
이번 포스팅에서는 심층 신경망을 이용하여, 여러가지 그림들을 분류해보겠습니다.
먼저 신경망에 대한 설명은 여기를 참고해 주세요!
▶사용할 데이터 집합
이번 심층 신경망을 이용한 분류에서 사용할 데이터 집합은 바로 Fashion MNIST입니다. 기존의 MNIST라고 하면 0~9까지의 28x28픽셀 흑백 이미지로 구성된 데이터 집합이었습니다. Fashin MNIST는 기존과 동일하게 28x28크기를 가지며 총 70,000개의 흑백 이미지로 구성된 총 10가지 패션 카테고리가 존재하는 데이터 집합입니다.
아래의 예제 코드로 데이터 집합을 한번 살펴보도록 하겠습니다.
from torchvision import datasets, transforms, utils
from torch.utils import data
import matplotlib.pyplot as plt
import numpy as np
transform = transforms.Compose([transforms.ToTensor()])
trainset= datasets.FashionMNIST(root = './.data/', train = True, download = True, transform = transform)
testset= datasets.FashionMNIST(root = './.data/', train = False, download = True, transform = transform)
batch_size = 16
train_loader = data.DataLoader(dataset = trainset, batch_size = batch_size)
test_loader = data.DataLoader(dataset = testset, batch_size = batch_size)
dataiter = iter(train_loader)
images, labels = next(dataiter)
img = utils.make_grid(images, padding=0)
npimg = img.numpy()
plt.figure(figsize = (10,7))
plt.imshow(np.transpose(npimg,(1,2,0)))
plt.show()라이브러리 설명
-torch.utils.data : 데이터의 표준을 정의하고, 데이터 집합을 불러오고 자르고 섞는데 쓰는 모듈입니다. 파이토치 모델을 학습하기 위한 데이터 집합의 표준을 torch.utils.data.Dataset에 정의합니다. Dataset의 모듈을 상속하는 파생 클래스는 학습에 필요한 데이터를 로딩해주는 torch.utils.data.DataLoader 인스턴스의 입력으로 사용할 수 있습니다.
-torchvision.datasets : torch.utils.data.Dataset을 상속하는 이미지 데이터셋의 모음입니다. Fasion MNIST또한 여기에 들어있습니다.
-torchvision.transforms : 이미지 데이터셋에 쓸 수 있는 여러가지 변환 필터를 담고 있는 모듈입니다. 예를 들어 텐서의 변환, 크기 조절, 밝기, 대비 등을 조절할 수 있습니다.
-torchvision.utils : 이미지 데이터를 저장하고 시각화하기 위한 모듈입니다.
먼저 transforms는 위에서 언급한것처럼 입력을 변환시켜주는 도구입니다. 위의 코드에서는 ToTensor()함수를 사용하여 입력 데이터를 텐서로 변환시켜줍니다. 또한 텐서로 바꿔주는 함수 외에, 크기를 조정해주는 Resize() 등 많은 함수가 존재하는데, 이를 Compose() 함수 안의 리스트로 정의를 해주면, 순서대로 변환이 이루어집니다.
또한 datasets.FasionMNIST를 사용하여 데이터를 다운받습니다. 여기서 root에 경로를 확인한 뒤, 데이터가 없다면 download를 하게 됩니다. 이때 transform자리에 위에서 정의한 transform함수를 적어주면, 로드한 데이터에 바로 ToTensor()를 적용한 결과를 trainset에 받을 수 있습니다.
data.DataLoader는 데이터를 batch_size만큼 쪼개는 역할을 합니다. 여기서는 batch_size를 16으로 설정했습니다. train_loader에는 train data를 넣어주고, test_loader에는 test data를 넣어줍니다.
-iter() : DataLoader타입을 반복문에서 이용할 수 있게 만들어 주는 함수
-next() : 배치 1개를 가져오는 함수
-utils.make_grid(image, padding) : 여러 이미지를 모아 하나의 이미지로 만드는 함수
위의 코드를 출력해 보면 아래와 같은 데이터들을 확인할 수 있습니다.
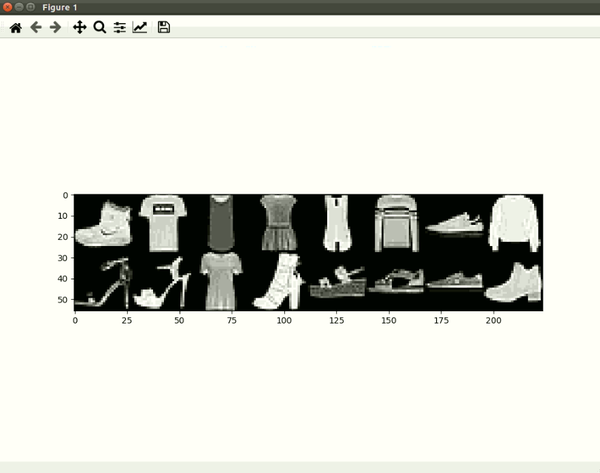
Fashion MNIST
이제 심층 신경망을 이용해서 위의 데이터를 분류해 보겠습니다.
▶라이브러리 임포트
사용할 라이브러리는 아래와 같습니다.
import torch
from torchvision import datasets, transforms, utils
from torch.utils import data
#import matplotlib.pyplot as plt
import numpy as np
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F▶데이터셋 준비
이는 데이터 소개 파트에서 했던것과 동일합니다.
transform = transforms.Compose([transforms.ToTensor()])
trainset= datasets.FashionMNIST(root = './.data/', train = True, download = True, transform = transform)
testset= datasets.FashionMNIST(root = './.data/', train = False, download = True, transform = transform)
batch_size = 16
train_loader = data.DataLoader(dataset = trainset, batch_size = batch_size)
test_loader = data.DataLoader(dataset = testset, batch_size = batch_size)▶모델 설계
이제 DNN의 설계 부분입니다.
class DeepNeuralNetwork(nn.Module):
def __init__(self):
super(DeepNeuralNetwork,self).__init__()
self.fc1 = nn.Linear(784,256)
self.fc2 = nn.Linear(256,128)
self.fc3 = nn.Linear(128,10)
def forward(self,input_data):
x = input_data.view(-1, 784)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x먼저 입력을 받는 fc1은 784크기의 데이터에 가중치를 행렬곱하고, 편향을 더해 256크기의 데이터를 출력합니다. fc2는 256을 받아 fc1과 같은 과정을 거쳐 128크기의 데이터를 출력하고, fc3은 128의 데이터를 입력 받아 위와 같은 과정을 거쳐 10크기의 데이터를 출력할 것 입니다. 여기서 10은 각 클래스를 의미하며, 10개중 가장 큰 클래스가 이 모델의 예측값이 됩니다.
▶GPU설정과 학습
이번에는 GPU의 설정에 대해서도 같이 다루겠습니다.
USE_CUDA = torch.cuda.is_available()
DEVICE = torch.device("cuda" if USE_CUDA else "cpu")
EPOCHS = 30
BATCH_SIZE = 64
model = DeepNeuralNetwork().to(DEVICE)
optimizer = optimizer = optim.SGD(model.parameters(),lr=0.01)먼저 torch.cuda.is_available()함수는 현재 GPU가 사용 가능한지 확인하는 함수이며, torch.device현재 사용할 장치 설정입니다. cuda는 gpu를 사용하는 설정 cpu는 사용하지 않는 설정입니다. 이는 모델을 정의한 뒤에 .to(DEVICE)를 통해서 CUDA를 사용할 경우 GPU로, 아닐 경우 CPU로 보냅니다. 최적화 알고리즘은 확률적 경사하강법인 SGD를 사용합니다.
def train(model, train_loader, optimizer):
model.train()
for batch_index, (data, target) in enumerate(train_loader):
data, target = data.to(DEVICE), target.to(DEVICE)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
loss.backward()
optimizer.step()
def evaluate(model, test_loader):
model.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
output = model(data)
test_loss += F.cross_entropy(output, target, reduction='sum').item()
pred = output.max(1,keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
test_accuracy = 100 * correct / len(test_loader.dataset)
return test_loss, test_accuracy
for epoch in range(1,EPOCHS + 1):
train(model, train_loader, optimizer)
test_loss, test_accuracy = evaluate(model,test_loader)
print('[{}] Test Loss : {:.4f}, Accuracy : {:.2f}%'.format(epoch, test_loss, test_accuracy))
