
오늘은 파이토치를 사용하여 간단한 신경망을 만들어보겠습니다.
먼저 신경망에 대한 설명은 아래의 포스팅은 여기를 눌러주세요.
▶라이브러리 임포트
신경망을 정의하기 위해 필요한 라이브러리들을 임포트 해줍니다.
import torch
import numpy as np
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
import torch.nn.functional as Ftorch → 파이토치 라이브러리
numpy → 수치해석용 라이브러리
sklearn → 파이썬의 대표적인 머신러닝 라이브러리
matplotlib → 시각화를 위한 라이브러리
▶데이터셋 준비
신경망을 학습시키기 위한 데이터를 준비해 줍니다.
x_train : 학습을 위한 입력 데이터
y_train : 학습을 위한 출력 데이터
x_test : 테스트를 위한 입력 데이터
y_test : 테스트를 위한 출력 데이터
x_train, y_train = make_blobs(n_samples = 80, n_features = 2, centers=[[1,1],[-1,-1],[1,-1],[-1,1]],shuffle = True, cluster_std = 0.3)
x_test, y_test = make_blobs(n_samples = 20, n_features = 2, centers=[[1,1],[-1,-1],[1,-1],[-1,1]],shuffle = True, cluster_std = 0.3)
## change from 4 label data to 2 label data
def new_label(y_, from_, to_):
y = np.copy(y_)
for f in from_:
y[y_ == f] = to_
return y
y_train = new_label(y_train, [0,1], 0)
y_train = new_label(y_train, [2,3], 1)
y_test = new_label(y_test, [0,1], 0)
y_test = new_label(y_test, [2,3], 1)
## convert numpy format to tensor format
x_train = torch.FloatTensor(x_train)
x_test = torch.FloatTensor(x_test)
y_train = torch.FloatTensor(y_train)
y_test = torch.FloatTensor(y_test)여기서는 sklearn의 make_blobs를 이용하여 2차원 데이터를 생성해 줍니다. 여기서 학습(train) 데이터는 80개, 테스트(test) 데이터는 20개로 설정 하였습니다. 또한 4개의 클러스터를 생성하였습니다. (즉, 클래스가 4개입니다. 0~3) 좀 더 간단하게 보기 위해 기존의 0,1 클래스를 가지는 데이터는 0클래스로, 2,3 클래스를 가지는 데이터는 1클래스로 바꾸어 주었습니다.
마지막으로 데이터 셋이 생성되었으면, numpy형태의 데이터를 파이토치의 tensor형태로 바꿔줍니다.
▶데이터 시각화
이부분은 신경망에 반드시 필요한 부분은 아니지만, 데이터를 시각화해서 보기 위해 따로 추가한 부분입니다.
## visual function
def vis_data(x, y = None, c = 'r'):
if y is None:
y = [None] * len(x)
for x_, y_ in zip(x,y):
if y_ is None:
plt.plot(x_[0], x_[1], '*',markerfacecolor = 'none',markeredgecolor = c)
elif y_ == 0:
plt.plot(x_[0], x_[1], c+'o')
elif y_ == 1:
plt.plot(x_[0], x_[1], c+'+')
#check data graph
plt.figure()
vis_data(x_train, y_train, c = 'r')
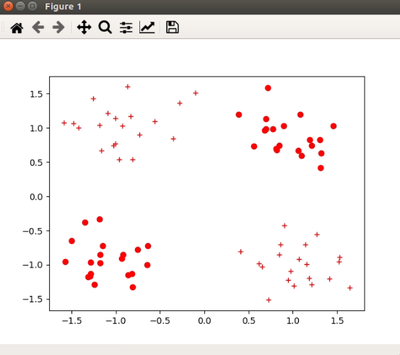
plt.show()만약 데이터가 어떠한 클래스에도 속하지 않을 경우 *으로 나타내고, 0에 속할 경우 원(o)으로, 1에 속할 경우 +로 표기하였습니다.
확인을 위해 plt을 생성해 주고, vis_data함수를 거쳐 plt.show()로 시각화 해줍니다.
위의 코드까지 실행시키면 아래와 같은 결과를 얻습니다.(데이터는 실행시마다 다르게 생성되기 때문에, 저와 그래프가 같지 않을 수도 있습니다.)
▶신경망 정의
이제 이번 포스팅의 핵심인 신경망을 정의해 주겠습니다.
class NeuralNetwork(torch.nn.Module):
def __init__(self, input_size, hidden_size):
super(NeuralNetwork, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.linear_1 = torch.nn.Linear(self.input_size, self.hidden_size)
self.relu = torch.nn.ReLU()
self.linear_2 = torch.nn.Linear(self.hidden_size, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, input_tensor):
linear1 = self.linear_1(input_tensor)
relu = self.relu(linear1)
linear2 = self.linear_2(relu)
output = self.sigmoid(linear2)
return output신경망의 이름은 NeuralNetwork이고, torch.nn.Module을 상속받는 파이썬 클래스로 정의해 줍니다.
nn.Module을 상속 받으면 파이토치 프레임 워크에 있는 각종 도구들을 쉽게 적용할 수 있습니다.
def init
init()()함수는 파이썬에서 객체가 갖는 속성값을 초기화 해주는 역할을 합니다. 객체가 생성될 때 자동으로 호출 됩니다. 또한 super()는 NeuralNetwork 클래스를 정의할 때 파이토치의 nn.Module 크랠스의 속성들을 가지고 초기화 됩니다.
또한 input_size는 신경망에 입력되는 데이터의 차원을, hidden_size는 신경망의 은닉층 크기를 결정합니다. 그리고 torch.nn.Linear는 행렬곱과 편향을 포함하는 연산을 지원하는 객체이고, torch.nn.ReLU, torch.nn.Sigmoid는 각 단계에서 수행할 활성 함수입니다.
def forward
forward함수는 init()함수에서 정의된 동작들을 차례로 실행하는 함수입니다.
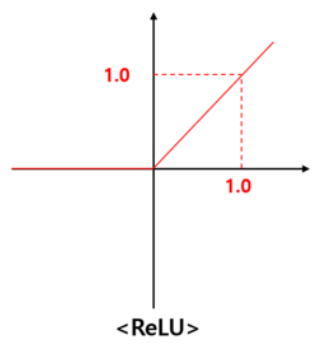
먼저 linear1는 입력 데이터 [input_size, hidden_size] 크기의 가중치를 행렬곱하고, 편향을 더하여 [1, hidden_size] 꼴의 텐서를 반환해줍니다. 그 다음 ReLU 활성 함수를 적용시킵니다. ReLU함수는 아래와 같이 입력 값이 0보다 작으면 0을 반환, 0보다 크면 입력값 그대로를 출력해 주는 함수입니다.
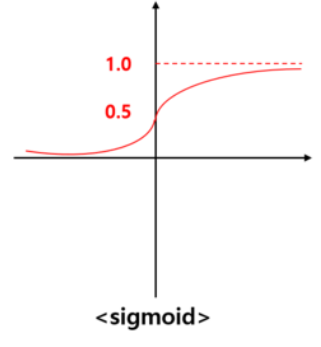
ReLU함수를 통과한 텐서는 다시 linear2를 거치게 됩니다. 이때 결과의 크기는 [1,1]이 됩니다. 마지막으로 텐서를 sigmoid 활성 함수에 입력합니다. 시그모이드 함수는 아래와 같이 입력 값을 0과 1사이의 값으로 변환합니다.
▶학습
이제 정의한 모델을 초기화 시키고 학습시켜보겠습니다.
model = NeuralNetwork(2, 5)
learning_rate = 0.03
criterion = torch.nn.BCELoss()
epochs = 10000
optimizer = torch.optim.SGD(model.parameters(), lr = learning_rate)
model.eval()
test_loss_before = criterion(model(x_test).squeeze(), y_test)
print('Before Training, test loss is {}'.format(test_loss_before.item()))
for epoch in range(epochs):
model.train()
optimizer.zero_grad()
train_output = model(x_train)
train_loss = criterion(train_output.squeeze(), y_train)
if epoch%100 == 0:
print('Train loss at {} is {}'.format(epoch, train_loss.item()))
train_loss.backward()
optimizer.step()
model.eval()
test_loss_before = criterion(torch.squeeze(model(x_test)),y_test)
print('After Training, test loss is {}'.format(test_loss_before.item()))먼저 신경망 객체 model을 생성하고, 학습을 설정하고, 오차 함수를 설정해 줍니다. 여기서 이진 교차 엔트로피인 BCELoss함수를 사용합니다.(Binary Cross Entropy Loss) 또한 최적화 알고리즘으로는 경사하강법(SGD)를 설정하였습니다.
설정이 끝나면 epoch의 크기만큼 학습을 하고, 모델의 평가를 합니다.
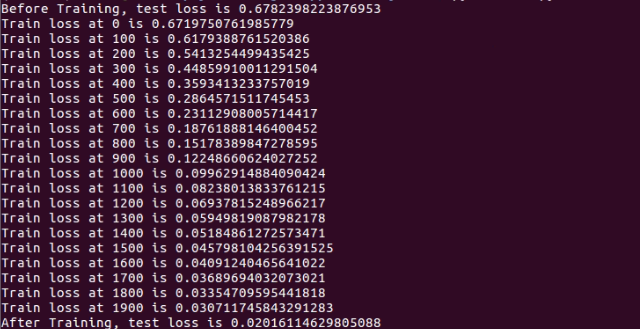
손실값이 점점 줄어드는 것을 확인할 수 있습니다.
▶저장 및 로드
지금까지 학습한 신경망의 웨이트들을 저장하려면 다음과 같이 하시면 됩니다.
## save
torch.save(model.state_dict(), './model.pt')
## load
new_model = NeuralNetwork(2,5)
new_model.load_state_dict(torch.load('./model.pt'))
new_model.eval()저장은 torch.save함수를 사용해서 현재 모델의 가중치들인 model.state_dict()를 './model.pt'에 저장해줍니다. 또한 다시 로드를 할 때는, 새로운 모델을 정의해주고, 정의한 모델.load_state_dict함수를 사용하여 torch.load('로드할 가중치 파일')을 해주시면 됩니다.

