pytorch를 이용한 간단한 네트워크 연산 수행
- 3개의 입력 (랜덤), 2개 출력
- 은닉층 2 ( 4개의 processing unit)

# 라이브러리 불러오기
import torch
import torch.nn as nn # 딥러닝 네트워크 구현 및 학습을 간단하게 수행할 수 있도록 다양한 함수 제공
import torch.nn.functional as F
# GPU 있는 경우 pytorch 연산을 gpu로, 그렇지 않은 경우 cpu로 수행
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 딥러닝 모델
class Model(nn.Module):
# 네트워크 변수 정의
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(3,4) ## nn.Linear = 선형 연산 (Wx+ b)
self.fc2 = nn.Linear(4,4)
self.fc3 = nn.Linear(4,2)
#네트워크 구조 결정 및 연산 수행
def forward(self, x):
# 선형 연산 수행 후 비선형 함수 통과
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
# 선형 연산만 수행
x = self.fc3(x)
return x
# 네트워크 선언
# Model 클래스 호출 후 연산 장치를 할당하고 model로 선언한다.
model = Model().to(device)
# Pytourch를 이용한 연산 수행
# 입력데이터를 생성한다. (2,3) 랜덤 데이터를 torch로 생성 후 연산 장치를 할당한다.
x = torch.rand(2,3).to(device)
# 딥러닝 모델에 입력 x를 대입하여 결과값을 도출한다. (model의 forward함수 연산)
output = model(x)
# 결과 출력
print(output)
# 결과값을 numpy 변환
# cpu -> 연산장치 cpu로 변환
# detach -> gradient 전파 안되도록 함, 이를 수행하면 해당 텐서값은 딥러닝 학습 수행에 사용 x, numpy과정을 위해 꼭 수행해야 한다.
# numpy -> tensor를 numpy로 변환
output_np = output.cpu().detach().numpy()
print(output_np)결과 -> 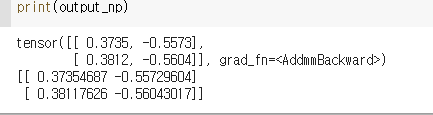
코드 중
def __init__(self):
super(Model, self).__init__()
self.fc1 = nn.Linear(3,4) ## nn.Linear = 선형 연산 (Wx+ b)-> 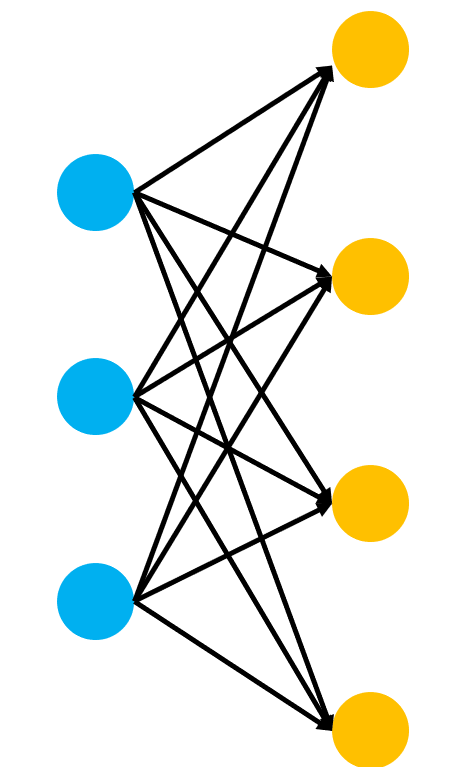
self.fc2 = nn.Linear(4,4)
self.fc3 = nn.Linear(4,2)이 부분은 각각
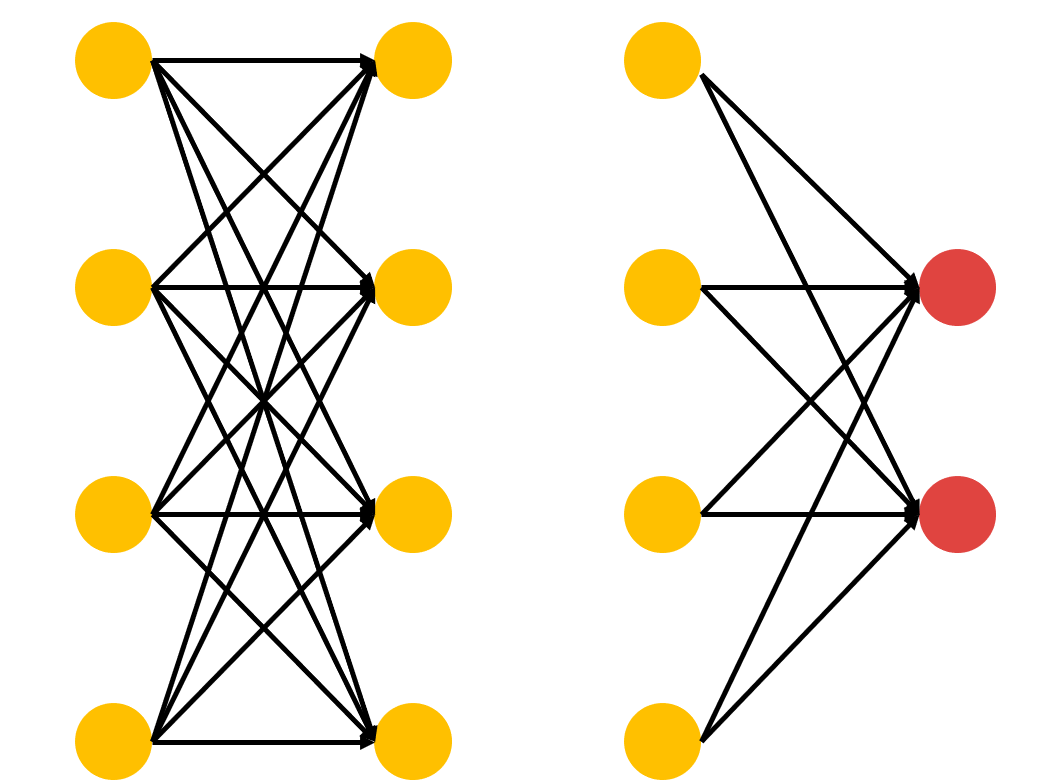
이 부분들을 나타낸다.
