Python으로 MySQL 접속하는 방법
-
먼저 작업 디렉토리로 이동한 후 jupyter notebook(.ipynb)을 실행한다.
-
사용 할 가상환경을 선택한다.
- Python에서 MySQL을 사용하기 위해서 먼저 MySQL Driver를 설치한다.
pip install mysql-connector-python- 설치 확인
import mysql.connector- MySQL에 접속하기 위한 코드 작성
abcde = mysql.connector.connect(
host = "hostname",
user = "username",
password = "password"
)✔ Local Database에 연결하기 위한 코드
import mysql.connector
local = mysql.connector.connect(
host = "localhost",
user = "root",
password = "****"
)✔ AWS RDS(database-1)에 연결하기 위한 코드
remote = mysql.connector.connect(
host = "엔드포인트",
port = 3306,
user = "admin",
password = "****"
)DATABASE에 접속하고 나오는 법
- 특정 Database에 접속하기 위한 코드
import mysql.connector
abcde = mysql.connector.connect(
host = 'hostname',
port = portnumber,
user = 'username',
password = 'password',
database = 'databasename'
)- 빠져나오는 코드
abcde.close()✔ Local MySQL의 tmp데이터베이스에 연결&나오기
import mysql.connector
local = mysql.connector.connect(
host = 'localhost',
user = 'root',
password = '****',
database = 'tmp'
)
local.close()✔ AWS RDS(database-1)의 tmp에 연결&나오기
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
remote.close()EXECUTE SQL
- Query를 실행하기 위한 코드
✔ remote에서 테이블 생성하기
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
cur = remote.cursor()
cur.execute("CREATE TABLE tablename (id int, filename varchar(16))")
remote.close()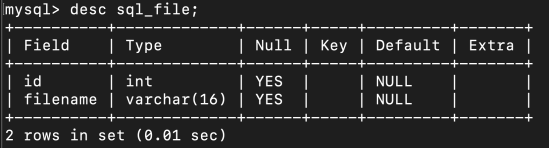
✔ remote에서 테이블 삭제하기
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
cur = remote.cursor()
cur.execute("DROP TABLE tablename")
remote.close()✔ sql 파일 실행하기(먼저 작업 디렉토리에 실행할 sql 파일 생성)
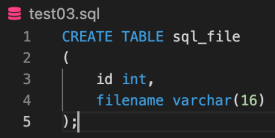
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
cur = remote.cursor()
sql = open("test03.sql").read()
cur.execute(sql)
remote.close()✔ sql 파일 안에 Query가 여러개 존재하는 경우 (Multi=True)
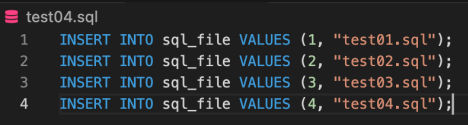
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
cur = remote.cursor()
sql = open("test04.sql").read()
for result_iterator in cur.execute(sql, multi=True):
if result_iterator.with_rows:
print(result_iterator.fetchall())
else:
print(result_iterator.statement)
remote.commit()
remote.close()# FETCH
-
SQL 쿼리의 경우 Cursor 객체의 fetchall(), fetchone(), fetchmany() 등의 메서드를 사용하여 데이터를 서버로부터 가져온 후, Fetch 된 데이터를 사용한다.
-
커서의 fetchall() 메서드는 모든 데이터를 한꺼번에 클라이언트로 가져올 때 사용된다.
-
fetchone()은 한번 호출에 하나의 Row 만을 가져올 때 사용된다. fetchone()을 여러 번 호출하면, 호출 때 마다 한 Row 씩 데이터를 가져오게 된다.
-
fetchmany(n) 메서드는 n개 만큼의 데이터를 한꺼번에 가져올 때 사용된다.
✔ 읽어올 데이터 양이 많은 경우 cursor 생성시 buffer설정 (buffered = True)
remote = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)
cur = remote.cursor(buffered=True)
cur.execute("SELECT * FROM tablename")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)
remote.close()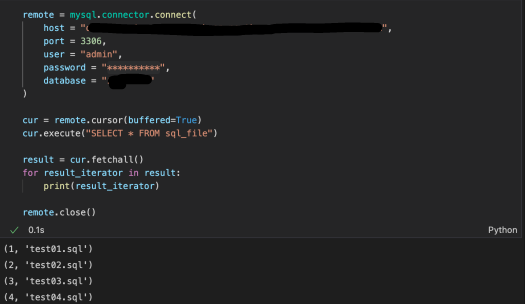
Python으로 csv에 있는 데이터를 INSERT 하기
- pandas로 데이터 읽어오기
import pandas as pd
df = pd.read_csv('police_station.csv')
df.head()
- remote의 tmp데이터베이스에 연결하기
conn = mysql.connector.connect(
host = '엔드포인트',
port = 3306,
user = 'admin',
password = '****',
database = 'tmp'
)- cursor 만들기 (읽어올 양이 많은 경우 buffered=True)
cursor = conn.cursor(buffered=True)- INSERT문 만들기
sql = "INSERT INTO police_station VALUES (%s, %s)"-> %s는 문자형, %d는 숫자형을 의미한다.- 테이블에 데이터 집어넣기, commit()은 database에 적용하기 위한 명령임
for i, row in df.iterrows():
cursor.execute(sql, tuple(row))
print(tuple(row))
conn.commit()
- 결과 확인하기
cursor.execute("SELECT * FROM police_station")
result = cursor.fetchall()
for row in result:
print(row)
- 검색 결과를 pandas로 읽기
import pandas as pd
df = pd.Dataframe(result)
df.head()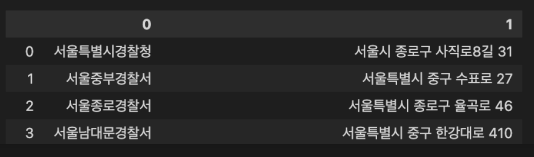

Study note