SQL / MySQL
1.SQL? MySQL?

오늘날에는 IT업계가 아니더라도 거의 모든 회사가 자신들의 각종 정보를 데이터로 전산화 해서 저장한다.이때 이 수 많은 회사들이 각자의 전산화 시스템을 구축하기에는 비효율적일 것이다.그래서 이런 시스템을 대신 만들어 주는 회사가 있고 이 회사가 데이터를 보관하고 관리하
2.MySQL접속, Database관리, User 관리

root계정으로 mysql에 접속 (터미널에서 실행)현재 database 목록 확인database 생성해당 데이터베이스로 이동(사용)database 삭제MySQL에서는 스키마와 데이터베이스가 같은말로 쓰인다고 한다.스키마(데이터베이스) 안에 테이블이있고, 테이블안에 데
3.About Table
실습할 데이터베이스 생성 : testdb라는 이름의 데이터베이스 생성 후 문자열의 기본값을 utf8mb4로 설정table 생성 : id(int)와 name(varchar(16)) 칼럼을 가지는 mytable이라는 이름의 테이블 생성table 목록 확인table 정보 확
4.SELECT, INSERT, UPDATE, DELETE, WHERE
\-> table에 데이터를 추가하는 명령어person 테이블에 데이터 insert : 입력한 칼럼 이름의 순서와 값의 순서가 일치해야 한다.person 테이블에 모든 칼럼값을 insert : 모든 칼럼값을 추가하는 경우 칼럼 이름을 지정하지 않아도 되지만 입력하는 값
5.ORDER BY
NOT NULL 제약 조건을 설정하면, 해당 필드는 NULL값을 저장할 수 없다. 즉, 이 제약 조건이 설정된 필드는 무조건 데이터를 가지고 있어야 한다. NOT NULL 제약 조건은 CREATE 문으로 테이블을 생성하거나 ALTER 문으로 추가할 수도 있다.일반적으로
6.비교연산자, 논리연산자, NULL
A != B : A와 B가 같지 않은A <> B : A와 B가 같지 않은✔ 나이가 29세가 아닌 데이터 검색AND : 조건을 모두 만족하는 경우 TRUEOR : 하나의 조건이라도 만족하는 경우 TRUENOT : 조건을 만족하지 않는 경우 TRUEBETWEEN :
7.AWS RDS
AWS RDS의 데이터베이스에서 해당하는 데이터베이스의 작업상태를 '시작'으로 바꾼다.remote 서버이기 때문에 나의 local에 설정된 mysql 8.0 command line client에서 실행하면 안된다.터미널에서 mysql -h <엔드포인트> -P &l
8.UNION
여러개의 SQL문을 합쳐서 하나의 SQL문을 만들어 주는 방법이다.단, 칼럼의 개수가 같아야 한다.UNION : 중복된 값을 제거하여 알려준다.UNION ALL : 중복된 값도 모두 보여준다.✔ UNION✔ UNION ALL✔ 가수가 직업인 연예인의 이름, 직업을 검색
9.JOIN
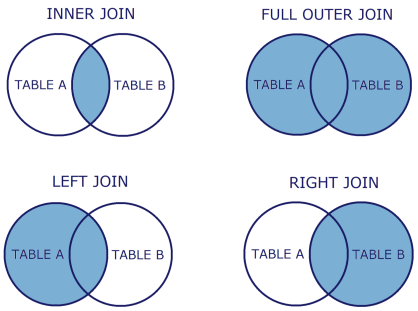
2개 이상의 테이블을 결합하는 것결합하려는 테이블에서 공통된 요소들을 통해 결합하는 조인 방식이다.✔ snl_show에 호스트로 출연한 celeb을 기준으로 celeb 테이블과 snl_show 테이블을 INNER JOIN2개의 테이블에서 공통영역을 포함해 왼쪽 테이블의
10.ALIAS, DISTINCT, LIMIT
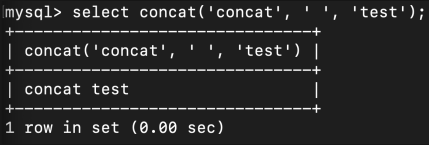
여러 문자열을 하나로 합치거나 연결✔ 글자 합치기✔ 테이블을 이용하여 글자 합치기칼럼이나 테이블 이름에 별칭 생성✔ name은 이름으로 agency는 소속사로 별칭을 만들어서 검색✔ name과 job_title을 합쳐서 profile 이라는 별칭을 만들어서 검색✔ sn
11.SQL FILE, BACKUP

sql 쿼리를 모아놓은 파일먼저 작업하고자 하는 디렉토리를 생성한 뒤 이동하자.해당 디렉토리에서 vscode를 실행하자.해당 디렉토리에서 새 파일을 만들고 확장자를 sql로 입력하면 sql파일을 생성할 수 있다.sql파일에 쿼리문을 작성한다.sql파일을 실행한다.✔ 1
12.Python with MySQL
먼저 작업 디렉토리로 이동한 후 jupyter notebook과 mysql을 실행한다.사용 할 가상환경을 선택한다.
13.GROUP BY, CONSTRAINT, PRIMARY KEY, FOREIGN KEY
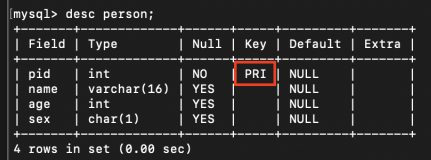
PRIMARY KEY(기본키) 테이블의 각 레코드를 식별한다. 중복되지 않는 고유값을 포함한다. NULL값을 포함할 수는 없다. 테이블당 하나의 기본키를 갖는다.
14.AGGREGATE FUNCTIONS(집계함수)
여러 컬럼 혹은 여러 테이블 전체 컬럼으로부터 하나의 결과값을 반환하는 함수총 갯수를 계산해 주는 함수✔ police_station 테이블에서 데이터는 모두 몇개인가✔ crime_status 테이블에서 중복을 제외한 경찰서는 총 몇군데인가숫자 칼럼의 합계를 계산해주는
15.SCALAR FUNCTIONS

입력값을 기준으로 단일 값을 반환하는 함수영문을 대문자로 반환하는 함수✔ 다음의 문장을 모두 대문자로 조회✔ $15가 넘는 메뉴를 대문자로 조회문자열 부분을 반환하는 함수SELECT MID(string, start_position, length)string : 원본 문
16.SQL SUBQUERY
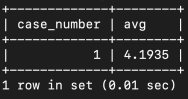
하나의 sql문 안에 포함되어 있는 또 다른 sql문을 의미한다.메인쿼리가 서브쿼리를 포함하는 종속적인 관계이다.서브쿼리는 메인쿼리의 칼럼을 사용할 수 있다.메인쿼리는 서브쿼리의 칼럼을 사용할 수 없다.서브쿼리는 괄호로 묶어서 사용한다.단일 행 혹은 복수 행 비교 연산
17.COUNT
COUNT 함수는 테이블의 컬럼의 데이터 갯수를 가져온다.이 때 NULL인 데이터는 자동으로 제외하고 계산한다.✔ 전체 행 개수 가져오기✔ name 열의 데이터 개수 가져오기✔ name 열이 NULL로 되어있는 값의 컬럼수 가져오기
18.날짜, 시간 관련
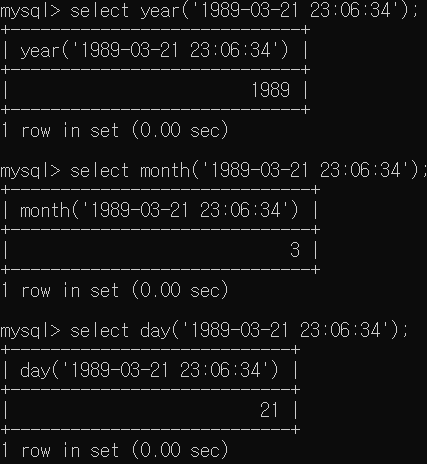
DATE는 날짜를 저장할 수 있는 타입이다.기본형식은 'YYYY-MM-DD'이다.DATETIME은 날짜와 함께 시간까지 저장할 수 있는 타입이다.기본형식은 'YYYY-MM-DD HH:MM:SS'이다.TIME은 시간을 저장할 수 있는 타입이다.기본 형식은 'HH-MM-S
19.CASE, IF
CASE는 2가지 문법(switch문, if문)이 가능하다.value와 compare_value 값이 같으면 THEN절을 반환한다.만약 서로 같지 않으면 ELSE절을 반환한다.이때 ELSE절이 없으면, NULL을 반환한다.WHEN 뒤의 condition의 논리값이 참이
20.변수(variable)

사용자가 직접 정의하는 변수이다.저장하는 값에 의해 자료형이 정해지며 integer, decimal, float, binary, 문자열 타입만 취급할 수 있다.변수를 초기화 하지 않은 경우 값은 NULL, 자료형은 string 타입이다.SET 이외의 명령문에서는 = 가
21.MOD, REPEAT

MOD함수는 n을 m으로 나눈 나머지를 반환한다.
22.WITH, WITH RECURSIVE
가상/임시 테이블을 만드는 방법이다.데이터베이스에 저장되는 테이블은 아니다.메인쿼리에서 쓸 서브쿼리를 미리 with절에 기술해 주는것이라 생각하면 쉽다.with절은 동일한 검색 쿼리를 반복적으로 사용할 때, 재사용성을 높이고자 사용한다.
23.CONCAT, GROUP_CONCAT
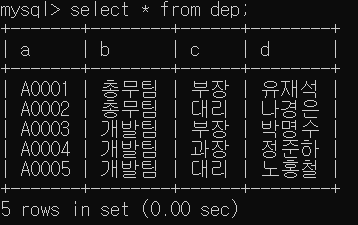
여러 문자열을 하나로 합치거나 연결SELECT문에 사용✔ 글자 합치기✔ 테이블을 이용하여 글자 합치기여러개의 Row로 되어 있는 데이터를 한개의 값으로 묶어서 가지고오고 싶을때 사용한다.✔ 부서별 팀원 보기✔ 부서별 팀원 이름을 내침차순으로 보기✔ 구분자를 이용하여 부
24.VIEW
VIEW란 데이터베이스에 존재하는 일종의 가상 테이블이다.테이블처럼 행과 열이 있지만 실제로 데이터를 저장하고 있지 않고 보여주는 역할만 수행한다.여러 테이블을 들러서 확인하거나 SELECT문을 여러개 사용할 때 발생하는 번거로움을 줄여주는 역할을 한다.쿼리를 재사용할
25.WINDOW FUNCTION
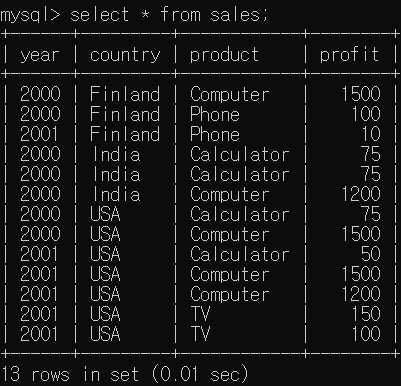
Analytic SQL, Analytic Function이라고도 한다.group by만 쓰게되면 집합의 레벨도 바뀌고, 쓸 수 있는 값의 범위도 좁아지고, 여러번 join해야하는 여러가지 불편한점이 많았다.하지만 window function을 쓰게되면 원본 데이터의 집