groupby()
- 데이터를 특정 기준으로 그룹핑할 때 활용한다.
✔ 예제 데이터생성
df = pd.DataFrame({
'city': ['부산', '부산', '부산', '부산', '서울', '서울', '서울'],
'fruits': ['apple', 'orange', 'banana', 'banana', 'apple', 'apple', 'banana'],
'price': [100, 200, 250, 300, 150, 200, 400],
'quantity': [1, 2, 3, 4, 5, 6, 7]
})
df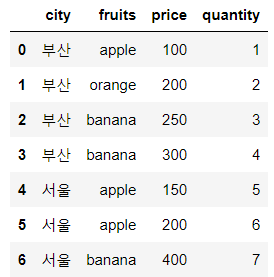
✔ city별 평균
df.groupby('city').mean()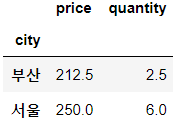
✔ city별 fruits별 평균
df.groupby(['city','fruits']).mean()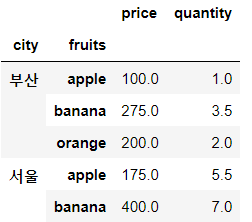
✔ 1개의 특정 컬럼에 대한 결과 도출, price 컬럼에 대한 결과만 도출하고 싶은 경우 맨 끝에 지정한다. ('price'에 []를 하나 더 감싸주면 데이터 프레임 형식으로 출력됨)
df.groupby(['city','fruits'])[['price']].mean()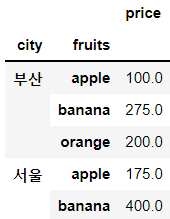
✔ groupby를 사용하면 기본으로 그룹 라벨이 index가 되는데, 그룹 라벨 index를 사용하고 싶지 않은 경우 as_index=False 옵션을 설정한다.
df.groupby(['city','fruits'], as_index=False).mean()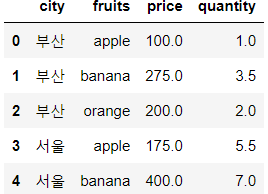
✔ 그룹 안에 데이터를 확인하고 싶은 경우 get_group() 옵션 사용
df.groupby('city').get_group('부산')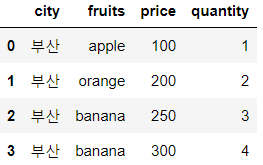
✔ 각 그룹의 사이즈를 확인하고 싶은 경우 size() 옵션 사용, size()결과는 Series이라는 1차원 배열 오브젝트로 반환됨
df.groupby('city').size()
✔ 여러 가지의 통계 값을 적용할 때는 agg() 옵션을 사용
df.groupby(['city', 'fruits'])[['quantity', 'price']].agg(['mean', 'sum'])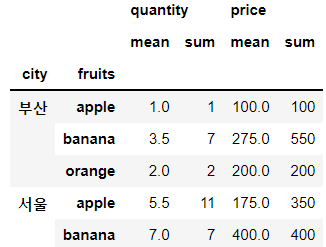

Study note