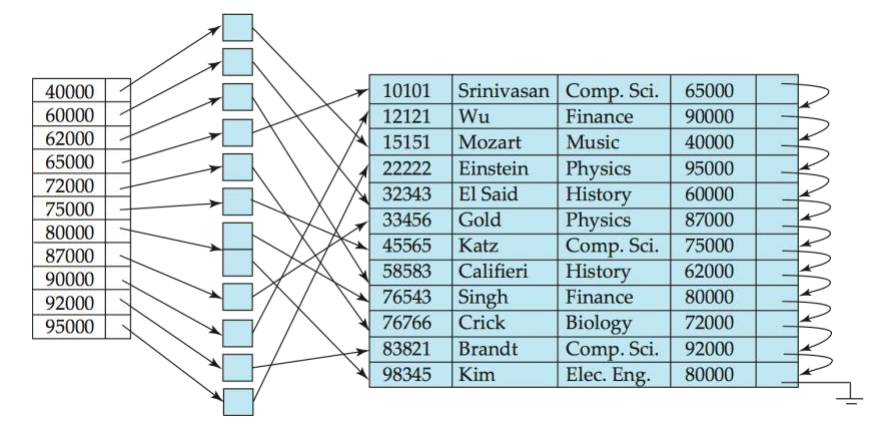
특징
-
Dense Index 형태: 보조 인덱스는 모든 레코드를 가리키며, 하나의 키 값에 여러 레코드가 대응될 수 있습니다.
-
데이터 비정렬: 레코드는 인덱스 키 순서가 아닌 물리적 위치에 저장
주 인덱스(Primary Index)와는 다른 특징 때문에 비용 계산 방식과 최종 비용에 차이가 있다.
3. B+-Tree Index
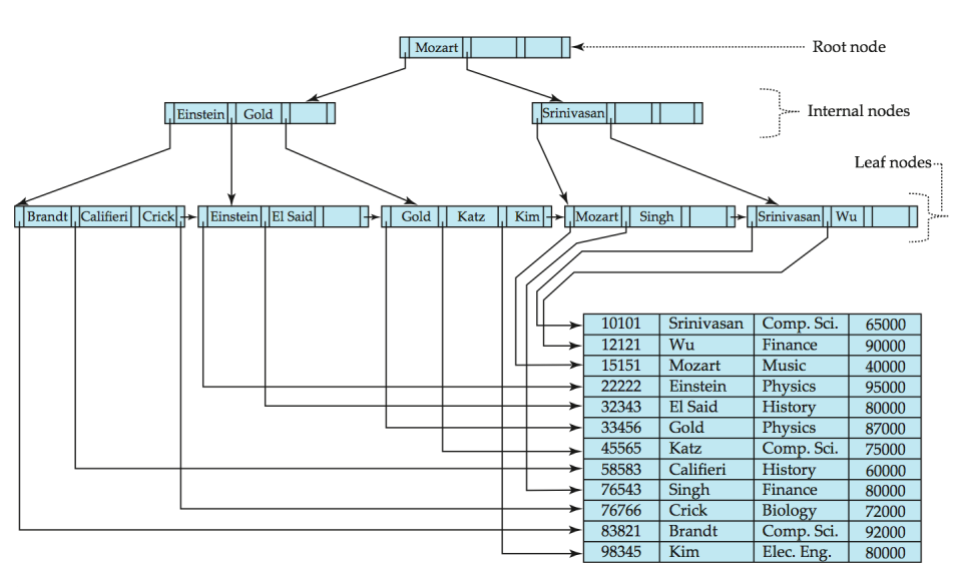
정의 :
특징 :
-
효율적 : 블록 기반 저장 장치(Block-oriented Storage)**에서 효율적으로 관리하고 검색하기 위해 설계된 자료구조
-
균형 트리 : 루트(Root)에서 모든 리프(Leaf) 노드까지의 높이(Height)가 항상 같도록 유지됩니다. 이는 최악의 경우(Worst-case)에도 일정한 검색 성능(일정 횟수의 디스크 I/O)을 보장
-
Primary B+- Tree Index 는 데이터 정렬 O, Secondary B+-tree 는 데이터 정렬 X
3-1. Primary B+-Tree Index (정렬 O , Key 값 사용 O )
여기서 h 만큼 I/O cost 하고, 거기서 실제 레코드(Primary)를 1개 찾고(Key는 1개의 값만 가진다) 그 레코드를 읽고 I/O Cost가 나온다.

3-2. Primary B+-Tree Index (정렬 O , Key 값 사용 X )
여기서 h 만큼 I/O cost 하고, 거기서 실제 레코드를 찾고(Primary) 그 레코드를 찾기 위해 읽어들인 블록개수 b만큼 I/O Cost가 나온다.
3-3. Secondary B+-tree Index (정렬 X , Key 값 사용 O )
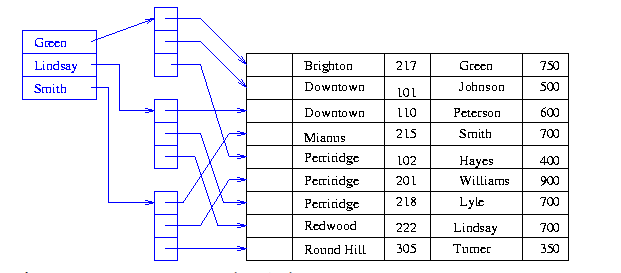
루트부터 타고 내려오면서 리프 노드에서 개(Key는 1개의 값만 가진다)의 레코드 주소(포인터)를 얻는다. 그 포인터의 I/O Cost 발생
3-4. Secondary B+-tree Index (정렬 X , Key 값 사용 X )
루트부터 타고 내려오면서 리프 노드에서 개의 레코드 주소(포인터)를 얻는다.
개의 레코드 각각이 다른 블록에 있어 번의 탐색 ()이 필요함.
Cost ≈ Cost=(h + n) × (tT + tS)
인덱스 탐색 (h): 트리의 높이 h
조건을 만족하는 n개의 레코드