
논문
https://arxiv.org/pdf/1810.04805.pdf
Github
https://github.com/google-research/bert
등장 배경
언어 모델의 사전 학습은 자연어 처리작업을 개선하는데 효과적인 것으로 나타났습니다. (GPT-1에서 이미 확인되었죠) 현재 나온 모델인 GPT-1은 왼쪽에서 오른쪽으로 이전 토큰만을 참고할 수 있는 단방향 구조를 사용합니다.(Transformer의 decoder를 사용하기 때문이죠.) 이 방법은 문장 수준의 작업에 적합하지 않고, 양방향 컨텍스트를 통합하는것이 중요한 질문,응답 문제에서 미세 조정을 할때, 좋지 않을 결과를 가지고 올 수 있습니다. 따라서 양방향 구조를 사용하는 BERT가 탄생합니다.
※ 양방향 단방향 구조가 뭔가요?
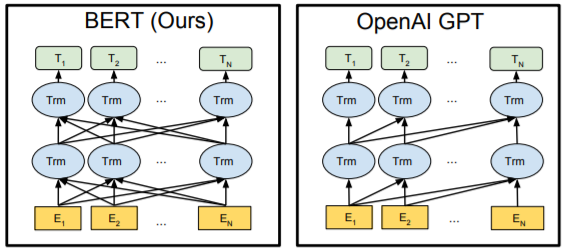
양방향 구조는 위 그림의 BERT처럼 이전단어 뿐 아니라 이후단어도 함께 참조할수 있는 것을 뜻합니다. 단방향 구조는 위 그림의 GPT처럼 이전 단어만 참조할 수 있고, 이후 단어에 대해서는 참조할 수 없는 것을 뜻합니다. 이렇게 되는 이유는, BERT같은 경우에는 Transformer의 Encoder부분을 사용합니다. 하지만 GPT같은 경우 Transformer의 Decoder를 사용하게 되는데요. Decoder는 문장을 생성하는 역할을 하죠. 따라서 생성한 이전 단어는 볼 수 있지만, 이후 단어는 볼 수 없게 masking을 했었습니다. 그렇기 때문에 양방향이 아닌 단방향이 되는것이죠!
※ 그래서 이로 인해 나타는 두 모델의 차이점은 뭔가요?
구조적으로 봤을때, BERT는 Transformer의 Encoder를 GPT는 Transformer에 Decoder를 사용했었죠. 먼저 Encoder, Decoder의 역할에 대해서 다시한번 생각해 봅시다. Encoder는 입력받은 문장을 얼마나 의미있게 임베딩 하느냐! 에 중점을 두고있죠. Decoder는 임베딩한 벡터를 이용하여 얼마나 결과를 잘 생성하느냐! 에 중점을 두고있습니다. 따라서, BERT는 문장의 의미 추출에, GPT는 문장 생성에 강점을 두고있습니다.
모델 구조
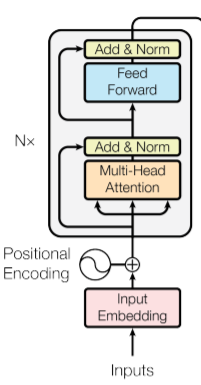
BERT의 구조는 논문에 따로 제시되어있지는 않고, Transformer의 Encoder부분을 생각하시면 됩니다. 구조를 자세히 알고싶은 분들은 Transformer글을 참고해 주세요.
BERT모델은 GPT처럼 대규모 데이터로 사전 학습을 한뒤, 미세 조정을 통해 다양한 Task에 이용됩니다.
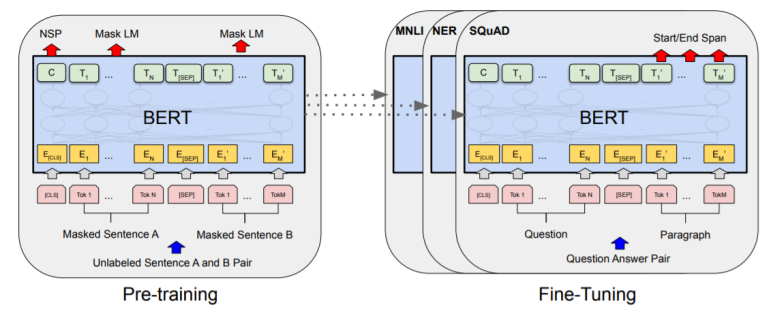
여기서 한가지! 기존 모델과 다른점이 있다면 바로 입력입니다. 기존 Transformer는 토큰이 임베딩된 값과 position 임베딩 값을 합쳐서 입력으로 넣어줬었죠. BERT는 Segment임베딩을 추가해주었습니다.
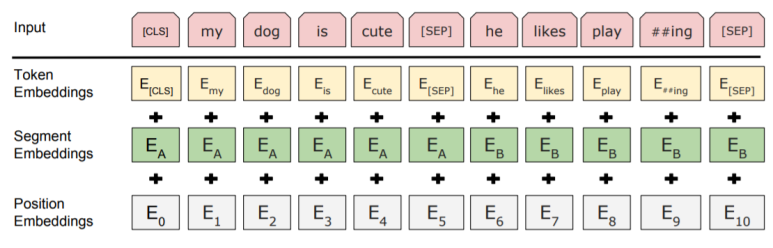
(1) Token Embedding
Transformer와 같이 토큰이 초기 임베딩되는 값입니다.
(2) Segment Embedding
BERT는 두개의 문장을 입력받게 되는데, 이는 문장 끝에 붙는 특수 토큰인 [SEP]으로 구분할 수 있습니다. 따라서 문장의 시작을 알리는 [CLS]토큰부터 첫 번째 [SEP]까지는 첫 번째 문장이기 때문에 EA로 표기가 되어있고, 두 번째 문장 시작부터 [SEP]까지는 EB로 표기 되어있습니다. Segment는 이렇게 각 토큰들이 어느 문장에 속하는지 알려줍니다. 두 문장의 최대 길이는 512입니다.
(3) Position Embeddings
기존 Transformer과 같이 위치값을 같이 넣어줍니다. 이때, position은 위치에 따라 차례로 값이 부여됩니다. 즉, 인덱스 값이라고 생각하시면 됩니다.
BERT는 위의 세 값을 통합하여 최종 Input을 생성합니다.
사전 학습
BERT에서는 총 2가지 방법으로 사전 학습을 시킵니다.
(1) Masked LM(MLM)
입력 문장 중 임의로 토큰을 특수 토큰인 [MASK]토큰으로 대체합니다. 이후 그 토큰이 원래 어떤 토큰이었는지 맞추는 학습을 진행합니다. 문장의 빈칸 채우기라고 보시면 됩니다. GPT에서는 생성된 단어의 다음 단어를 예측하는 방향으로 학습되었지만, BERT는 입력 문장 내에 빈칸을 만들어놓고, 그 빈칸에 어떤 단어가 들어가게 될지 예측하는 방향으로 학습합니다.

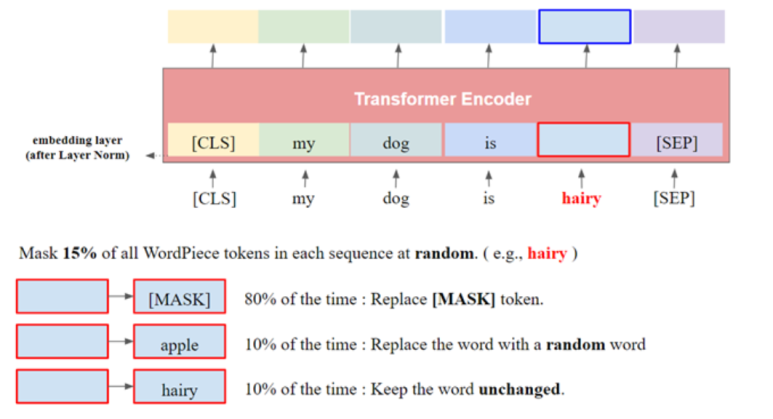
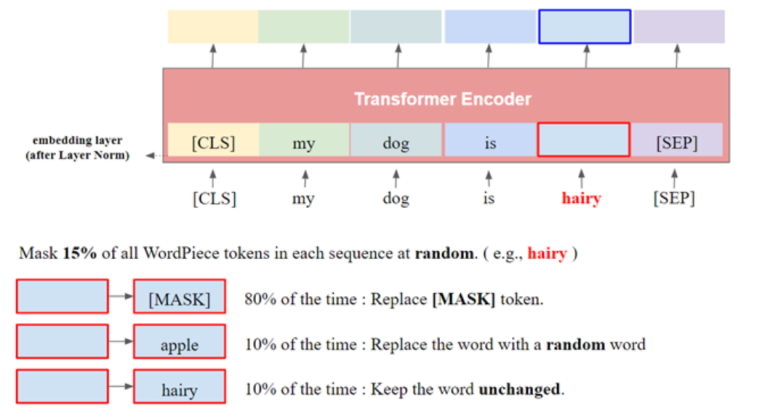
마스킹 되는 방법으로는, 입력받은 단어의 위치를 15%의 확률로 선택해줍니다. 선택된 단어는 80% 확률로 [MASK] 토큰으로 대체되고, 10%확률로 다른 단어로 대체되고, 10%확률로 그대로 있습니다.
(2) Next Sentence Prediction(NSP)
Question Answering, Natural Language Inference과 같은 task들은 두 문장의 관계를 이해해야 합니다. BERT는 이러한 task도 잘 해결하기 위해서, 입력받은 두 문장 사이의 연관성을 예측하는 방법도 학습합니다. 즉, 입력받은 두 문장 A,B가 순서가 맞는지 아닌지 예측을 합니다. (A문장 뒤에 B문장이 나오는것이 맞는지) 문장과 문장 사이에는 [SEP]토큰이 있기 때문에, 두 문장을 구분할 수 있고, 실제로 50%는 연속되는 문장, 50%는 관계 없는 문장으로 구성되어있습니다. 이 학습 방법을 통해 문맥과 순서를 학습할 수 있습니다. 데이터는 아래와 같이 생성됩니다.

미세 조정
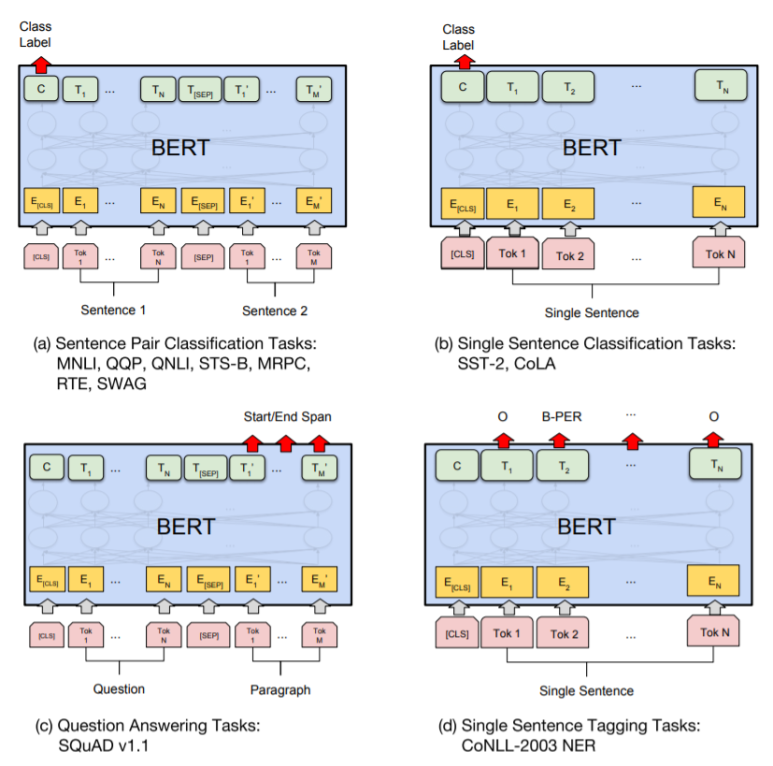
BERT는 총 4가지 유형의 데이터로 미세 조정을 할 수 있습니다.
(1) sentence pairs in paraphrasing
두 개의 문장을 입력받고 두 문장간의 관계를 구하는 문제
(2) hypothesis-premise pairs in entailment
한 문장을 입력하고, 문장의 종류를 분류하는 문제
(3) question-passage pairs in question answering
질문과 문단을 넣으면, 문단 내에 원하는 정답 위치의 시작, 끝을 구하는 문제
(4) a degenerate text-∅ pair in text classification or sequence tagging
입력 문장 토큰들의 개체명이나, 품사 등을 구하는 문제
GPT는 Similarity, Multiple Choice같은 경우에 Transformer모델을 독립적으로 따로따로 사용했는데, BERT는 하나의 입력으로 받아 처리합니다. GPT-1에서 각 Task별로 처리하는 것보다 훨씬 간단해 보이지 않나요?
결과
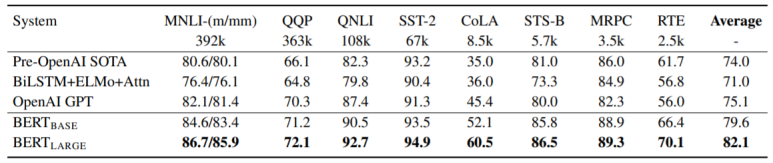
총 8개의 데이터셋으로 평가한 BERT의 성능입니다. BERTbase조차도 모든 데이터셋의 성능을 크게 앞질렀네요. (base와 large는 layer수의 차이입니다. base는 12게층, large는 24계층입니다)
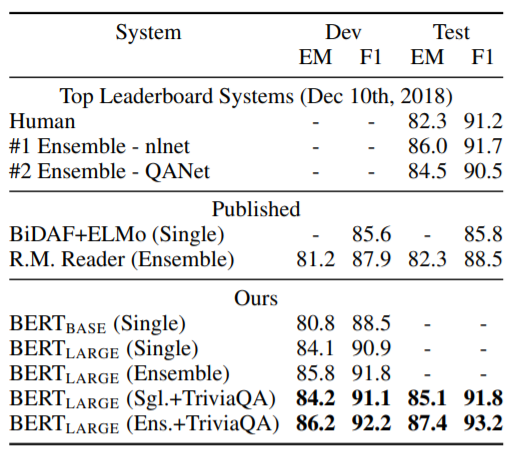
(1) SQuAD 1.0
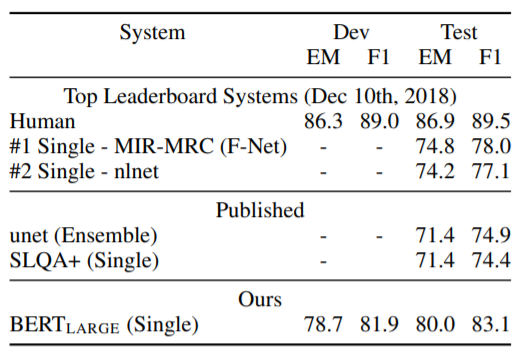
(2) SQuAD 2.0
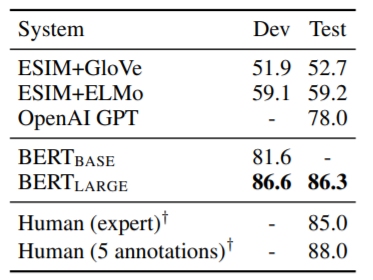
(3) SWAG
다음은 학습 방법의 비교입니다.
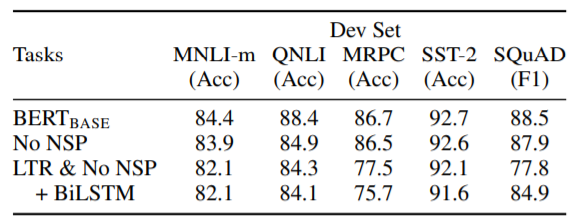
No NSP는 MLM만 적용한 방법이고, LTR & No NSP + BiLSTM은 MLM 대신 left-to-right방법(GPT)을 적용한 방법입니다. 결과를 보면, NSP만 제외하여도 전체적으로 성능이 낮아지는 것을 알 수 있습니다. 여기서 MLM까지 제외해버리면 성능이 확낮아져버립니다. 위의 결과로 BERT의 사전학습이 얼마나 중요한 역할을 하는지 알 수 있습니다.
다음 실험은 모델 크기에 대한 실험입니다.
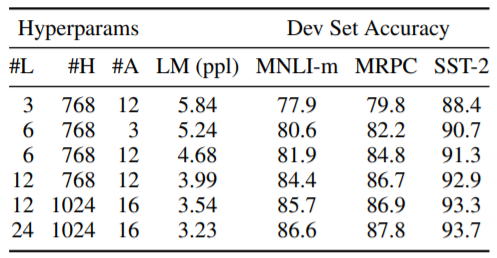
layer를 많이 쌓을수록 성능이 더 나아지는 것을 볼 수 있습니다.
결론
BERT는 기존 GPT와 달리 양방향 학습 방법을 사용하여 기존 task들의 성능을 크게 향상시켰습니다. 하지만 BERT는 전문적인 분야에 대한 글(의학, 화학 등)에서는 잘 적용이 되지 않는다고 합니다. 이를 위해서는 따로 데이터를 수집하고, 추가적인 학습을 해야할 것 같습니다.
