
논문
https://arxiv.org/pdf/1706.03762.pdf
Github
https://github.com/jadore801120/attention-is-all-you-need-pytorch
Attention is All You Need는 Transformer모델 즉, Self-Attention을 처음 제안하는 논문입니다. 현재 제안되는 최신 모델들은 대부분 Self-Attention을 기반으로 합니다. 자연어 분야를 뛰어 넘어, 멀티 모달 임베딩, 또는 이미지, 비디오, 그래프 등 다양하게 사용되고 있습니다.
등장 배경
Self-Attention모델의 등장 이전, 대부분의 자연어 처리(자연어 생성, 질문-응답, 자연어 번역 등)는 Encoder-Decoder 구조를 가지는 RNN, CNN 등의 모델로 구현되었습니다. 초기에는 RNN 모델만을 주로 이용하다가, Attention 메커니즘이 추가된 RNN계열의 모델을 이용하였습니다. 이 모델들은 어떠한 한계점이 있을까요?
▶RNN 계열의 모델
RNN의 작동 방식은 시계열 데이터 ti가 들어가면 각 hidden state값인 hi가 출력되고, 다음 셀로 전달됩니다. 이 방식을 잘 살펴보면, 이전 상태에 종속적이라는 것을 알 수 있죠. 즉, ti+1을 처리하기 위해서는 반드시 ti가 처리되어야 합니다. 때문에, 병렬 처리가 불가능 합니다. 따라서 속도가 느리다는 단점이 있습니다. 또한 encoder-decoder구조에서 encoder를 거쳐 나온 결과를 context vector라고 하는데, 이 벡터의 사이즈는 고정되어있습니다. 따라서 고정된 크기의 벡터에 모든 입력 정보를 압축하기 때문에, 정보의 손실이 발생할 수 있습니다.
▶RNN+Attention 계열의 모델
RNN 계열의 Encoder-Decoder모델의 문제점을 해결하고자 제안된 모델입니다. 간단히 말하면, decoder에서 출력할 때, 인코더의 결과값들을 한번 더 참고하여 출력하는 모델입니다. 즉, 하나의 context vector를 사용하여 전체를 출력하지 않고, 각 출력마다 encoder의 결과값을 한번 더 참고합니다. 따라서 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 조금 더 집중해서 볼 수 있습니다. 하지만 여전히 RNN계열의 모델을 사용하기 때문에, 속도가 느리다는 단점이 여전히 존재합니다.
▶Transformer의 등장
위의 한계점에 대응하여 새로운 모델인 Transformer가 등장하게 됩니다. 이 모델은 기존의 RNN 구조를 탈피한 self-attention이라는 새로운 attention 메커니즘을 제안합니다. RNN 구조의 가장 큰 문제였던, 순차적인 계산(병렬 처리 불가능)을 행렬곱을 사용하여 한번에 처리 할 수 있게 하였습니다. 따라서 이 한 번의 연산으로 모든 중요 정보들을 임베딩 할 수 있게 되었습니다. 정리하자면, Transofrmer는 기존의 encoder-decoder 구조는 그대로 유지하지만, RNN 구조를 탈피했기 때문에, 병렬처리가 가능하고, 이로 인해 시간이 단축되었습니다. 여기서 행렬을 이용하게 된다면, 입력 데이터의 순서가 섞일 수 있기 때문에, position encoding을 통하여 이를 해결하였습니다.
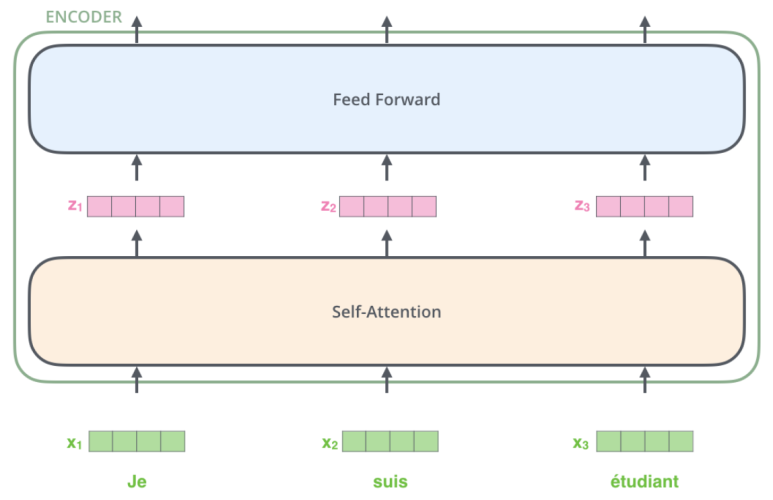
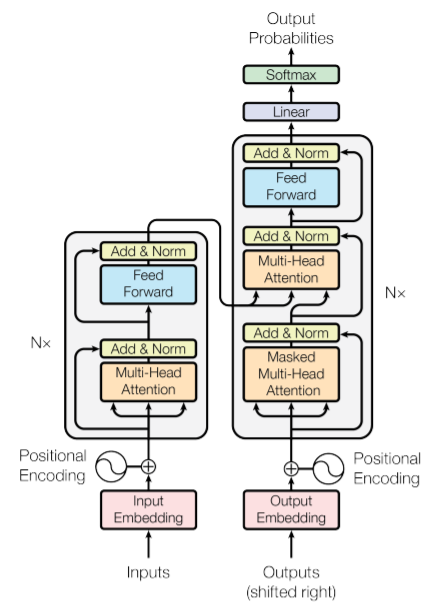
모델 구조
모델은 아래와 같이 encoder-decoder 구조를 가집니다.
모델은 크게 아래의 2가지 구조를 합한 것과 같습니다.
(1) self-attention
(2) position-wise feed forward network
encoder, decoder의 간략한 설명 이후에, 자세히 알아보도록 하겠습니다.
▶ Encoder
encoder는 위의 구조가 총 6개(N=6)로 쌓여있습니다. encoder 내에 크게 2 가지의 sub-layer가 존재합니다. 하나는 multi-head self-attention 메커니즘을 사용하는 layer, 그 다음은 position-wise fully connected feed-forward network입니다. 여기서는 residual connection을 이용하였고, 각 layer 이후에는 정규화를 시켰습니다. 따라서 각 sub-layer의 결과값은 LayerNorm(x+Sublayer(x))입니다. 최종 결과 dimension인 dmodel = 512입니다.
▶ Decoder
decoder 또한 위의 구조가 총 6개(N=6)로 쌓여있습니다. decoder 내에는 크게 3가지의 sub-layer가 존재합니다. 두 개는 encoder와 동일하고, 나머지 하나는 maksed-multi-head self-attention 메커니즘을 사용하는 layer인데, 여기서 masked를 이용하는 이유는 self-attention시 자신의 처리 이후 단어는 볼 수 없도록 masking시켜 self-attention이 되는 것을 막아줍니다. decoder는 encoder와 달리 출력 값을 순차적으로 생성해내야합니다. 따라서 현재까지 예측한 단어 이후의 단어들은 가려버립니다. 수학 문제집 푸는데 아직 풀지도 않은 문제 답은 보면 안되는 것 처럼요!
이제 앞서 언급한 모델 내의 각 구조에 대해서 설명하겠습니다.
(1) self-attention
self-attention을 이해하기 전, scaled dot-product attention에 대해서 먼저 살펴보겠습니다.
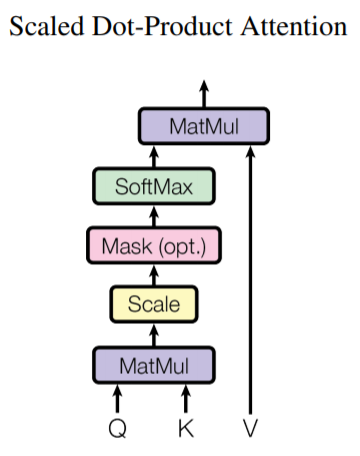
먼저 Query, Key, Value를 함께 입력받고, Query와 Key를 이용하여 attention weight를 구합니다. 이후, Value와 곱하여 attention이 가해진 값을 얻게됩니다. 이 과정을 수식으로 나타내면 아래와 같습니다. dk는 dimension으로 dk = Q = K 이고, dv = V입니다.
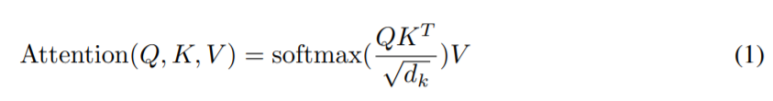
여기서 sqrt(dk)로 나눠주는 이유는, dk가 커질 경우, dot product의 결과는 엄청 커지게 되기 때문에 이를 방지하고자 나눠주었다고 합니다.
여기서! 그럼 self-attention이란 바로 위의 수식에서 Query, Key, Value의 출처가 같은 것을 뜻합니다. 즉, 기존 attention 같은 경우, Query는 구하고자 하는 값, Key, Value는 구해지고자 하는 값을 의미했습니다. 구체적으로 말하자면, RNN + attention 구조에서 Query는 decoder 내의 하나의 셀 값을 뜻하고, Key, Value는 encoder의 모든 시점 셀의 값을 뜻합니다.
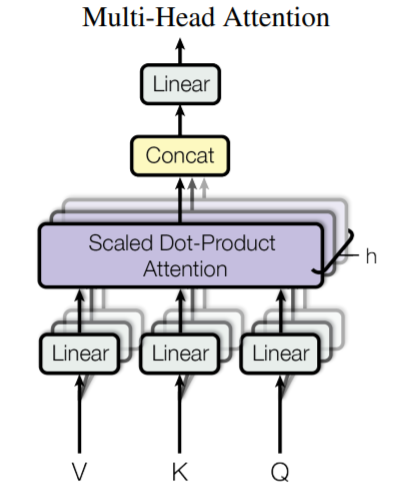
※그럼 multi-head self-attention은 뭔가요?
multi-head self-attention은 위의 scaled dot-product attention을 병렬 처리하기 위해 여러개 사용한 것을 뜻합니다. 기존의 scaled dot-product attention을 동시 수행하기 위해서, 기존의 512차원의 각 단어 벡터를 8로 나누어 64차원의 Query, Key, Value 벡터로 바꾸어 attention을 수행합니다. 여기서 8은 헤드를 뜻합니다! 헤드가 8개 이기 때문에, 기존 처리하는 벡터 차원을 유지하기 위해 8을 나눠주었습니다.

수식을 나타내면 위와 같습니다. 하나의 MultiHead는 작은 head(dot-product attention)들의 합입니다. WiQ, WiK, WiV는 위에서 언급한 것 처럼, 기존의 512차원의 입력 단어 벡터를 64차원으로 나눠주기 위한 가중치 행렬입니다.
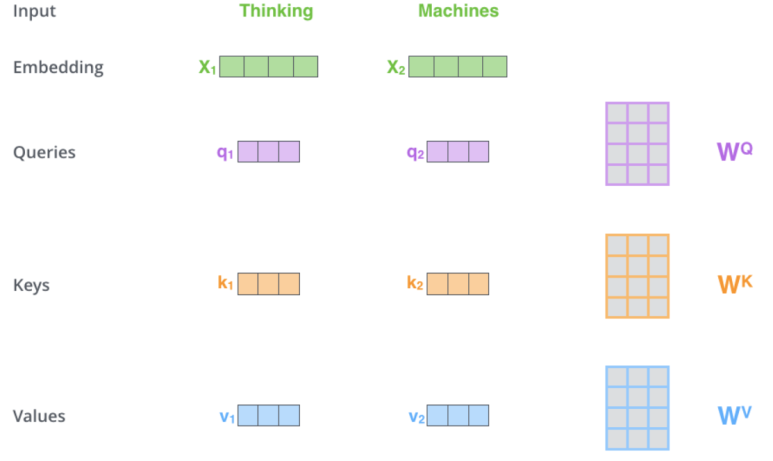
위에 그림 예를 보시면, 4차원의 단어 벡터가 들어오면 각각의 4x3의 가중치 행렬과 곱해져 결국 Query, Key, Value는 3차원의 벡터가 됩니다. 이렇게 벡터 크기를 조정해 주는 이유는, 초반에 언급한 것 처럼 병렬처리를 하기 위함입니다.
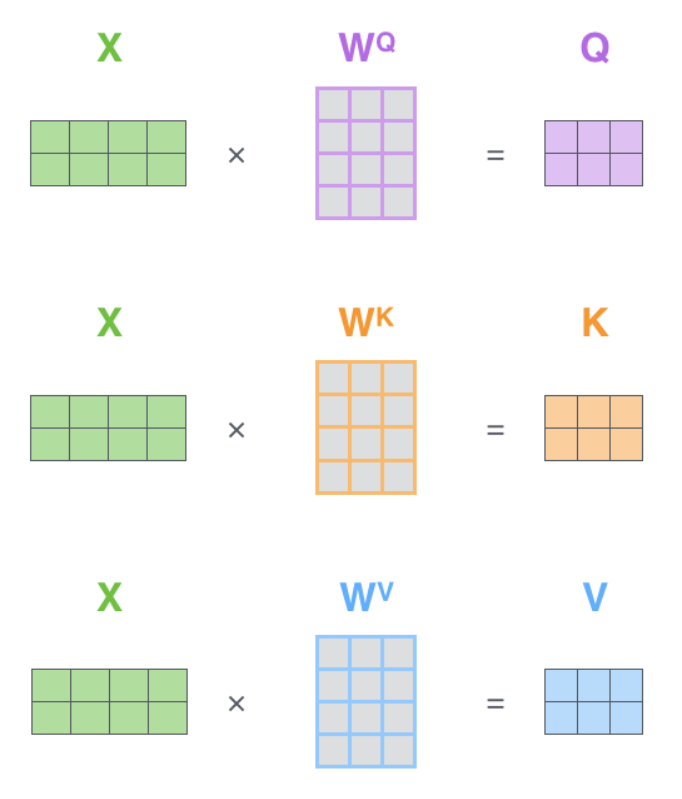
위의 그림은 병렬처리 하는 것을 보여주는 예입니다. <multi-head self-attention 1> 그림에서는 단어 1개씩 떨어져 있었지면, 위 그림의 X를 보시면 단어가 2개 붙어있는 것을 확인할 수 있죠. 이렇게 병렬처리를 합니다. 다른 예를 한번 더 살펴보겠습니다.
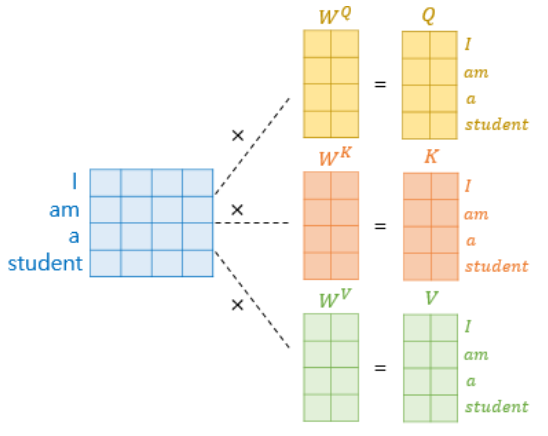
I, am, a, student 각각의 단어가 하나의 행렬을 이루고, 가중치 행렬과 곱해져서 최종 Query, Key, Value의 행렬이 완성됩니다. 그럼 여기서 헤드를 추가해 볼까요?
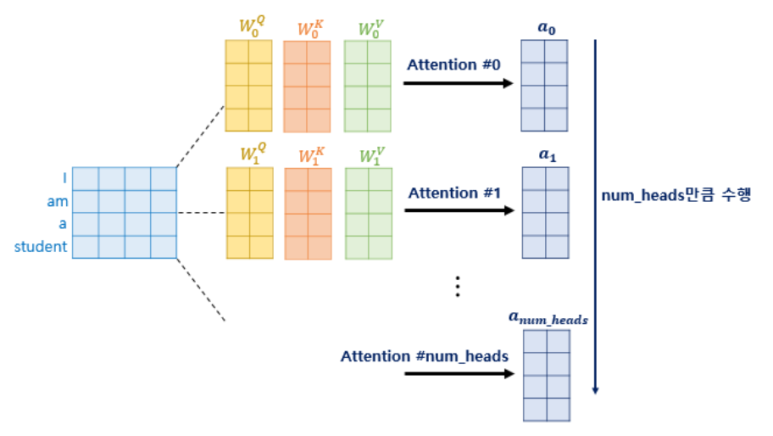
위의 그림을 보시면 헤드가 여러개 추가된 것을 확인 할 수 있습니다. 이 논문에서는 한 번 attention을 하는 것 보다, 여러 번의 attention을 병렬로 수행하는 것이 더 효과적이라고 판단하였기 때문에, 여러 개의 헤드를 두고 attention을 수행합니다. 따라서 각 각의 헤드값은 다릅니다. 그 말은 즉, WiQ, WiK, WiV 값도 모두 다르다는 것을 의미합니다.
※attention을 여러번 수행하는 것이 가지는 의미는 뭔가요?
attention을 여러 번 수행한다는 것은, 다양한 시각으로 정보를 수집한다는 것을 의미합니다. 당연히 한 가지 시각을 가지고 attention을 수행하는 것 보다 더 정확하고 의미있을 것입니다.
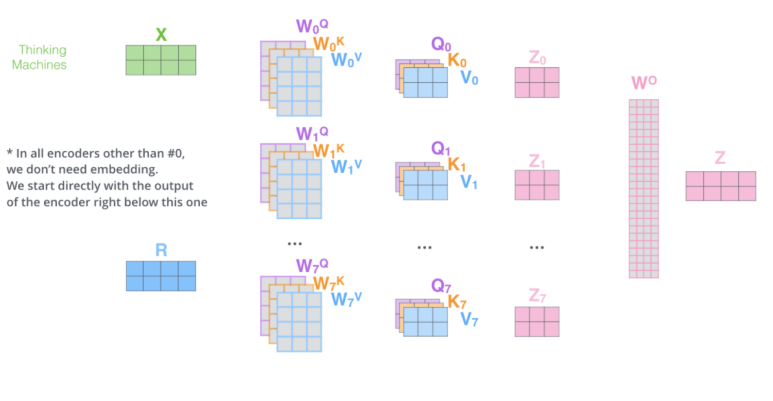
각 head의 attention이 끝나면, 모든 결과값들은 하나의 벡터로 concatenate됩니다. 즉, Z0~Z7은 하나의 벡터로 concatenate되고, 가중치 행렬인 WO와 곱해져, 벡터 사이즈를 조정해줍니다.
(2) position-wise feed forward network
논문에서는 fully connected feed forward layer가 아닌 kernel size가 1인 convolutional layer라고 소개하고있습니다. 결국 연산한 것을 보면 fully connected와 별 차이는 없겠지만요. 수식은 아래와 같습니다.
먼저 linear transformation인 xW1+b1를 지나고, 활성함수 ReLU를 거칩니다. ReLU는 max()를 뜻합니다. 마지막으로 결과값에 다시 한번 linear transformation을 적용해줍니다. 이를 그림으로 나타내면 아래와 같습니다.
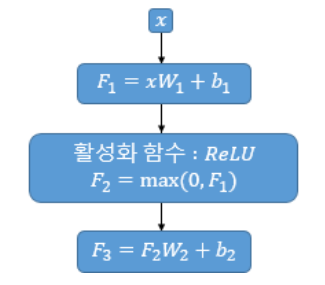
여기서! 파라미터 W, b는 모든 단어(position)마다 같은 값을 사용합니다. 즉, 하나의 파라미터로 모든 단어들을 계산합니다. 이때, 같은 인코더 내에서는 같은 파라미터를 사용하지만, 인코더가 달라진다면 다른 파라미터 값을 갖습니다. 즉 첫번째 인코더, 두번째 인코더 내에서는 각각 같은 파라미터를 사용하지만, 첫번째 인코더와 두번째 인코더의 파라미터는 같지 않습니다. 이때 입력 차원인 dmodel은 512이고, 출력 차원은 2048입니다.
※이 과정을 왜하나요?
RNN, CNN계열의 모델을 보시면 신경망을 통해 각 단어의 정보를 출력하죠. 이 과정 또한 같은 의미를 가집니다. attention을 통해 충분히 단어 간의 의미 교환을 했기 때문에 kernel size는 1로 설정하였습니다. (kernel size를 1로 설정하여도 문장 전체의 정보를 추출할 수 있습니다.)
학습 과정
이제 전체 학습 과정을 한번 살펴보겠습니다.
(1) Positional Encoding
Transformer는 기존 RNN방식과는 다르게 모든 입력을 순차적으로 주는 것이 아닌, 하나의 매트릭스로 줍니다. 따라서 순서가 뒤죽박죽이 될 수 있죠. 이를 방지하기 위하여 Transformer에서는 positional encoding을 합니다.
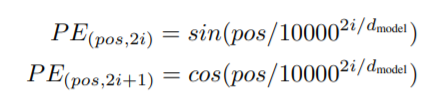
각 position에 대하여 위와 같은 수식을 사용합니다. position encoding된 값은 초기 임베딩된 단어 벡터와 함께 합산하여 초기 입력으로 사용됩니다.
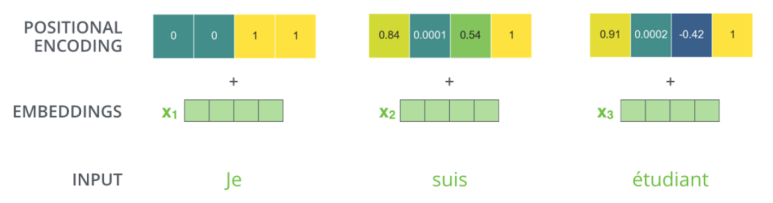
positional encoding된 벡터 크기와 embedding vector크기가 같기 때문에, 더해질 수 있습니다.
(2) Encoder
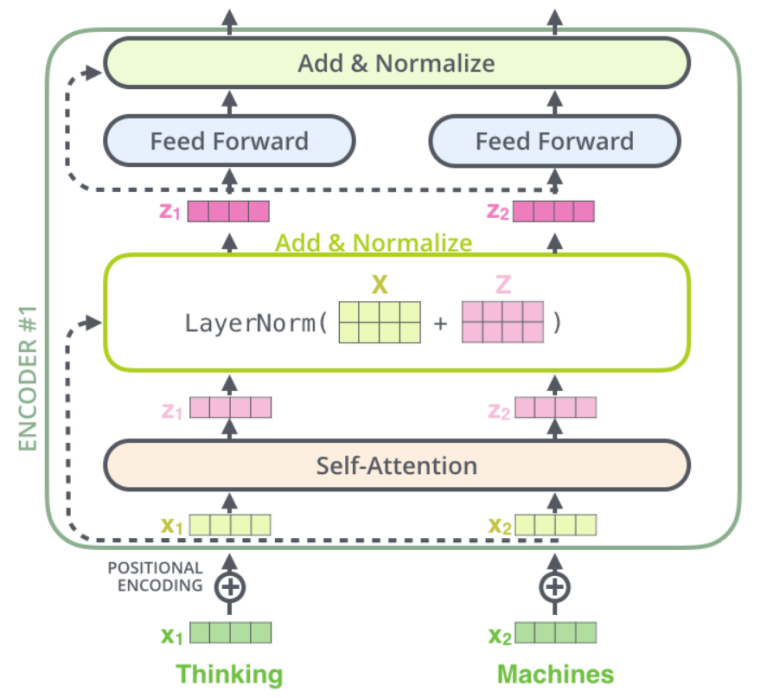
초기 임베딩된 단어들이 인코더 내로 들어오면,
① self-attention에 의해 attention이 가해집니다.
② 정규화 단계를 수행합니다. 이때, residual이 이용됩니다.
③ feed forward 과정을 거칩니다.
④ 정규화 단계를 수행합니다. 이때, residual이 이용됩니다.
이 과정을 총 6번 반복합니다.
(3) Decoder
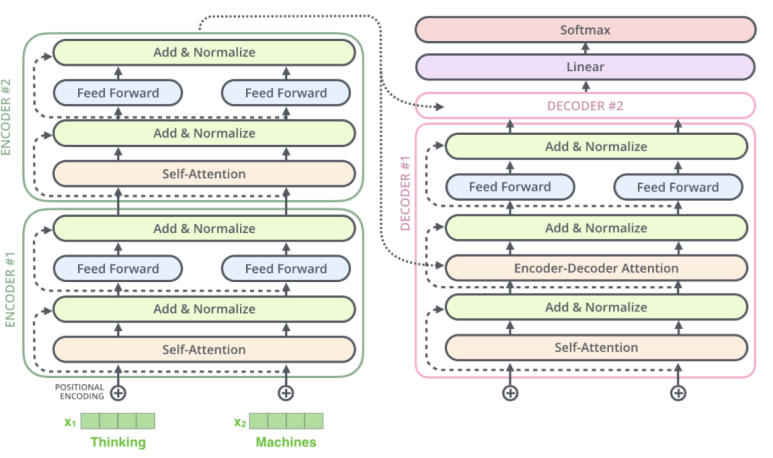
decoder는 encoder의 결과값을 받아 단어 예측을 시작하게 됩니다.
① 초기 토큰을 masked self-attention과정을 거칩니다.
② 정규화 단계를 수행합니다. 이때, residual이 이용됩니다.
③ 입력받은 encoder의 결과값과 함께 encoder-decoder attention을 거칩니다.
※ encoder-decoder attention이 뭐예요?
query는 decoder에서, key, value는 encoder에서 추출하여 self-attention을 가하는 방법입니다.
④ 정규화 단계를 수행합니다. 이때, residual이 이용됩니다.
⑤ feed forward 과정을 거칩니다.
⑥ 정규화 단계를 수행합니다. 이때, residual이 이용됩니다.
이 과정을 총 6번 반복합니다.
이후 fc layer와 softmax를 통해 단어를 예측합니다.
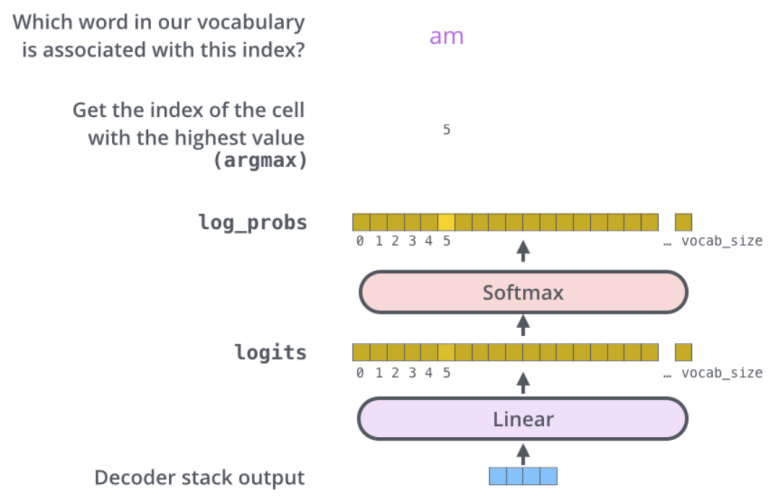
전체 과정 애니메이션을 보시려면 여기를 클릭해주세요.
결론
기존의 RNN 계열의 모델을 탈피하고자 병렬 처리가 가능한 Transformer가 제안되었습니다.
Transformer는 병렬처리가 가능하기 때문에, 빠르고 정확하게 data를 처리할 수 있습니다.
