HDFS federation (연합)
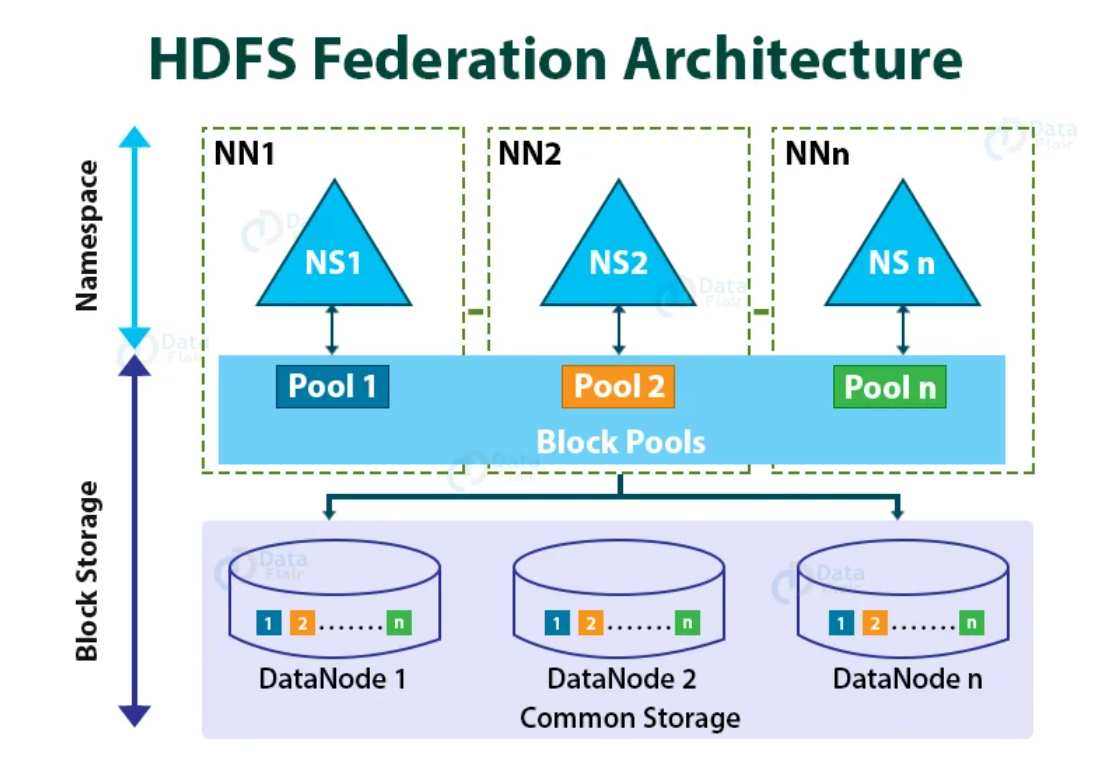
HDFS Federation 도입 이전 기존 HDFS 는 하나의 NameSpace 에 종속된 단일 NameNode 구조여서 해당 NameSpace 가 제공하는 메타데이터 작업량이 커지면 전체 HDFS의 확장성과 성능이 제한된다.
기존 HDFS 의 문제
1. 모든 메타데이터 작업이 하나의 NameNode 에 몰림
- 파일 생성
- 파일 삭제
- 디렉토리 트리 관리
- 블록 매핑 관리
=> NameNode의 병목 현상 발생 원인
2. 하나의 NameSpace 만 존재
모든 애플리케이션이 동일한 NameSpace 를 공유한다.
-
대규모 서비스 (여러 팀, 여러 부서)가 모두 하나에 의존
-
메타데이터가 계속 증가 -> NameNode Ram 요구량 증가
-
여러 NameNode 를 두고 WorkLoad/NameSpace 를 분리할수 없음
HDFS Federation 등장
HDFS 연합 기능은 여러 개의 NameNode 와 NameSpace 를 독립적으로 관리할 수 있도록 도와준다.
단일 Namespace
단일 NameNode
모든 메타데이터 조회 집중 → 병목위의 문제를 아래와 같이 바꿔준다.
Hive 팀 → Namespace A
Spark 팀 → Namespace B
Kafka 팀 → Namespace C
겉으로 보기엔 완전 다른 파일 시스템처럼 작동한다는 것이다. 그러나 내부적으로는 데이터노드들이 모든 네임노드들을 위한 공용의 블록 저장소로서 사용된다. 각각의 데이터 노드는 클러스터 내의 모든 네임노드들에게 등록된다.
Block Pool
또 변경된 점은 블록 풀이다. 블록 풀은 하나의 네임스페이스에 속한 블록들의 집합이다.
각 Nmaespace 는 서로 다른 수의 HDFS 파일, 블록을 생성한다.
데이터노드들은 클러스터에 있는 모든 블록 풀들을 위해 블록들을 저장한다. 네임노드 별로 블록 풀이 존재하는데, 이들은 서로 논리적(물리적 분리 X) 으로 관리된다.
DataNode 1
├── BlockPool(A) → NameNode A 관리 블록
├── BlockPool(B) → NameNode B 관리 블록
└── BlockPool(C) → NameNode C 관리 블록
따라서 새로운 블록을 추가하거나 삭제하는 작업을 수행할 떄 네임노드 사이에 메세지를 전달할 필요 X , 하나의 네임노드에 문제가 생겨도 다른 네임노드들의 블록을 유지하고 있는 데이터노드에는 영향이 없다.
- NameSpace 확장 용이
- NameNode 요청 분산 처리
- 각 NameSpace 의 독립된 저장공간
YARN
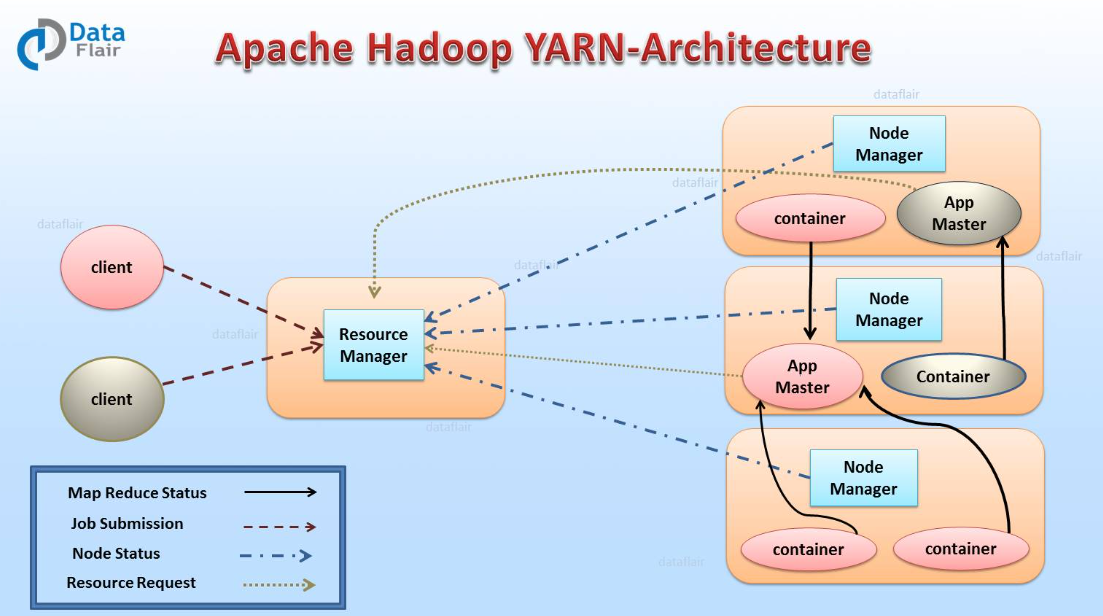
YARN은 애플리케이션이 사용하는 CPU코어와 메모리를 ‘컨테이너’라 불리는 단위로 관리
-
Hadoop의 분산 애플리케이션 실행 → YARN이 클러스터 전체의 부하를 보고 비어 있는 노드부터 컨테이너를 할당
-
클라이언트가 요청하는 작업에 따라 요구되는 리소스의 수가 다를 수 있다.
-
YARN은 다양한 요청 작업의 우선 순위을 정하고 작업 당 리소스 최대 상한선을 결정하며 전체적인 리소스 낭비나 막히는 일 없이 작업이 진행되도록 한다.
YARN: 주로 잡(Job) 중심. 작업을 시작하고, 자원을 할당받아 실행한 뒤, 작업이 끝나면 자원을 반환하는 배치(Batch) 처리 환경에 최적화되어 있다.
YARN 의 구성과 역할
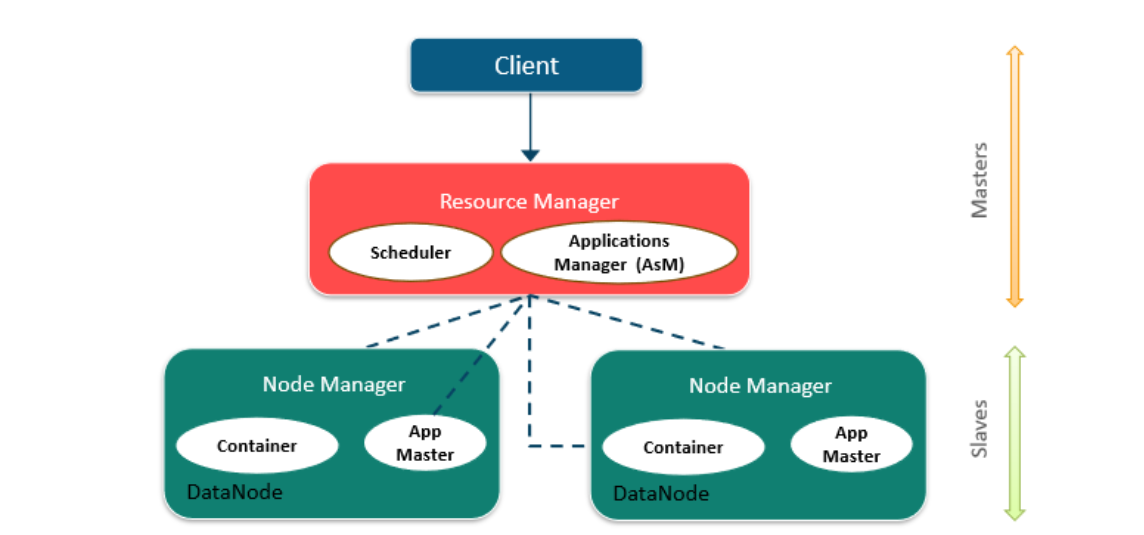
클러스터 자원 관리 측면
Resource Manager (하드웨어 관리)
- Resource Manager 는 한 클러스터 당 한 대만 존재한다.
Scheduler + App Manager
노드 매니저로부터 전달받은 정보를 이용해 클러스터 전체 자원 관리, 자원 사용 상태 모니터링 후 클러스터 내 여러 어플리케이션 사이의 중재자 역할
- 가능하면 독립적인 노드(싱글 머신)에 할당하여 병목이 발생하지 않게 하는게 좋다.
Scheduler
Scheduler 는 실행중인 여러 App 에 대해 자원을 할당해 주는 역할을 수행한다. 실행 중인 APP 중 누구에게 자원을 주는가에 따라 어떤 APP 이 먼저 수행될지 결정한다고 생각하면 된다.
Node Manager (노드 관리)
클러스터 내 각 노드마다 각각 동작하는 데몬으로 리소스 매니저에게 각 노드의 상태 정보를 제공한다.
어플리케이션 수행 시 이후에 설명할 컨테이너라는 데몬을 위한 실행 환경을 만들어주고 그들이 노드 내에서 너무 많은 자원을 사용하지 않도록 현재 노드의 리소스 사용량(CPU, 메모리, 디스크, 네트워크)을 모니터링 , 조정
YARN 작업 예시
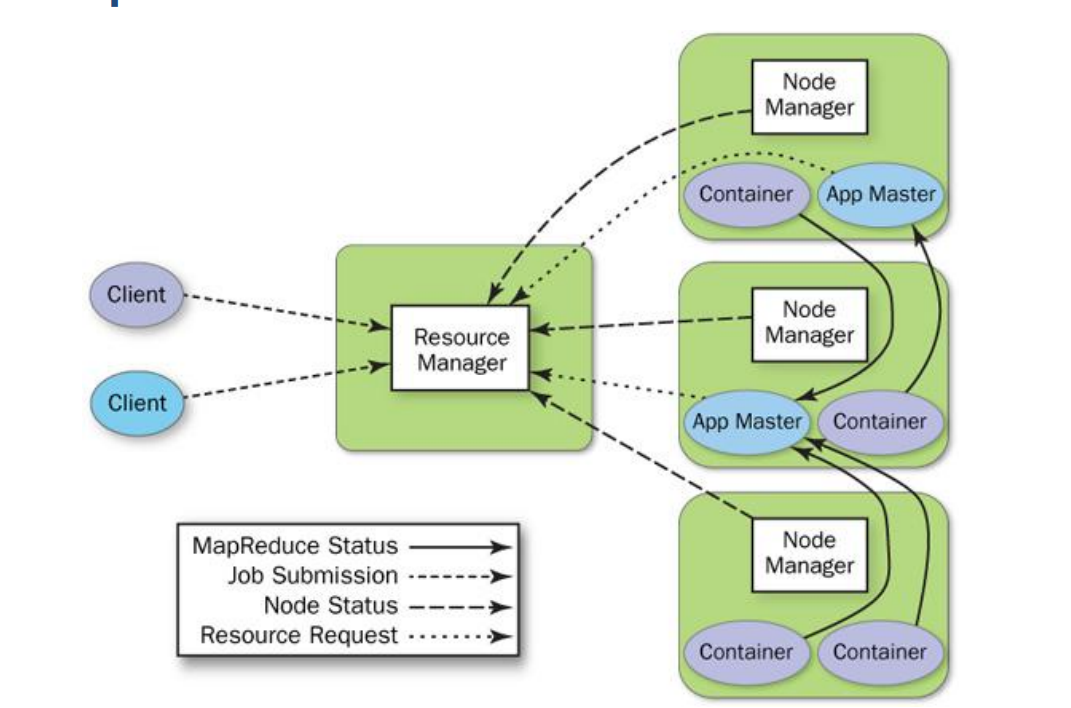
-
Client 가 App을 제출하면 , 가장 먼저 Resource Manager 의 App 매니저가 이를 담당한다.
-
App Manager는 이 어플리케이션 수행 과정을 책임질 App Master를 클러스터 내의 어딘가에 실행, App Manager 는 App Master에 장애가 발생하면 다시 실행시켜서 어플리케이션이 정상적으로 동작하도록 한다.
-
App Master 는 RM 의 Scheduler 에게 자원 할당을 요청하고 승인받는다.
-
APP Master 는 개별 작업을 수행할 노드의 Node Manager 에게 작업 수행을 위한 Container 를 요청
-
Node Manager 는 해당 노드에 App 의 세부 작업을 수행할 Container 를 생성하고 실행 환경을 만들어준다
-
Container 는 세부 작업을 수행하며 진행 상황을 점검하고 중간에 컨테이너에 장애가 발생하면 다시 (3)으로 돌아가 자원을 할당 받고 새로운 Container 를 만들어낸다.
여기서 Container 는 YARN의 논리적 실행 단위!!
애플리케이션 라이프 사이클 관리 기능 측면
Application Master
기본적으로 App Master 와 Scheduler 는 하나의 프로토콜을 가정,
<우선순위 , 요청노드 , 메모리 , 요청하는 컨테이너 수> 같은 정보로 구성
| 우선순위 | 요청노드 | 메모리 | 컨테이너 |
|---|---|---|---|
| 1 | Cluster - 01 | 1GB | 3 |
| 1 | Default-Rack | 1GB | 5 |
| 2 | * | 2GB | 2 |
위 표를 보면 첫번쨰로 각 1GB 짜리 컨테이너 3개를 요청하고
두번째로 Rack 단위로 각 1GB 짜리 컨테이너 5개를 요청
세번째는 노드에 제약을 두지 않고 2GB 짜리 컨테이너 2개를 요청
물론 Scheduler 가 App Master 요청하는 대로 자원을 줄 수 없다. 악의적인 의도가 있는 App 이든 아니든 , 클러스터 리소스에 대한 전체적인 계획을 가지고 거부 할 줄안다.
스케줄링 알고리즘은 여러 개의 큐에 대해
-
가장 유휴한 큐를 선택
-
큐에서 가장 우선순위가 높은 Job 을 선택
-
해당 잡의 자원 요청을 처리
Container
리소스 메니저에 현재 자원 상태 보고
