
논문
https://arxiv.org/pdf/1802.05365.pdf
Github
https://github.com/HIT-SCIR/ELMoForManyLangs
등장 배경
"너에게 사과를 한다.", "사과 먹을래?" 에서 "사과"라는 단어는 같지만, 다른 의미를 가집니다. 기존의 Word2Vec나, Glove등의 모델은 "사과"는 같은 임베딩 값을 가집니다. 단어가 어떻게 사용되느냐에 따라 다르게 의미를 임베딩 하는 방법이 바로 ELMo가 사용한 방법인 Contextualized Word Embedding입니다. 즉, ELMo는 동음이의어에 대해 서로 다른 벡터로 임베딩 할 수 있게 문맥을 고려하여 임베딩합니다.
모델 구조
ELMo는 다층 구조인 양방향 LSTM를 이용합니다.
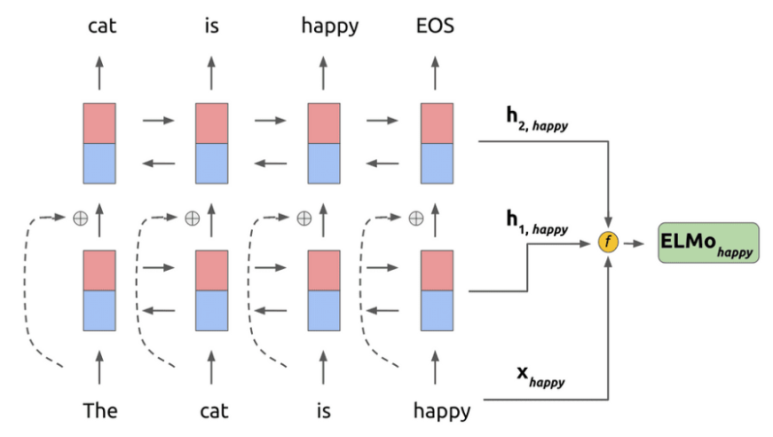
여기서 기존의 LSTM과 다른점이 있다면, 바로 residual connection을 사용한다는 점입니다. residual connection은 앞의 다른 포스팅에서도 언급했듯이, 상위 레이어들이 하위 레이어의 특징을 잃지 않고 활용할 수 있게 도와주고, 학습시 역전파를 통한 gradient vanishing 현상이 발생하지 않도록 도와줍니다줍니다.
사전 학습
ELMo도 pretrain을 이용하여 언어 모델링을 먼저 학습하여 사용합니다. 하지만 fine-tuning을 하지는 않고, feature-based approach를 이용합니다. 즉, 특정한 task를 수행하는 network에 사전 학습한 ELMo의 언어 표현을 추가적인 feature로 제공하고, 두 개의 network를 붙여서 사용합니다.
사전 학습은 GPT-1과 유사합니다. 즉, 단어를 입력했을때, 다음 단어를 예측하는 방식으로 학습합니다. 이를 언어 모델링(Language Modeling)이라고 하죠. 예를 들어 설명하면 "I love cat"이라는 단어를 각각 입력 받을 때, "I"를 입력받으면 "cat"을 예측하는 모델링 방법입니다. 이 방법은 별또의 라벨링이 필요하지 않기 때문에, 라벨링되지 않은 수많은 데이터도 학습할 수 있습니다.
순방향의 LSTM은 현재 단어를 입력받고, 다음 단어를 예측하도록 학습합니다. 역방향의 LSTM은 뒤에 오는 단어를 통해 앞에 있는 단어를 예측하도록 학습합니다. 여기서 단어를 모델에 넣어 줄 때, 최초 임베딩 레이어는 글자 임베딩(char embedding)을 사용한다고 합니다.
※ 글자 임베딩(char embedding)이 뭐예요?
워드 임베딩과는 다른 방법으로, 단어의 글자 단위로 계산하는 방법입니다. 이렇게 계산하면 각 글자마다 표현이 되기 때문에, 서브 단어의 정보를 참고하는 것처럼 문맥과 상관없이 단어의 연관성을 찾아낼 수 있습니다. 예를들어 love와 lovely의 연관성을 잘 찾아낼 수 있습니다. 또한 이 방법은 OOV문제에도 견고합니다.
※ OOV 문제는 또 뭐예요?
Out Of Vocabulary의 약자로 학습시에 일정 단위의 단어 집합을 생성하여 모델에 학습을 하게 되는데, 단어 집합에 없는 단어를 OOV 또는 UNK(Unknown Token)이라고 합니다. 모르는 단어로 인해 문제를 풀 수 없을 때 발생하는 문제가 바로 OOV문제입니다.
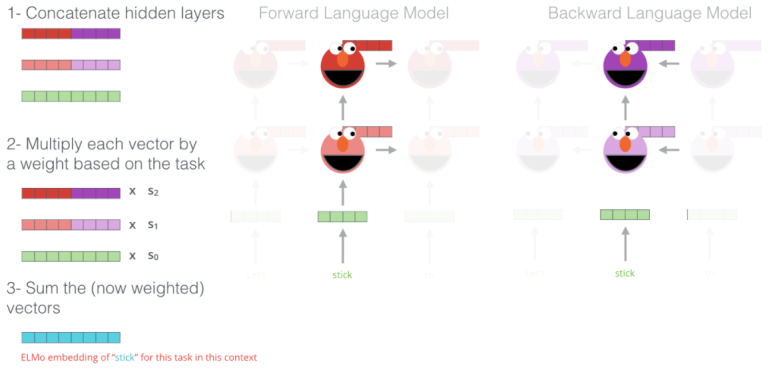
ELMo는 모든 레이어의 출력값을 활용해 임베딩을 만듭니다. 기존의 LSTM을 이용하는 방법인 최상위 계층의 임베딩 값만 사용을 하는것과 대조됩니다. 최상위 계층의 LSTM결과 값은 주로 문맥에 대한 정보를 잘 담고있고, 하위 레이어일수록 문법에 가까운 벡터를 출력한다고 합니다. 수식을 한번 살펴보겠습니다.
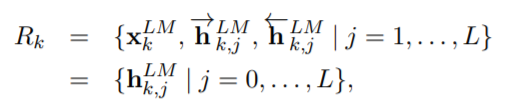
여기서 xkLM은 char embedding(CNN을 이용하였습니다.)된 토큰을 뜻하고, 그 뒤에 hk,jLM은 각각 순방향과 역방향의 각 계층, 단어별 임베딩된 벡터를 뜻합니다. 아래에 있는 hk,jLM는 각 계층에 있는 순방향 역방향의 결과를 합친것과 같습니다. 위의 그림에서 왼쪽을 자세히 보시면, 이 수식이 시각화 되어있습니다.

첫번째로 먼저 각 계층에서 나온 출력값을 합쳐줍니다. 그리고 각 벡터에 정규화된 가중치를 곱해줍니다. 이 가중치들은 학습하는동안 최적화됩니다. 마지막으로 벡터들을 더하여 하나의 임베딩 벡터를 만듭니다. 이는 문맥 정보를 많이 가지고 있는 상위 벡터와 문법 정보를 많이 가지고 있는 하위 벡터를 합치기 때문에 효율적인 임베딩이라고 할 수 있습니다.
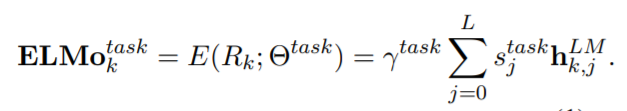
ELMo의 전체 식을 보자면 위와 같습니다. 여기서 stask는 각 계층을 반영하는 가중치입니다. 계층마다 분포가 다르기 때문에 layer normalization을 수행하여 더 정확하게 가중치를 반영할 수 있습니다. γtask는 전체 ELMo 의 결과 벡터를 스케일링 하기 위한 파라미터입니다. 즉, 여러 task에 적용할 때, 어느정도의 가중치로 ELMo벡터를 반영할지 결정하는 벡터입니다.
TASK 처리
그렇다면 다른 모델에 어떻게 ELMo를 적용할까요? ELMo는 미세조정을 하지 않고, 사전학습한 모델을 그대로 다른 모델과 결합하여 사용합니다. 아래와 같이 다른 임베딩 방법과 결합하여 하나의 벡터로 이용할 수 있습니다.
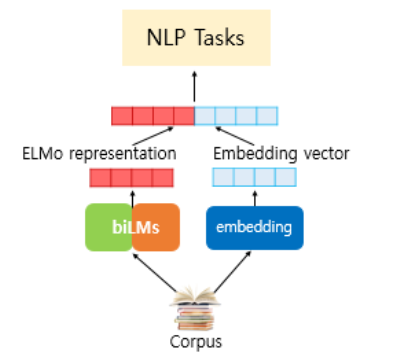
결과
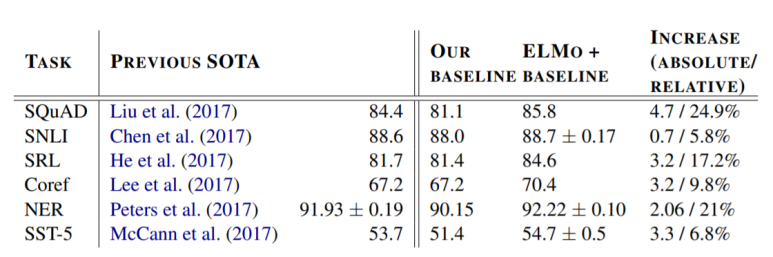
여러 Task에 적용해본 ELMo의 성능입니다. 거의 모든 면에서 성능 향상이 있는 것을 확인할 수 있습니다.
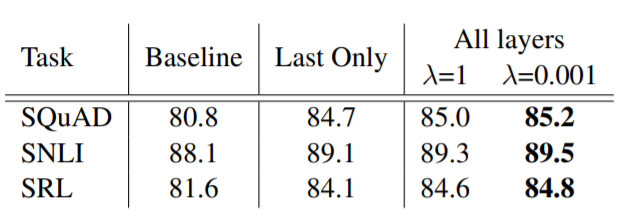
이번에는 마지막 계층의 결과만 이용하는지, 모든 계층 결과를 이용하는지에 따른 성능 결과표입니다. 엄청나게 큰 성능향상이 있는 것은 아니지만, 그래도 마지막 계층을 사용하는것보다는 더 효과적이라고 할 수 있습니다.
결론
기존 자연어 임베딩 방법은 단어가 어느 문맥에서 사용되는지에 상관없이 항상 같은 값으로 임베딩 되었었는데, ELMo는 Contextualized Word Embedding을 통해, 각 단어의 값을 다르게 임베딩하였습니다. 이로인해, 단어가 효과적으로 문맥을 고려하여 임베딩할 수 있게 되었습니다.
