데이터베이스 정규화
-
목표: 중복을 최소화하고 삽입, 삭제, 갱신 이상을 방지하는 스키마 설계
-
핵심 수단: 함수적 종속성(Functional Dependancu), 무손실 분해(lossless-join), 의존성 보존(dependency preservation), 정규형(1NF, 3NF, BCNF)
1. 제 1정규형 (1NF)
- 모든 Attribute 의 도메인이 Atomic 이어야 함
- 집합, 복합 속성, 분해 가능한 식별자는 비원자적이므로 분리
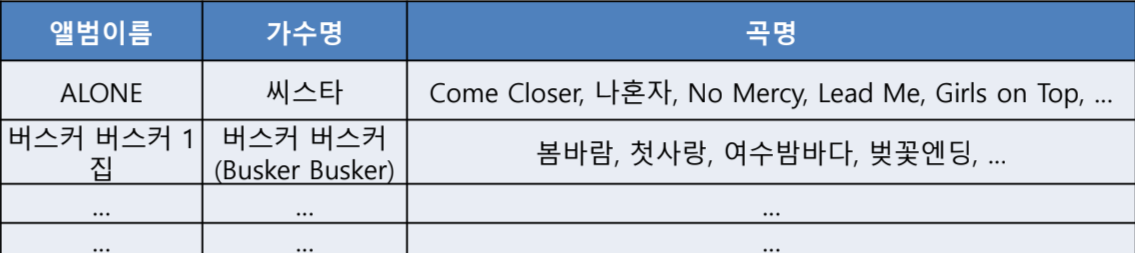
EX) 한 가수에 하나의 곡명만 가지도록 써야한다
2. 제 2정규형 (2NF)
- Primary Key 가 2개 이상의 속성으로 이루어진 경우, 부분 함수 종속성을 제거(분해)한다. Primary Key x가 하나의 컬럼으로 이루어진다면 제 2정규화는 생략한다.
3. 함수적 종속성(FD)과 Key
함수적 종속성의 정의
α → β: α 값이 같으면 β 값도 같아야 함
α 가 정해지면 반드시 β 도 정해진다 ( α 가 함수적으로 β 를 정의)
-
**EX) 학번을 알면 학생이름이 정해짐 , 주민번호 → 이름
-
SuperKey K : K → R을 만족
3-1. SuperKey
Relation R의 모든 튜플을 유일하게 식별할 수 있는 Attribute (또는 속성 집합)이에요.
즉, 어떤 두 행도 이 속성값이 같을 수 없는 속성 집합.
3-2. CandidateKey
SuperKey 중 최소로 이루어진 집합
4. 제 3정규형 (3NF)
4-1. 제 3 정규형 정의
모든 FD : X → Y에 대해,
① X가 SuperKey이거나,
② Y가 Candidiate Key에 속한 속성(프라임 속성, prime attribute)
③ X → Y 가 자명 (𝑌 ⊆ 𝑋 )
프라임 속성 → 후보키(Candidate Key)에 속하는 속성
세 조건은 한번에 이루어지지 않는 경우가 대부분이니 셋 중 하나만 만족시키면 된다.
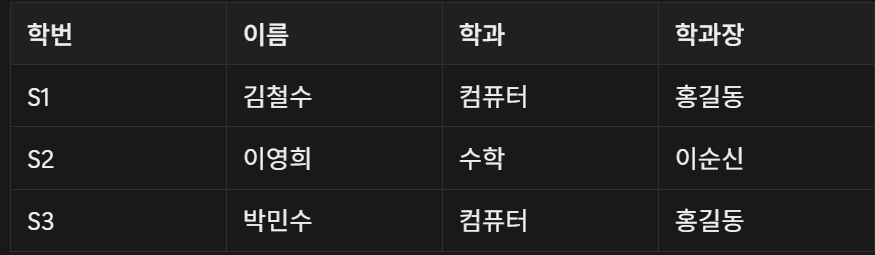
위와 같은 데이터베이스가 있다고 하자. 제 2정규화를 끝냈으니 PK는 하나만 존재(학번)
4-2. 현재 함수 종속성(FD) 파악
- 학번 → 이름, 학과
- 학과 → 학과장
위와 같이 형성됨을 알 수 있다.
(학번)이 PK 인데 학과 → 학과장 FD는 PK 를 거치지 않고 다른 Attr을 결정한다. 이는 정의 ② 에 위배된다.
이를 이행적 종속(Transitive Dependency) 이라고 한다고 한다.
3NF는 바로 이행종속성을 제거해야 정의가 충족된다.
4-3. 이행적 종속 VS 직접 함수 종속
여기까지 술술 읽혔다면 뭔가 생각이 들어야한다. 학번 → 이름, 학과 여기까진 맞는 말. 그런데 학번을 알면 학과장도 알 수 있는것 아닌가? 학번 -> 학과장 과 학과 -> 학과장의 차이
중요한건 직접 결정 유무의 차이
두 관계를 조합하면 학번 -> 학과장도 맞는 말이지만 직접적인 종속이 아니다.
이것이 이행 종속. 이행 종속이 있으면 다음과 같은 이상이 생긴다:
갱신 이상: 학과장이 바뀌면 학번이 같은 행마다 다 바꿔줘야 함.
삭제 이상: 학생이 없어지면 학과장 정보도 함께 사라짐.
삽입 이상: 학과장 정보만 추가하고 싶어도 학생이 없으면 못 넣음.
4-4. 이행종속성 제거
Non-PK 속성(PK가 아닌 속성)은 PK에 직접 함수 종속돼야 한다.
(중간 단계를 거치는 이행 종속이 있으면 3NF 위반)
R1 학생(학번, 이름, 학과) — 기본키: 학번
R2 학과정보(학과, 학과장) — 기본키: 학과
학번이라는 PK로 직접 결정이 되지않은 '학과장' 속성을 분해하여 두개의 Relation으로 만들면 해결된다.
① 학생 테이블 (PK → 나머지 속성)
| 학번 | 이름 | 학과 |
|---|---|---|
| S1 | 김철수 | 컴퓨터 |
| S2 | 이영희 | 수학 |
| S3 | 박민수 | 컴퓨터 |
② 학과 테이블 (학과 → 학과장)
| 학과 | 학과장 |
|---|---|
| 컴퓨터 | 홍길동 |
| 수학 | 이순신 |
학번 -> 이름 학과 , 학과 -> 학과장 | 각 R 에 대한 SuperKey가 만들어짐
각 결정자가 SuperKey 이므로 정의 ① 을 만족 각 Relation 이 3NF 만족.
5. 직접 vs 간접(이행) 결정의 유무의 구분
5-1) 의미(업무 규칙)로 판단
학과장은 학과의 속성(학과가 바뀌면 학과장이 바뀜).
학번은 학생의 식별자(학생이 전과하면 학과장이 바뀌어버림).
→ 학과장은 “학생(=학번)”이 아니라 “학과”가 결정자인 속성.
즉, 학과 → 학과장이 직접 종속, 학번 → 학과장은 학번 → 학과 → 학과장으로 이행 종속.
5-2) 폐포(closure)로 판정
폐포(closure) : 특정 속성 집합 𝑋 -> X가 F로부터 유도할 수 있는 모든 속성의 집합
주어진 FD 계산 : F = { 학번 → 이름, 학과, 학과 → 학과장 }
학번의 폐포 A⁺를 계산:
시작: A⁺ = {학번}
A+에 적용 가능한 FD 적용 : 학번 → 이름, 학과 → A⁺ = {학번, 이름, 학과}
다시 F 적용: 학과 → 학과장 → A⁺ = {학번, 이름, 학과, 학과장}
⇒ 결론: F ≠ 학번 → 학과장
하지만 이건 직접 FD가 아니라 학과를 거쳐 유도된 FD.
정규화 규칙(3NF)은 “비-프라임 속성(여기선 학과장)이 PK(학번)에 직접 종속”되어야 한다고 요구하므로 분해 대상이 된다.
5-3) 캐노니컬 커버(Fc)
데이터베이스 정규화에서 FD(함수 종속성)를 최소한의 형태로 정리하는 절차
주어진 함수 종속성 집합 F와 논리적으로 동등한(equivalent) 가장 간결한 집합
✅ 중복 FD가 없고 ✅ 불필요한 속성이 없고 ✅ 더 이상 줄일 수 없는 최소 함수 종속성 집합✅ Step 1: 우변(RHS) 단일화
학번 → 이름, 학과 👉 학번 → 이름 , 학번 → 학과
학과 -> 학과장
✅ Step 2: 중복 FD 제거
✅ Step 3: 유도 가능한 FD 제거
학번 → 학과 , 학번 → 이름 , 학과 → 학과장 , 학번 → 학과장 ❌ (앞의 두 개로부터 유도되므로 삭제)
✅ Step 4: 좌변(LHS) 최소화
최종 Canonical Cover: Fc = { 학번 → 이름, 학번 → 학과, 학과 → 학과장 }
지금 Fc 에 들어있는 세 개의 FD를 보면 다 직접적인 함수 종속성를 가지고 이는 정규화의 기준점이 된다.
| 사용처 | 설명 |
|---|---|
| 정규화 | 테이블을 분해할 때 어떤 속성을 기준으로 나눌지 명확해진다 |
| 후보키 탐색 | 폐포 계산 시 불필요한 FD가 없어 연산이 단순해진다 |
| 의존성 보존 검사 | 유지해야 할 핵심 FD가 명확해진다 |
| 무손실 조인 검사 | 릴레이션을 나눠도 정보가 손실되지 않는지 쉽게 확인 가능 |
6. Boyce-Codd 정규화 (BCNF)
6-1. BCNF 의 정의
Relation 𝑅 이
F+ (주어진 함수 종속성의 폐포)에 속하는 모든 비자명 함수 종속성 α→β에 대해
① α가 슈퍼키(superkey) 이거나,
② β⊆α (자명한 종속성)여야 한다.
-> 결정자(왼쪽) α가 항상 슈퍼키이면 BCNF
-> SuperKey 가 아닌 속성이 다른 속성을 “결정”하는 순간 → BCNF 위반
6-2. BCNF 예시
| 학생번호 | 과목 | 담당교수 |
|---|---|---|
| S1 | DB | 홍길동 |
| S1 | OS | 이순신 |
| S2 | DB | 홍길동 |
| S3 | AI | 강감찬 |
함수 종속성 파악
-
(학생번호, 과목) → 담당교수 ✅ (기본키 → 다른 속성)
-
과목 → 담당교수 ❌ (FD는 맞지만 과목이 슈퍼키가 아님 → BCNF 위반)
6-3. BCNF 분해
BCNF 위반 FD : (과목 → 담당교수)
→ 결정자(과목)가 SuperKey 가 아니므로 분해한다.
✅ 분해 후 릴레이션
R1 : (과목, 담당교수) - 과목이 SuperKey임 . 과목 → 담당교수 만족
| 과목 | 담당교수 |
|---|---|
| DB | 홍길동 |
| OS | 이순신 |
| DB | 홍길동 |
| AI | 강감찬 |
R2: (학생번호, 과목) - (학생번호, 과목)이 SuperKey임 .
| 학생번호 | 과목 |
|---|---|
| S1 | DB |
| S1 | OS |
| S2 | DB |
| S3 | AI |
(학생번호, 과목) → 담당교수는 이제 의미가 없어지고 정상화 완료
✅ 결과:
두 릴레이션 모두 모든 FD에서 결정자가 슈퍼키 → BCNF 만족
이상 현상 제거
