앞 글에서 정규화의 정의 와 예시에 대해 알아보았다. 데이터베이스 정규화란 현재 테이블에서 데이터 중복과 의존성을 줄이기 위한 데이터베이스를 최적화하는 작업이다. Relation을 분해하며 중복은 줄어들고 의존성은 최소화된다.
분해에 대한 조건이 있다. 분해 후, join 했을 때 이전 정보가 소멸되면 안 된다는 점이다. 관계에 대한 조인 을 수행했을 때, 이전 값과 똑같아야 한다는 것이다.
정보 손실(Information Loss)
Decomposition (분해) 과정에서 정보 손실(Information Loss)이 발생하는 주된 이유는, 분해된 구성 요소를 다시 합쳤을 때(Join) 원래의 정보 상태를 완벽하게 복원하지 못하기 때문이다.
데이터베이스에서의 손실 조인 분해 (Lossy Join Decomposition)
데이터베이스에서 릴레이션 R을 R1,R2,… 와 같은 여러 개의 작은 릴레이션으로 분해하는 과정에서 손실이 발생하는 이유는
- 외래 튜플(Extraneous Tuples)의 생성
현상: 분해된 릴레이션 R1,R2,…를 자연 조인(Natural Join) 연산을 사용하여 원래의 릴레이션으로 복원하려고 할 때, 원래 R에는 존재하지 않던 새로운 튜플(행)이 생성될 수 있다.
정보 손실의 의미: 이 외래 튜플의 존재는 존재는 잘못된 정보(Loss)를 의미하며, 원래 데이터의 식별을 어렵게 하거나 무결성을 해치는 원인이 된다. 이는 '정보의 손실'로 간주되는데, 비록 데이터가 사라지지는 않았더라도, 원래의 정확한 정보 상태를 복원할 수 없기 때문이다.
예시: 학생-과목-교수 정보가 담긴 테이블을 분해했다가 다시 합쳤을 때, 존재하지 않던 '특정 학생이 듣지 않은 특정 교수의 강의' 튜플이 생성되는 경우.
Lossless Decomposition
복원 조건 불충족
분해가 무손실 조인 분해(Lossless Join Decomposition)가 되기 위한 조건을 충족시키지 못했기 때문에 손실이 발생한다. 무손실 분해가 되려면 다음과 같은 핵심 조건 중 하나를 만족해야 한다 (릴레이션 R을 R1과 R2로 분해하는 경우):
분해된 릴레이션들의 공통 속성(Intersection): R1 ∩ R2의 공통 속성이 둘 중 하나의 슈퍼키(Superkey)가 되어야 한다.
R1 ∩ R2 -> R1 또는 R2 의 SuperKey이 조건을 만족하지 못하면, 조인 시 정보의 정확한 연결 고리가 부족하여 외래 튜플이 생성되고 Loss Decomposition 이 된다.
Dependancy Preservation
의존성 보존
목표: 릴레이션 R에 정의된 모든 함수 종속성(Functional Dependencies, FD)이 분해된 릴레이션들 R1,R2 ,… 중 어딘가에서 검사 가능하도록 보장하는 것.
의미: 원래 릴레이션 R의 모든 제약 조건(FD)을 확인하기 위해 분해된 테이블 전체를 조인할 필요 없이, 분해된 개별 테이블 내에서 또는 두 개의 테이블 내에서 직접 종속성을 검사할 수 있도록 합니다.
보장하는 것:
- 데이터 삽입, 삭제, 수정후 전체 테이블을 조인하여 확인하는 절차 생략 가능(비용, 성능적 측면).

폐포(closure) : 특정 속성 집합 𝑋 -> X가 F로부터 유도할 수 있는 모든 속성의 집합 (1번 글에도 있음)
예시 1) R에 A→C 라는 종속성이 있고, 와 로 분해된 경우, A→C는 R1과 R2에 의해 직접 검사될 수 없다. (폐포를 통해 닿을수 없음. 조인이 필요). 이 경우 의존성이 보존되지 않은 것이다.
예시 2)
릴레이션 R: R(학생번호,과목번호,성적,과목명)
함수 종속성 F:
- F1:학생번호,과목번호→성적
- F2:과목번호→과목명 (이행 종속성 제거 필요)
✂️ 분해 (3차 정규형 분해)
F2인 의 종속성 위반을 해결하기 위해 다음과 같이 분해.
- Ra : (학생번호,과목번호,성적)
- Rb : (과목번호,과목명)
의존성 보존 검사
분해된 릴레이션에 남아있는 함수 종속성을 확인하면 된다.
Ra에서 학생번호,과목번호→성적 검사
Ra는 (학생번호,과목번호,성적) 속성을 모두 가지고 있다.
따라서 원래의 종속성 F1을 Ra 내에서 직접 검사할 수 있다. = 폐포와 동등 = 의존성 보존
Rb에서 과목번호→과목명 검사 Rb는 (과목번호,과목명) 속성을 모두 가지고 있습니다.
따라서 원래의 종속성 F2를 Rb 내에서 직접 검사할 수 있다. = 폐포와 동등 = 의존성 보존
3NF 와 BCNF 의 관계
3NF : 이행 종속성을 제거 (비-키 속성에 한정)
① 학생 테이블 (PK → 나머지 속성)
| 학번 | 이름 | 학과 |
|---|---|---|
| S1 | 김철수 | 컴퓨터 |
| S2 | 이영희 | 수학 |
| S3 | 박민수 | 컴퓨터 |
- 일부 데이터는 중복성을 가짐
② 학과 테이블 (학과 → 학과장)
| 학과 | 학과장 |
|---|---|
| 컴퓨터 | 홍길동 |
| 수학 | 이순신 |
BCNF : 모든 결정자가 후보 키가 되도록 보장
1) BCNF 여부 점검(원본 통합 테이블)
다음과 같은 제약사항이 있다고 생각해보자.
- 한 학생은 동일 과목에 대해 하나의 교수에게만 수강 가능
- 각 교수는 하나의 과목만 담당할 수 있다.
- 한 과목은 여러 교수가 담당 가능하다.
BCNF 조건: 모든 R의 비자명 FD X→Y에서 X가 슈퍼키여야 함.
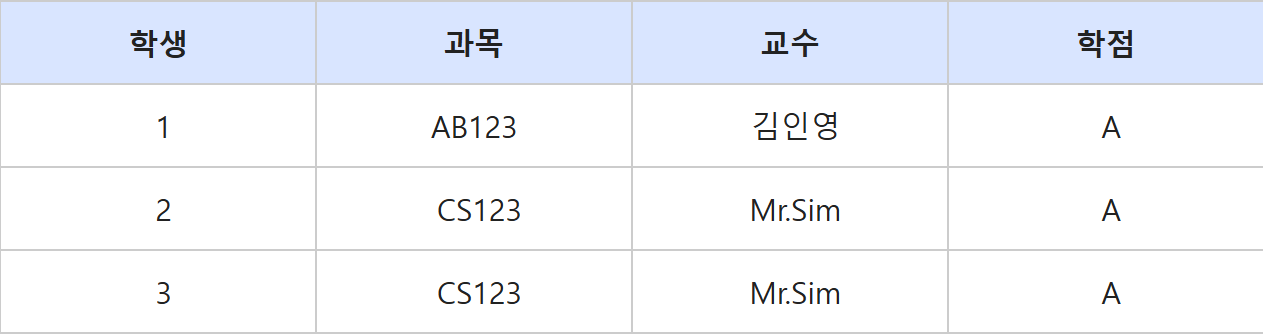
학번, 과목 -> 학점
이 상황에서 다음과 같이 BCNF를 만족하는 구조로 변경할 수 있다.
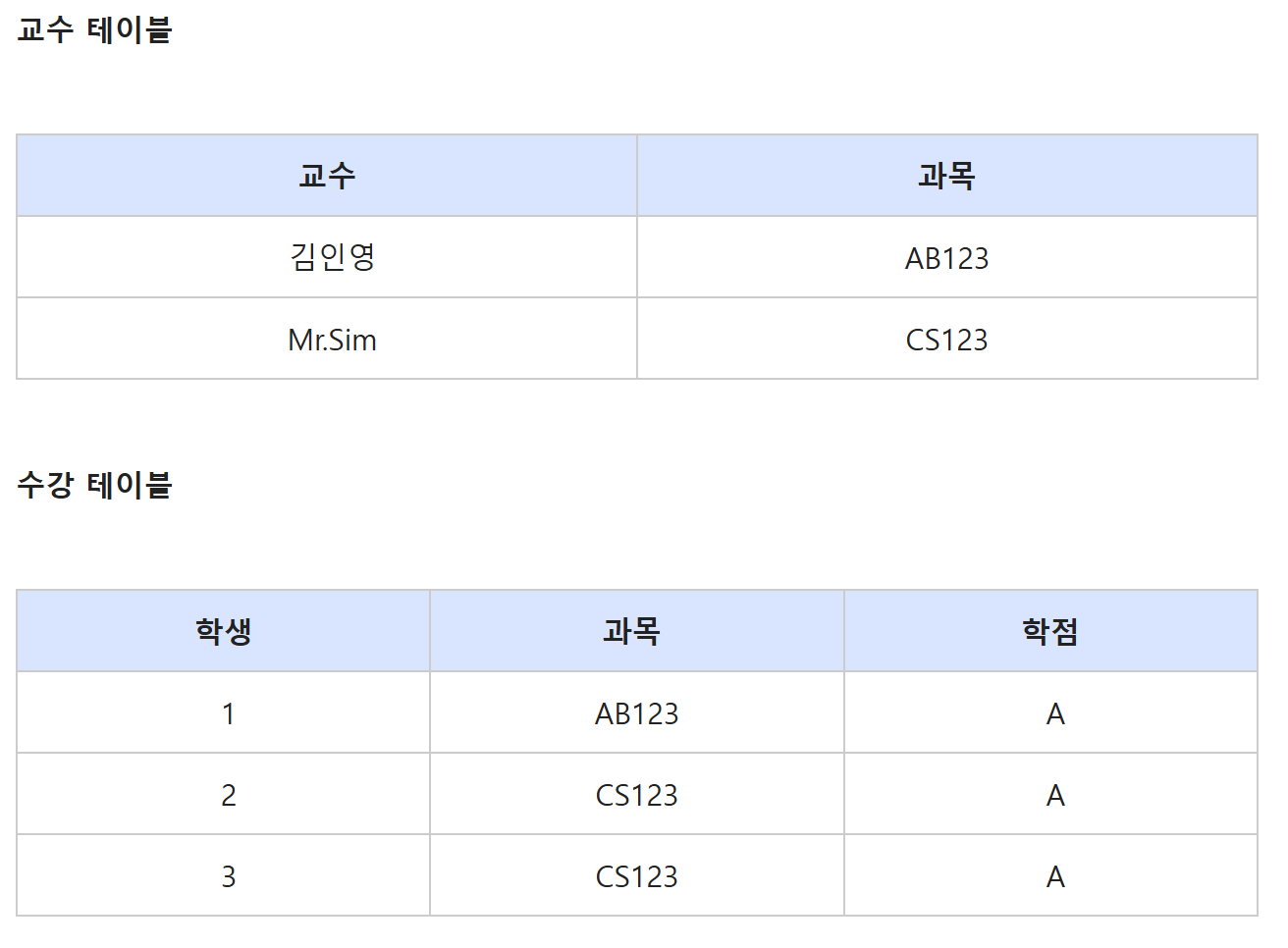
R1 : 교수 -> 과목
R2 : (학생 , 과목) -> 학점
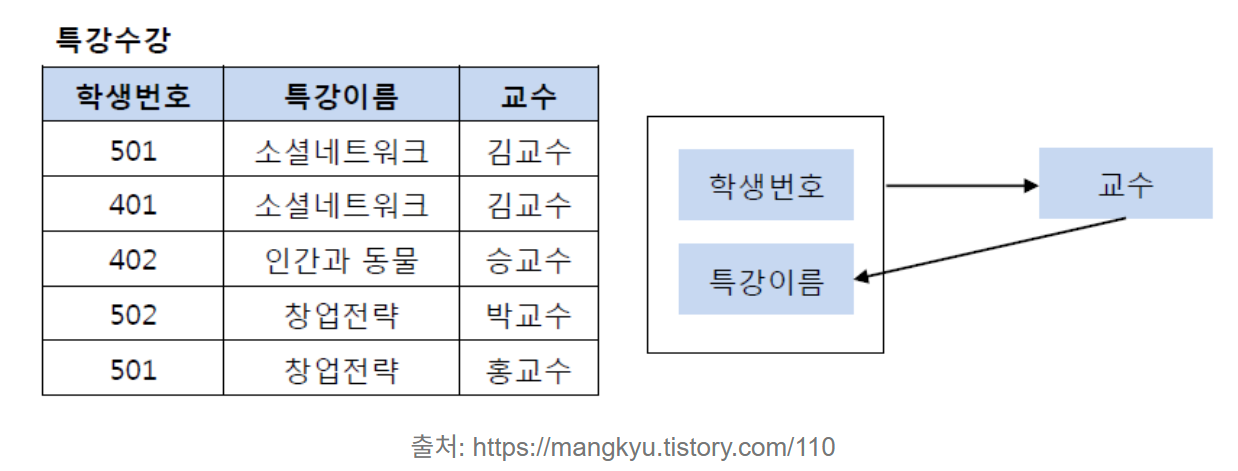
위의 테이블에서 기본키는 (학생번호, 특강이름)이다.
학생 번호, 특강 이름은 교수를 결정한다.
그러나 교수는 특강 이름을 결정한다. 특강 이름을 결정하는 결정자 이지만 유일성을 만족하지 못하기에, 후보키가 될 수 없다. 이 때문에 테이블을 분해하여, 교수 컬럼이 후보키가 될 수 있도록 해줘야 한다.
학생번호 , 특강이름 -> 교수 , 교수 -> 특강이름 => 이행종속성도 위반
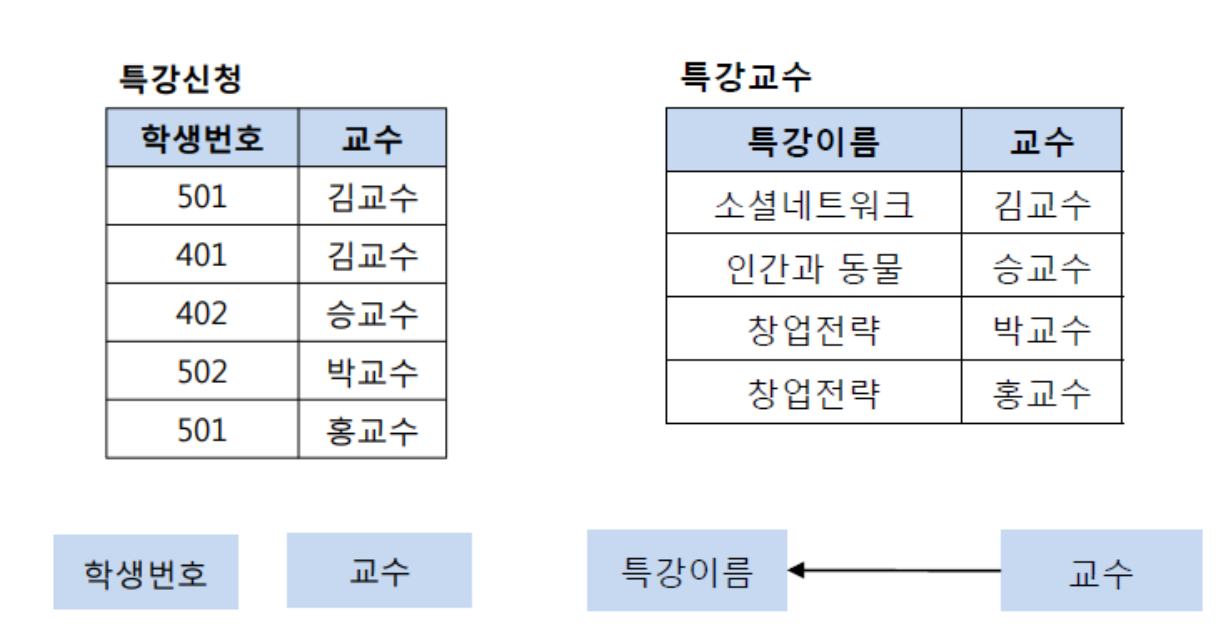
R1 : 학생번호->(담당)교수 , R2 : (특강이름, 교수) -> 특강이름 X→Y가 자명
3차 정규형 (3NF): 3NF로 분해하면 항상 무손실 분해와 의존성 보존을 모두 만족한다. 3NF 는 약간의 중복이 남아있을 수 있다.
보이스-코드 정규형 (BCNF): 3NF보다 더 엄격한 정규형, 중복성을 최소화하는 데 가장 효과적. BCNF로 분해하면 항상 무손실 분해는 보장되지만, 의존성 보존은 만족하지 못할 수도 있다.
정규화 과정에서 릴레이션을 분해할 때, 이 두 가지 목표는 서로 배타적일 수 있습니다. 즉, 하나의 목표를 달성하면 다른 목표를 희생해야 하는 경우가 생긴다. 분해 후 테이블들에서는 3NF만 만족해도 3NF도 만족하고, 설계에 따라 BCNF까지 만족하는 경우도 생긴다.
정규화가 너무 많이 진행되면 엔터티가 늘어나 조회시 성능이 하락하므로 적절한 수준의 정규화 수준을 맞춰 진행해야한다.
데이터베이스 분야에서는 함수 종속성(Functional Dependency, FD) 외에도 다양한 종류의 의존성(Dependency)이 존재하기 때문에(다치 종속성, 조인 종속성등), FD 보존이라고 한정하지 않고 더 포괄적인 용어인 의존성 보존(Dependency Preservation)을 사용한다.
