먼저 하둡 설정 파일에 대해 알아보자
hadoop-env.sh
: 하둡이 실행하는 모든 프로세스에 적용되는 시스템 환경 스크립트
# Set Hadoop-specific environment variables here.
# The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes.
# The java implementation to use. Required.
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-amd64
# Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH=
# The maximum amount of heap to use, in MB. Default is 1000.
# export HADOOP_HEAPSIZE=2000
# Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server
# Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS"
export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS"
export HADOOP_JOBTRACKER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS"
# export HADOOP_TASKTRACKER_OPTS=
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
# export HADOOP_CLIENT_OPTS
# Extra ssh options. Empty by default.
# export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR"
# Where log files are stored. $HADOOP_HOME/logs by default.
# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs
# File naming remote slave hosts. $HADOOP_HOME/conf/slaves by default.
# export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves
# host:path where hadoop code should be rsync'd from. Unset by default.
# export HADOOP_MASTER=master:/home/$USER/src/hadoop
# Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HADOOP_SLAVE_SLEEP=0.1
# The directory where pid files are stored. /tmp by default.
# NOTE: this should be set to a directory that can only be written to by
# the users that are going to run the hadoop daemons. Otherwise there is
# the potential for a symlink attack.
# export HADOOP_PID_DIR=/var/hadoop/pids
# A string representing this instance of hadoop. $USER by default.
# export HADOOP_IDENT_STRING=$USER
# The scheduling priority for daemon processes. See 'man nice'.
# export HADOOP_NICENESS=10export 의 Option 을 정하는 코드로 JVM 옵션을 추가한 것이다.
core-site.xml
: 하둡 파일 시스템과 하둡 맵리듀스에 모두 적용할 수 있는 스크립트
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/root/data-hadoop</value>
</property>
</configuration>기본 파일 시스템 이름 , 임시(tmp) 디렉토리 주소의 위치를 설정한 것
hdfs-site.xml
: 하둡 분산 파일 시스템 설정 스크립트
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>데이터들의 복제본 - dfs.replication 의 개수를 1개로 설정한 것
mapred-site.xml
: 하둡 맵리듀스 설정 스크립트
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>Jobtracker 가 실행되는 주소를 정의할 수 있다.
masters / slave
- masters: 세컨더리 네임노드가 동작하는 노드를 명시
- slaves : 데이터노드와 태스크 트래커가 동작하는 노드를 명시
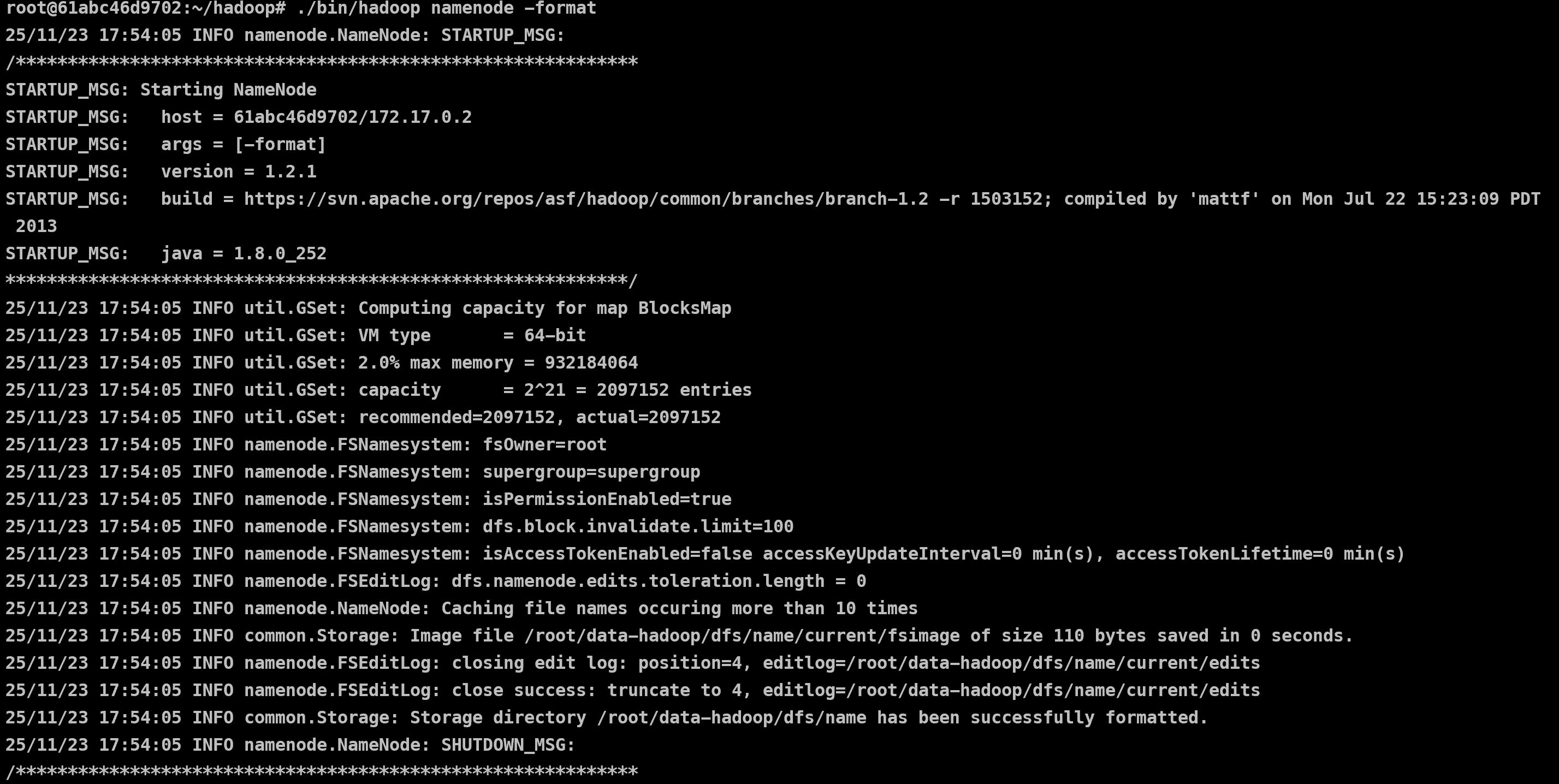
NameNode 포맷
Hadoop 클러스터를 처음 만들 때 (최초 1회) NameNode 가 쓸 메타데이터 저장소가 아직 빈 폴더 상태 → 포맷으로 HDFS 생성 필요하다.
start-all.sh
# Start all hadoop daemons. Run this on master node.
bin=`dirname "$0"`
bin=`cd "$bin"; pwd`
if [ -e "$bin/../libexec/hadoop-config.sh" ]; then
. "$bin"/../libexec/hadoop-config.sh
else
. "$bin/hadoop-config.sh"
fi
# start dfs daemons
"$bin"/start-dfs.sh --config $HADOOP_CONF_DIR
# start mapred daemons
"$bin"/start-mapred.sh --config $HADOOP_CONF_DIRstart-all.sh 를 통해 start-dfs , start-mapred 쉘 스크립트 파일을 열게 된다.
root@61abc46d9702:~/hadoop/bin# cd ..
root@61abc46d9702:~/hadoop# ./bin/start-all.sh
starting namenode, logging to /root/hadoop-1.2.1/libexec/../logs/hadoop--namenode-61abc46d9702.out
localhost: starting datanode, logging to /root/hadoop-1.2.1/libexec/../logs/hadoop-root-datanode-61abc46d9702.out
localhost: starting secondarynamenode, logging to /root/hadoop-1.2.1/libexec/../logs/hadoop-root-secondarynamenode-61abc46d9702.out
starting jobtracker, logging to /root/hadoop-1.2.1/libexec/../logs/hadoop--jobtracker-61abc46d9702.out
localhost: starting tasktracker, logging to /root/hadoop-1.2.1/libexec/../logs/hadoop-root-tasktracker-61abc46d9702.out
root@61abc46d9702:~/hadoop# jps
481 SecondaryNameNode
868 Jps
325 DataNode
166 NameNode
760 TaskTracker
591 JobTracker실행 결과로 jps 를 통해 위와 같이 hadoop 에 필요한 구성요소들이 켜져있음을 확인할 수 있다.
hdfs 사용하기
root@61abc46d9702:~/hadoop# ./bin/hadoop fs -put conf/hadoop-env.sh input
root@61abc46d9702:~/hadoop# ./bin/hadoop fs -ls
Found 1 items
-rw-r--r-- 1 root supergroup 2449 2025-11-23 18:25 /user/root/input
root@61abc46d9702:~/hadoop#hadoop fs -put <로컬파일경로> <HDFS목적지>
로컬에 있던 conf/hadoop-env.sh 파일을 HDFS의 /user/root/input 라는 이름으로 업로드
HDFS 파일 /user/root/input 하나 만든 거라고 보면 된다.
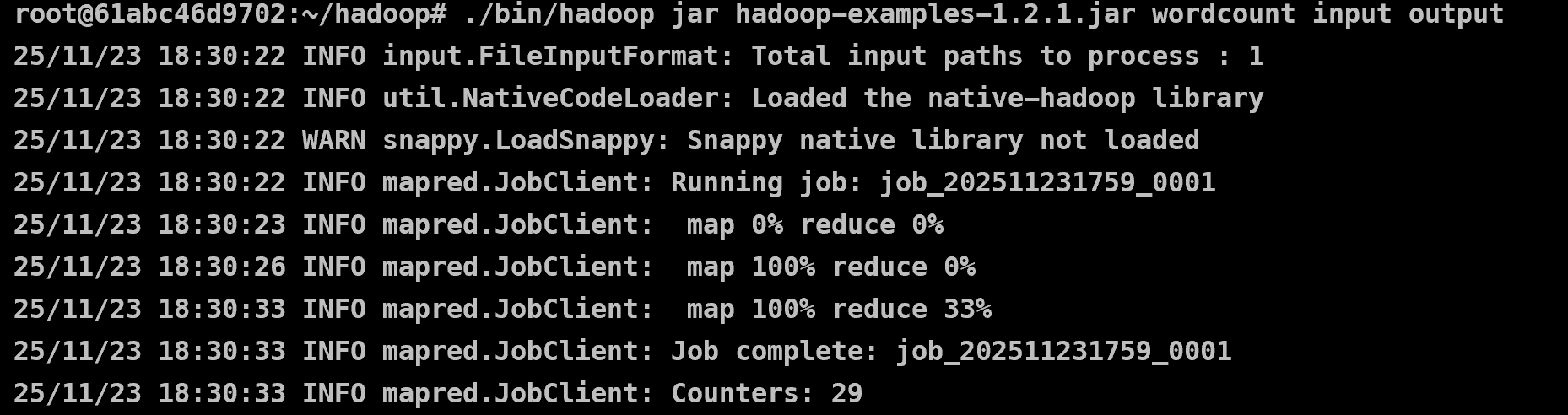
이런식으로 map-reduce 가 진행되고 결과는 output 에 저장된다.

0 to 100 Data Engineer