
▶자연어 처리의 문제들
앞의 포스팅에서 자연어 처리를 활용하는 아래와 같은 여러 문제들이 있다고 언급했습니다. 이번 포스팅에서는 그 문제들에 대해서 알아보겠습니다.
· 텍스트 분류
· 텍스트 유사도
· 텍스트 생성
· 기계 이해
(1) 텍스트 분류
텍스트 분류란 자연어 처리 기술을 활용해 특정 텍스트를 사람들이 정한 몇가지 범주(class) 중 어느 범주에 속하는지 분류하는 문제입니다. 2가지 문제일 경우 이진 분류 문제, 3가지 이상일 경우 다중 범주 분류 문제라고 합니다. 텍스트 분류의 예시로는 스팸 분류, 영화 리뷰의 감정 분류, 뉴스 기사 분류 등이 있습니다. 텍스트 분류는 크게 지도 학습을 통한 분류, 비지도 학습을 통한 분류가 있습니다.
· 지도 학습을 통한 분류
지도 학습을 통한 분류는 각 데이터에서 특징을 뽑아내 예측하고, 정답(라벨)과 맞는지 확인하면서 학습하는 방법입니다. 예로는 서포트 벡터 머신(SVM), 신경망 등이 있습니다.
· 비지도 학습을 통한 분류
비지도 학습을 통한 텍스트 분류는 특성을 찾아내서 적당한 범주를 만들어 각 데이터를 나누는 학습 방법입니다. 예로는 K-평균 군집화(K-Means), 계층적 군집화 등이 있습니다.
(2) 텍스트 유사도
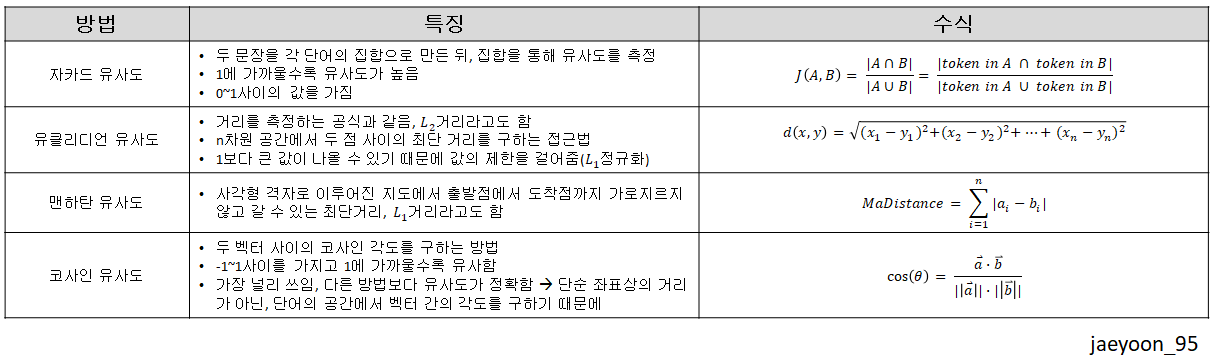
텍스트 유사도는 두개 이상의 텍스트가 얼마나 유사한지 표현하는 방식 중 하나입니다. 즉, 두 벡터로 표현된 두 개의 문장을 유사도 식을 통해 문장 간의 유사도를 측정하는 것 입니다. 딥러닝 기반의 유사도 측정 방법은 자카드 유사도(Jaccard Similarity), 유클리디언 유사도(Euclidean Similarity), 맨하탄 유사도(Manhattan Similarity), 코사인 유사도(Cosine Similarity) 등이 있습니다.
· 자카드 유사도(Jaccard Similarity)
두 문장을 각 단어의 집합으로 만든 뒤, 집합을 통해 유사도를 측정하는 방법입니다. 0~1사이의 값을 가지며, 1에 가까울수록 유사도가 높습니다. 수식으로 나타내면, 아래와 같습니다.
A, B는 아래의 문장으로 예를 들겠습니다.
A : {휴일, 인, 오늘, 도, 서쪽, 을, 중심, 으로, 폭염, 이, 이어졌는데요, 내일, 은, 반가운, 비, 소식, 있습니다.}
B : {폭염, 을, 피해서, 휴일, 에, 놀러왔다가, 갑작스런, 비, 로, 인해, 망연자실, 하고, 있습니다.}
보기 쉽게 벤다이어그램으로 나타내보겠습니다.
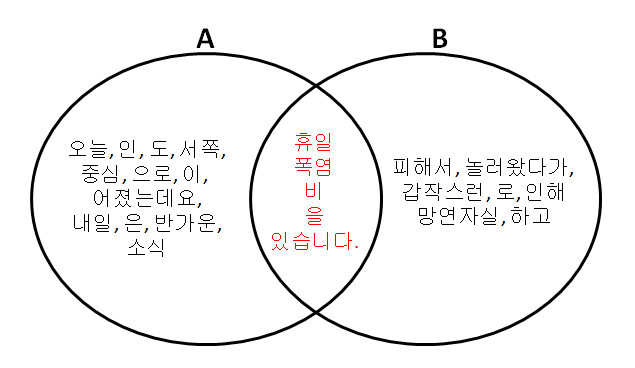
중복을 제외한 총 토큰은 24개입니다. 여기서 중복되는 토큰은 6개입니다. 식에 대입해서 풀어보면 24분의 6이 됩니다. 이를 소숫점으로 나타니면 약 0.25입니다. 따라서 이 두 문장의 유사도는 0.25입니다.
· 유클리디언 유사도(Euclidean Similarity)
유클리디언 유사도는 거리를 측정하는 공식과 같습니다(최단거리). 이를 L2거리라고도 합니다. 그렇기 때문에 결과는 1보다 큰 값이 나올 수 있습니다. 값을 0~1사이의 값으로 나타내기 위해, L1정규화를 사용합니다.
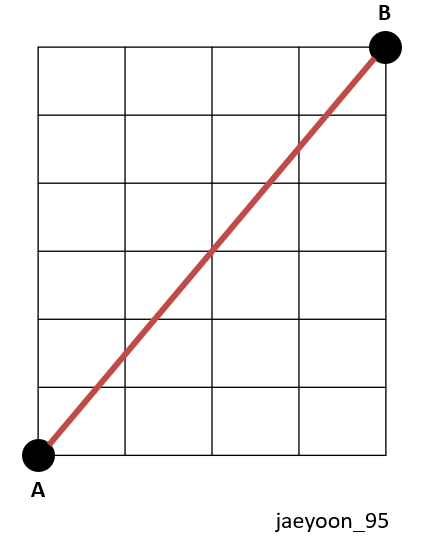
A문장과 B문장의 유사도를 구할 때, 시각적으로 나타내자면 위의 그림과 같습니다.
· 맨하탄 유사도(Manhattan Similarity)
맨하탄 유사도는 사각형 격자로 이루어진 지도에서 출발점 A에서 도착점B까지 가로지르지 않고 갈 수 있는 최단 거리를 뜻합니다. 유클리디언 유사도는 A,B사이를 가로질러 최단 거리를 구했다면, A,B는 격자를 따라 가는 최단 거리입니다. 맨하탄 유사도 또한 1보다 큰 값이 나오기 때문에,
L1정규화를 사용합니다.
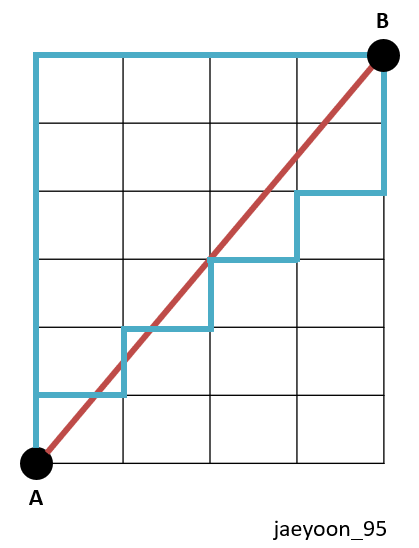
맨하탄 유사도는 위의 그림에서 파란색 선과 같습니다. 빨간색 선은 앞에서처럼 유클리디언 유사도를 뜻합니다.
· 코사인 유사도(Cosine Similarity)
코사인 유사도는 두 문장 벡터 사이의 코사인 각도를 구하는 방법입니다. 따라서 -1~1사이의 값을 가지고, 1에 가까울수록 유사도가 높습니다. 이 방법은 현재 가장 널리 쓰이는 방법이고, 위에서 소개한 다른 방법들보다 유사도가 정확합니다. 단순 좌표상의 거리가 아닌, 단어의 공간에서 벡터 간의 각도를 구하기 때문입니다. 수식은 아래와 같습니다.

위의 방법들을 정리하자면 아래와 같습니다.
(3) 텍스트 생성
텍스트 생성 즉, 자연어 생성은 주제에 대한 목적 의식을 가지고 언어에 맞는 문법과 올바른 단어를 사용해 문장을 생성하는 것입니다. 실제로 지진이 났을 때, Quakebot이라는 인공지능이 3분만에 지진 기사를 작성하기도 하였습니다. 이런 인공지능들은 사실에 바탕을 둔 글을 작성을 할 수는 있지만, 감정이나 논리력이 들어간 글을 작성하는 것은 한계가 있습니다. 또한 텍스트 생성을 가장 성공적으로 활용한 분야는 바로 기계번역 분야입니다.
(4) 기계 이해
기계 이해란 기계가 어떤 텍스트에 대한 정보를 학습하고, 사용자가 질의를 했을 때, 그에 대한 응답을 하는 문제입니다. 이러한 문제를 해결하기 위해서는 아래와 같은 조건들이 필요합니다.
· 문장의 의미를 표현한 벡터를 추출할 수 있어야함
· 질의와 텍스트 간의 유사성을 계산할 수 있어야함
· 답변을 생성 하거나 선택할 수 있어야함(생성 혹은 분류)
더 자세한 내용은 뒤의 포스팅에서 다루고, 이를 학습하기 위한 데이터셋에 대해서 알아보겠습니다.
· bABI
이 데이터셋은 페이스북에서 만든 데이터셋으로, 총 20가지 부류의 질문 내용으로 구성되어있습니다. 시간 순서대로 나열된 텍스트 문장 정보와 그에 대한 질문으로 구성되어있습니다.

쉽게 설명드리자면, 시간 순서로 나타낸 문장들과 질문을 함께 입력으로 주면, 모델이 문장과 질문을 이해하고, 유사도를 찾은 뒤, 답변을 생성하는 문제입니다.
· SQuAD(Stanford Question Answering Dataset)
SQuAD는 스탠퍼드 자연어 처리 연구실에서 만든 데이터 셋입니다. 이 데이터 셋은 위키피디아에있는 내용을 QA(Question Answering)데이터 셋으로 만들었습니다. 총 46개의 주제에 대해 10만개의 질문 데이터셋으로 이루어져 있습니다. 질문은 인물, 시간, 장소, 이유 등의 다양한 형태로 존재합니다.

학습 목적 자체는 위의 bABI와 유사합니다. SQuAD는 하나의 문단과 질문을 주고, 문단과 질문을 모두 이해하고, 유사성을 찾은 뒤, 답변을 생성해내는 문제입니다.
· VQA(Visual Question Answering)
VQA는 앞의 두 데이터셋과는 다르게 글이 아닌 이미지와 질문을 같이 입력받습니다. 따라서 Image Embedding이 별도로 필요합니다.

