MNIST
- 0~9로 이루어진 손글씨 숫자 데이터
- 28x28 흑백
- 60000개 학습 데이터, 10000개 테스트 데이터
=> pytorch 이용해 MNIST 데이터 분류 ANN 네트워크 구현
이미지 = batch X 28 X 28 X 1 (흑백이기 때문)
--> 벡터 : batch X 28 * 28 = batch x 784
인공신경망 연산 -> linear layer, 3
출력 = batch x 10 (0-9 각각에 대한 확률이기 때문)
코드
import torch
import torch.nn as nn # 딥러닝 네트워크 구현 및 학습을 간단하게 수행할 수 있도록 다양한 함수 제공
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
# datasets = 다양한 데이터셋 제[공
# tranforms = 데이터 전처리 등 수행
import numpy as np
# GPU 있는 경우 pytorch 연산을 gpu로, 그렇지 않은 경우 cpu로 수행
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 파라미터 설정
batch_size = 128 # 한번 학습시 128개의 데이터를 통해 학습
num_epochs = 10 # 모든 데이터에 대해 10번 학습 수행
learning_rate = 0.00025 # 학습률 (학습 속도 결정 -> 너무 작으면 학습 속도가 느립, 값 크면 최적 x)
# MNIST 데이터 다운로드
trn_dataset = datasets.MNIST('./mnist_data/', download=True, train=True, transform=transforms.Compose([transforms.ToTensor()]))
val_dataset = datasets.MNIST('./mnist_data/', download=False, train=False, transform=transforms.Compose([transforms.ToTensor()]))
# 다운로드 경로,
# download = True 인 경우 데이터셋 다운 받음, 이미 다운 받아진 경우 다운 진행 x
# train -> True 인 경우 학습 데이터로 사용, False 인 경우 학습 데이터로 사용 x
# pytorch 텐서의 형태로 데이터 출력 -> pytorch 연산의 경우ㅠ tensor 형태로 연산 진행
# DataLoader 설정
trn_loader = torch.utils.data.DataLoader(trn_dataset, batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size, shuffle=True)
# ANN 네트워크
class ANNClassifier(nn.Module):
def __init__(self):
super(ANNClassifier, self).__init__() # 항상 torch.nn.Module을 상속받고 시작
self.fc1 = nn.Linear(28*28,256) ## 28*28 = 입력 데이터의 크기 (28*28 이미지)
self.fc2 = nn.Linear(256,64)
self.fc3 = nn.Linear(64,10)
self.drop = nn.Dropout(p=0.2) # 20% 노드의 출력을 0으로 도출
# 이미지 데이터의 구조 변환 (batch x 28 x 28 x 1) -> (batch x 28*28)
def forward(self, x):
x = x.view(x.size(0), -1) # 선형 연산 수행 후 비선형 함수(relu) 통과
x = F.relu(self.fc1(x))
x = self.drop(x) # dropout 수행
x = F.relu(self.fc2(x))
x = self.drop(x)
# 선형 연산만 수행
x = self.fc3(x)
return F.softmax(x, dim=1) # 최종 결과에 softmax 연산 수행
# softmax : 출력 결과를 확률로 변환 (합 = 1), 입력에 대한 결과의 확률을 알 수 있음
# 정확도를 도출하는 함수
# y = 네트워크 연산 결과, label = 실제 결과
# label은 현재 입력이 어떤 숫자인지의 값을 보여준다.(batch size x 1)
# y는 각 숫자에 대한 확률을 나타낸다. (batch size x 10)
def get_accuracy(y, label):
y_idx = torch.argmax(y, dim=1)
# argmax = 확률 중 가장 큰 값의 인덱스를 반환하여 label과 동일한 형식으로 변환
# 모든 입력에 대해 정답을 맞춘 개수를 전체 개수로 나눠주어 정확도 반환
result = y_idx-label
num_correct = 0
for i in range(len(result)):
if result[i] == 0:
num_correct += 1
return num_correct/y.shape[0]
# 네트워크, 손실함수, 최적화기 선언
ann = ANNClassifier().to(device) # 네크워크 정의, 설정한 device에서 딥러닝 네트워크 연산을 하도록 설정
criterion = nn.CrossEntropyLoss() # 손실함수 설정, 분류 문제에서 많이 사용
optimizer = optim.Adam(ann.parameters(), lr=learning_rate)
num_batches = len(trn_loader) # 한 epoch에 대한 전체 미니배치의 수
# 학습 수행
for epoch in range(num_epochs):
# 학습시 손실함수 값과 정확도 ㄱㅣ록하기 위한 리스트
trn_loss_list = []
trn_acc_list = []
# 1epoch연산을 ㄷ위한 반복문
# 여기서 data는 각 배치로 나누어진 데이터와 정답을 포함
for i, data in enumerate(trn_loader):
# 데이터 처리
ann.train() #네트워크 학습을 위한 모드로 설정
# 학습데이터 (x: 입력, label: 정답)를 받아온 후 device에 올려줌
x, label = data
x = x.to(device)
label = label.to(device)
# 네트워크 연산 및 손실함수 계산
model_output = ann(x) # 네트워크 연산 수행 후 출력값 도출 (입력 : x, 출력 : model_output)
loss = criterion(model_output, label) # 손실함수 값 계산 -> 네트워크 연사ㅓㄴ 결과를 연산하여 손실함수 값 도출
# 네트워크 업데이트
optimizer.zero_grad() # 학습 수행 전 미분값을 0으로 초기화 (학습 전 꼭 수행 !!!!)
loss.backward() # 네트워크 변수(가중치 w, 편향 b)에 대한 기울기가 계산
optimizer.step() # 네트워크 변수 업데이트
# 학습 정확도 및 손실함수 값 기록
# 네트워크의 연산 결과와 실제 정답 결과를 비교하여 정확도를 도출
trn_acc = get_accuracy(model_output, label)
# 손실함수 값을 trn_loss_list 추가 (item : 하나의 값으로 된 tensor를 일반 값으로 바꿔줌)
trn_loss_list.append(loss.item())
# 정확도 값을 trn_acc_list에 추가
trn_acc_list.append(trn_acc)
# 학습 진행 상황 출력 및 검증셋 연산 수행
if (i+1) % 100 == 0: # 매 100번째 미니배치 연산마다 진행상황 출력
ann.eval() # 네트워크를 검증 모드로 설정
with torch.no_grad(): # 학습에 사용하지 않는 코드들은 해당 블록 내에 기입
# 검증시 손실함수 값과 정확도를 저장하기 위한 리스트
val_loss_list = []
val_acc_list = []
for j, val in enumerate(val_loader):
val_x, val_label = val
val_x = val_x.to(device)
val_label = val_label.to(device)
val_output = ann(val_x)
val_loss = criterion(val_output, val_label)
val_acc = get_accuracy(val_output, val_label)
val_loss_list.append(val_loss.item())
val_acc_list.append(val_acc)
print("epoch: {}/{} | step: {}/{} | trn loss: {:.4f} | val loss: {:.4f} | trn acc: {:.4f} | val acc: {:.4f}".format(
epoch+1, num_epochs, i+1, num_batches, np.mean(trn_loss_list), np.mean(val_loss_list), np.mean(trn_acc_list), np.mean(val_acc_list)
))결과
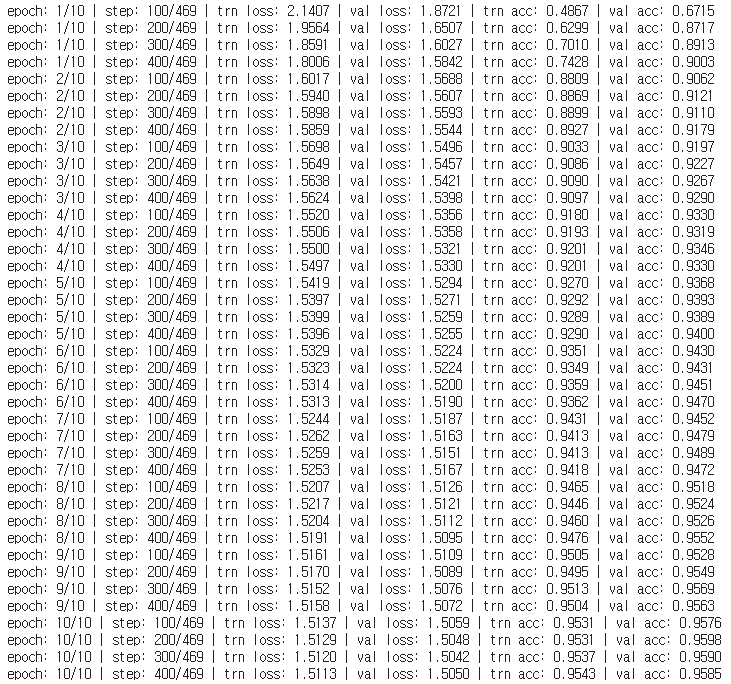
batch_size 변경
batch_size : 128 -> 10
-> 학습정확도와 검증 정확도 모두 올랐다.
대신 한 번의 epoch를 오래 진행한다.
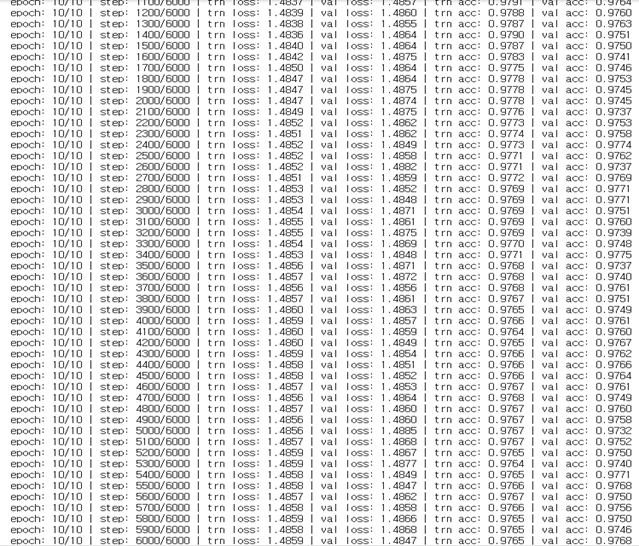
batch_size : 128 -> 250

학습 정확도와 검증 정확도 모두 줄었다.
대신 학습이 빨리 진행된다.
learning_rate 변경
learning_rate : 0.0025 -> 0.05
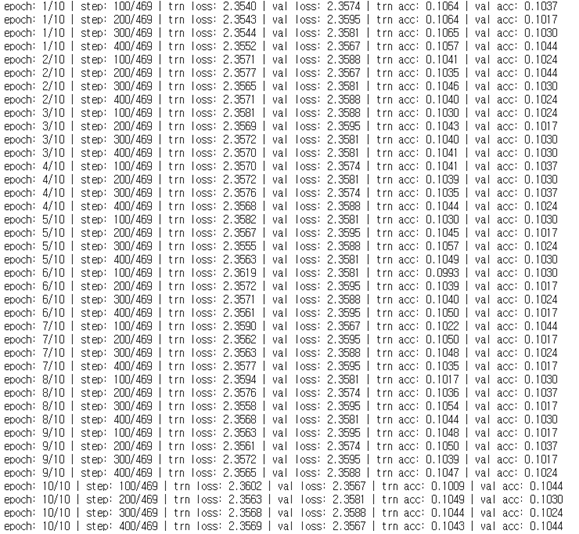
값이 커져서 정확도가 매우 떨어진다.
learning_rate : 0.0025 -> 0.0001
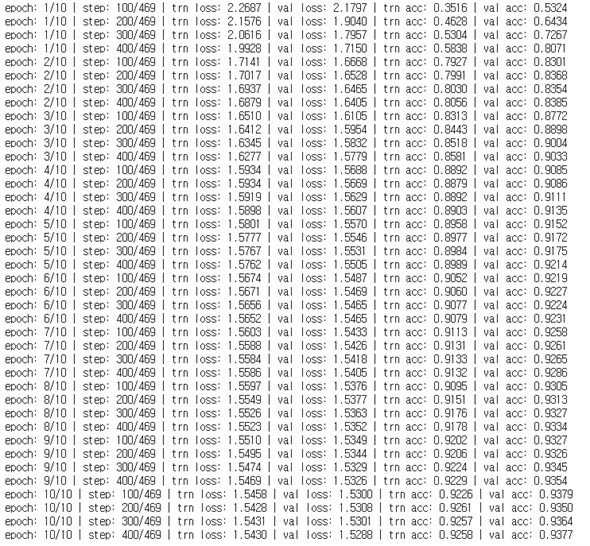
정확도도 살짝 떨어지고, 학습 시간은 비슷하다.
learning_rate : 0.0025 -> 0.00001
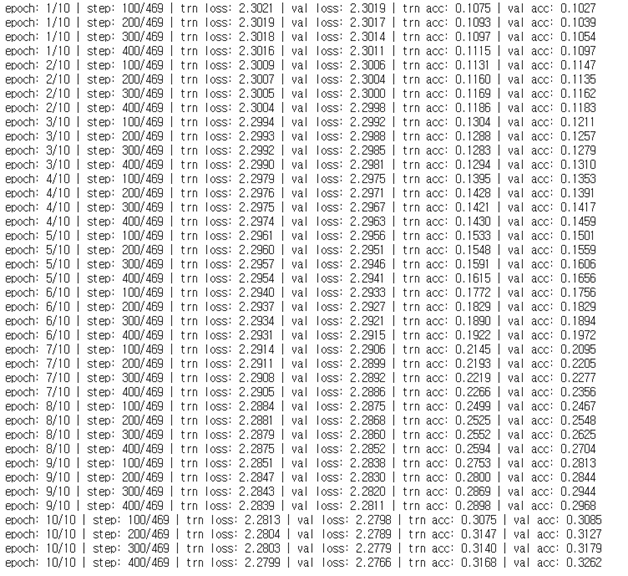
정확도가 많이 떨어진다.
dropout 변경
dropout : 0.2 -> 0.7
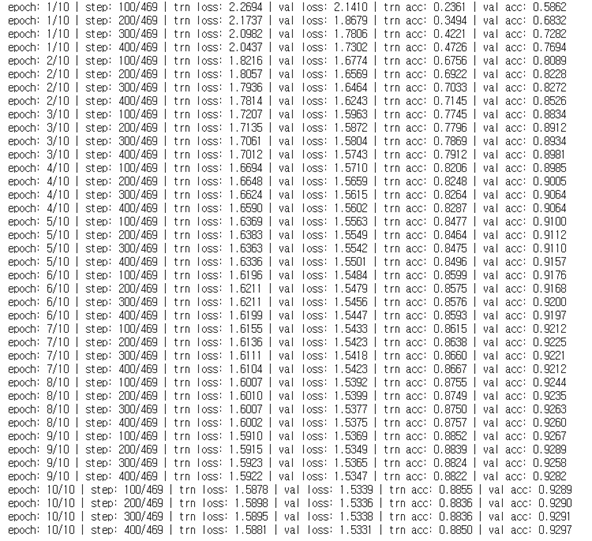
드롭아웃을 너무 많이 실행하면 없어지는 값이 많아서인지 정확도가 떨어진다.
dropout : 0.2 -> 0.05
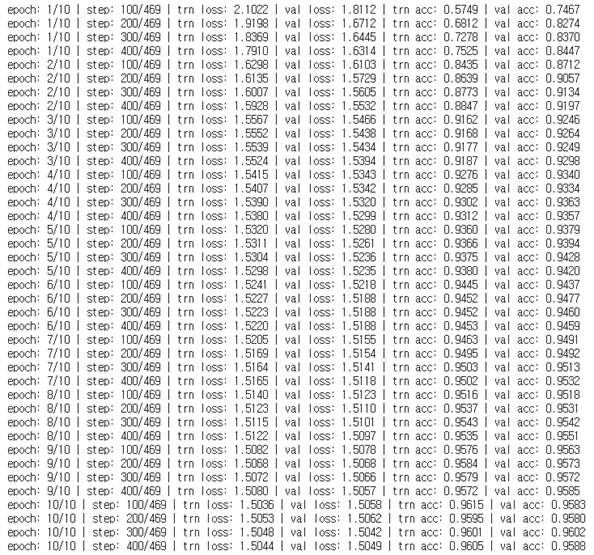
드롭아웃을 조금 실행하면 기존보다는 적지만 overfitting을 조금 줄이는 결과를 가져와 정확도가 오르는 것 같다.
num_epochs 변경
num_epochs : 10 -> 3

너무 학습을 적게 해서 underfitting 되었을 것 같다.
num_epochs : 10 -> 15
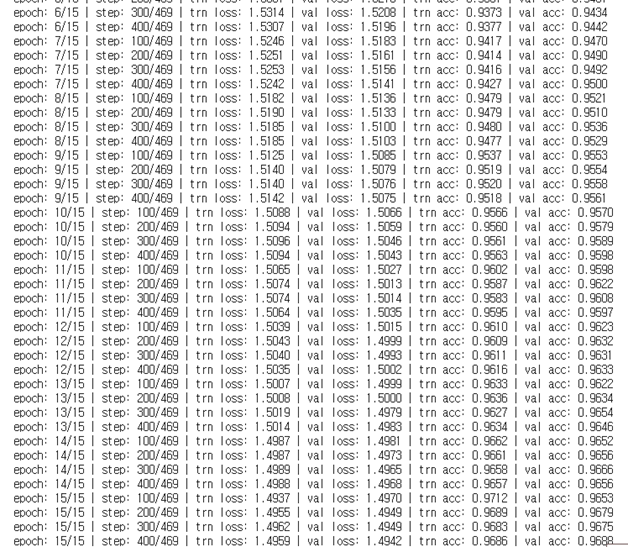
학습 정확도와 검증 정확도 모두 올랐다.
