
논문
https://www.cs.ubc.ca/~amuham01/LING530/papers/radford2018improving.pdf
Github
https://github.com/openai/finetune-transformer-lm
자연어 처리 분야에서 BERT와 함께 뛰어난 성능으로 주목받고 있는 모델입니다. 현재는 GPT-3까지 출시가 되었는데, GPT-4가 출시될거라는 말이 나왔죠(기사링크). 오늘은 GPT-1을 알아보도록 하겠습니다.
등장 배경
현재 라벨링 되어있지 않은 텍스트 데이터는 굉장히 많은 반면, 라벨링된 데이터는 적습니다. 따라서 많은 데이터로 학습하기 위하여 비지도 학습(unsupervised learning)으로 학습 할 수 있는 모델이 필요해졌습니다. 따라서 GPT-1이 제안되었습니다.
하지만, 라벨링 되지 않은 데이터를 사용하는 것은 다음과 같은 문제를 가지고있습니다.
(1) 어떤 최적화 목적함수(optimization objective)가 전이학습에 효과적인 text representation을 학습하는데 효과적인지 알 수 없습니다.
(2) 학습된 text representation을 다른 task로 전이하는데 가장 효과적인 방법이 정해지지 않았습니다.
따라서 GPT-1은 아래와 같은 방법으로 사전학습을 진행하였습니다.
(1) 사전 학습(pre-train)을 위해 원본 텍스트를 학습 할 때는 언어 모델링 목적함수를 이용합니다. 이후, fine tuning시에는 주어진 task에 맞는 목적함수를 이용합니다.
(2) Transformer의 Decoder구조를 이용합니다.
모델 구조
모델 구조는 Transformer의 decoder와 동일합니다. 구조에 대한 설명은 Transformer를 참고해 주시면 되겠습니다.
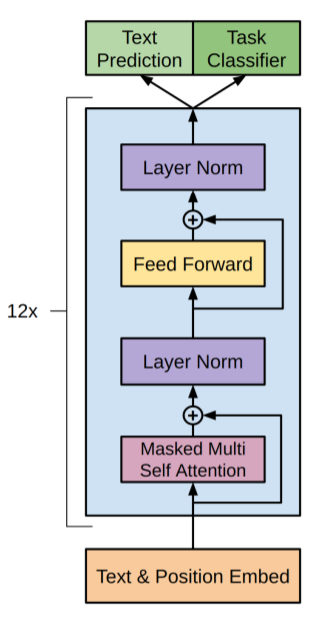
사전 학습(Unsupervised Learning으로 학습)
쉽게 말하자면! 입력받은 단어의 다음 단어를 예측하는 방법으로 학습합니다.
앞에서 말씀드렸다싶이, 목적함수로는 우도를 최대화하도록 표준 언어 모델링 목적 함수를 이용합니다. 라벨링 되지 않은 말뭉치(corpus)는 다음과 같이 정의됩니다.
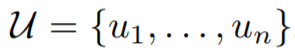
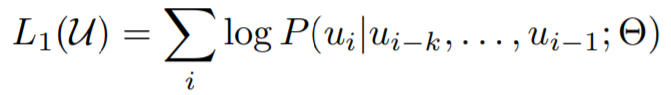
k는 context window이고, 조건부 확률 P는 학습 파라미터가 Θ인 신경망을 사용하여 모델링됩니다. 학습 파라미터는 SGD에 의해 학습됩니다.
학습 과정은 아래와 같습니다.
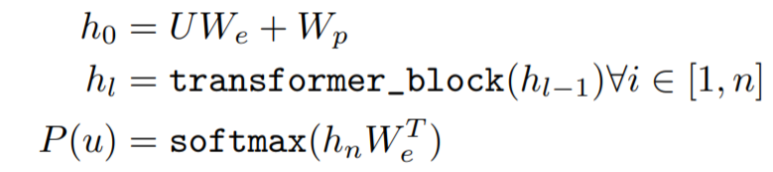
p와 We는 각각 position matrix과 embedding matrix를 뜻합니다.여기서 U = (u_k, ... u_1)인 토큰의 각 context vector입니다.
미세 조정(Supervised Learning으로 학습)
위의 과정을 통해 모든 사전 학습이 끝나면, 목표에 맞춰서 parameter를 미세조정 하면 됩니다. 예를 들어서 분류 데이터셋인 C가 있고, 입력은 token x1, ..., xm이고, 라벨이 y라면, 모델에서 최종 예측된 hlm을, softmax를 통해 최종 예측을 합니다.
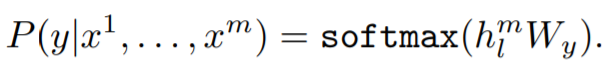
여기서 이용되는 목적 함수는 아래와 같습니다.
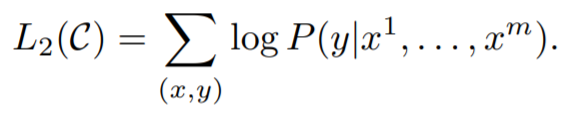
미세 조정에 대한 보조 목적 함수로 언어를 모델링 하는것은, 감독 학습 모델의 일반화를 개선하고, 수렴을 가속화 함으로써 학습에 도움이 됩니다. 구체적으로, 아래의 목적 함수를 최적화 합니다.
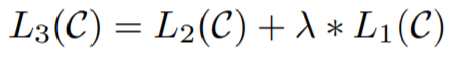
미세 조정 단계에서 추가된 학습 파라미터는 Wy와 delimiter token을 위한 embedding입니다.
TASK 처리
사전 학습시킨 모델을 다양한 task에 적용할 수 있도록 약간의 수정이 필요합니다. 여기서 문장의 시작과 끝을 알리는 토큰을 추가하여 입력에 포함합니다. 시작 토큰은 < s >이고, 종료 토큰은 < e >입니다.
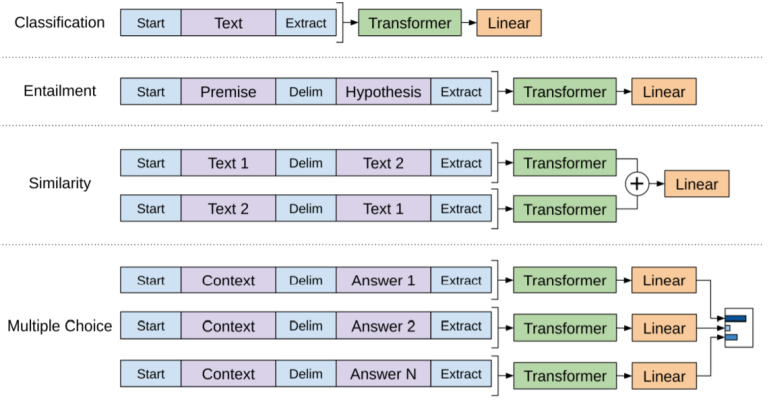
(1) Textual entailment
텍스트 간의 방향 관계를 예측하는 task입니다. 두 개의 이어진 문장이 모순인지, 가설인지 예측하는 문제입니다. 여기서는 두 문장을 입력받기 때문에 $문자를 이용하여 두 문장을 구분합니다.
(2) Similarity
유사성을 구하는 작업의 경우에는, 문장의 순서가 중요하지 않습니다. 따라서 입력시 각 문장을 독립적으로 처리하여, 최종 예측 계층 이전에 element-wise를 이용하여 hlm을 생성합니다.
(3) Question Answering ans Commonsense Reasoning
이 작업을 위해서는 context document인 z, 질문 q, 가능한 답변 세트 {ak}가 주어집니다. context document와 질문을 가능한 각 답변과 연결하고, [z;q;&;ak]와 같이 그 사이에 구분 기호 토큰을 추가하여, 독립적으로 처리한 뒤, 출력에 대한 분포를 생성합니다.
결과
왼쪽은 layer수에 따른 정확도, 오른쪽은 LM 사전 학습 업데이트의 기능으로 다양한 작업에 대해 제로샷 성능을 보여주는 그래프입니다.
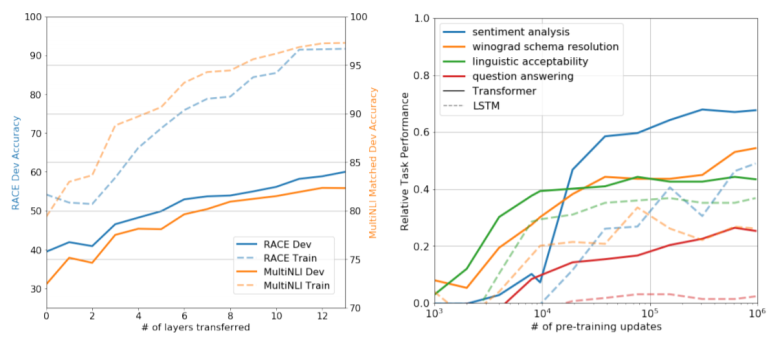
먼저 왼쪽 그래프를 보시면, layer가 12개일 때까지 성능 향상을 보이다가, 12가 된 시점부터 거의 그대로 유지하는 것을 알 수 있습니다. 또한 오른쪽 그래프에서는 기존 LSTM기반의 모델보다 모든 Task에서 더 효율적인 학습을 하는 것을 알 수 있습니다.
아래는 각 Task에 대한 성능입니다.
(1) Natural Language Inference tasks Results
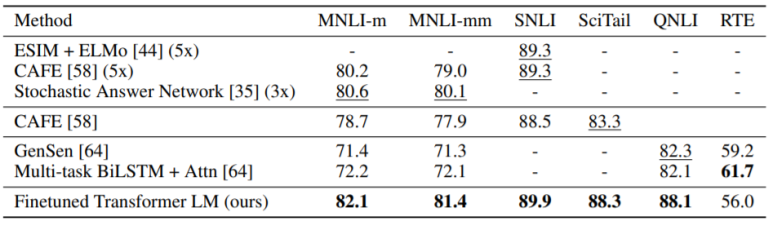
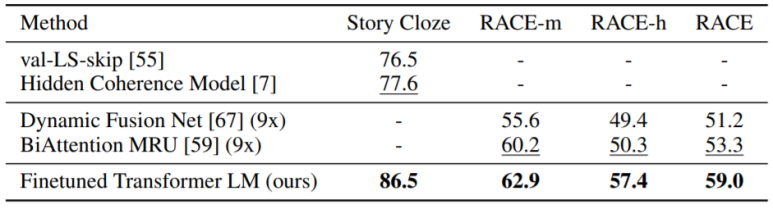
(2) Question Answering and Commonsense Reasoning Results
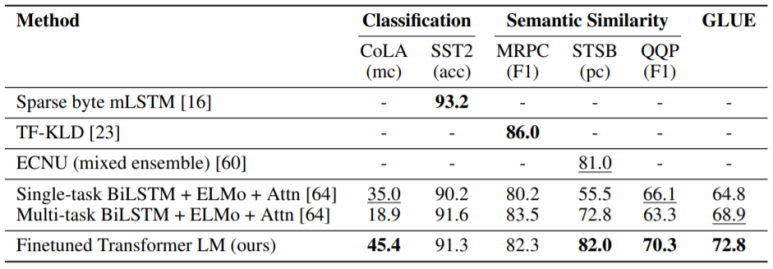
(3) Semantic similarity and Classification Results
결론
대규모의 라벨링 되지 않은 데이터로 학습하여 task-agnostic한 모델을 제안하였습니다. 이 모델은 미세 조정하여 원하는 task에 맞게 이용할 수 있습니다.
