
페이징은 프로세스를 물리적으로 일정한 크기로 나눠 메모리에 할당하였다.
세그멘테이션
- 프로세스를 논리적 내용일 기반으로 나눠 메모리에 배치하는 것을 말한다.
- 세그먼트의 집합으로, 각 세그먼트의 크기는 일반적으로 같지 않다.
- 프로세스를 code, data, stack으로 나누는 것 역시 세그멘테이션의 모습이다. 물론 code, data, stack 각각 내부에서 더 작은 세그먼트로 나눌 수도 있다.
세그먼트를 메모리에 할당할 때는 페이지를 할당하는 것과 동일하다.
하지만 테이블은 조금 다른데, 세그멘테이션을 위한 테이블은 세그먼트 테이블이라고 한다.
그리고 세그먼트 테이블은 세그먼트 번호와 시작 주소, 세그먼트 크기를 엔트리로 갖는다.
세그먼트에서 주소 변환 역시, 페이징과 유사하다.
✋ 한 가지 주의점은, 세그먼트의 크기는 일정하지 않기에 테이블에 limit정보가 주어진다.
CPU에서 해당 세그먼트의 크기를 넘어서는 주소가 들어오면 인터럽트가 발생해서 해당 프로세스를 강제 종료시킨다.
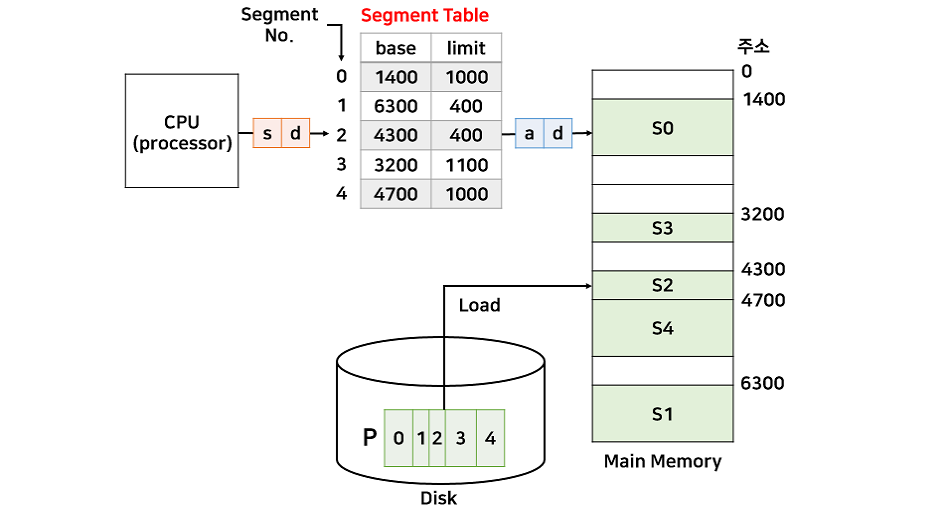
위 그림은 세그먼트 테이블과 프로세스가 할당된 메모리의 모습이다.
페이징 주소변환과 동일하게 d는 논리주소와 물리주소가 동일하다.
물리주소 a는 base[s] + d로 계산된다.
- 논리주소 (2,100) -> 물리주소 4400번지 (4300+100)
- 논리주소 (1,500) -> 인터럽트로 인해 프로세스 강제 종료(범위 벗어남)
세그멘테이션에서의 보호/공유
페이징보다 세그멘테이션에서의 보호와 공유는 더 효율적이다.
보호에서는 세그멘테이션 역시 r,w,x 비트를 테이블에 추가하여, 세그멘테이션은 논리적으로 나누기에 해당 비트를 설정하기 매우 간단하고 안전하다.
페이징은 code+data,stack 영역이 있을 때 이를 일정한 크기로 나누므로 2가지 영역이 섞일 수가 있다. 그러면 비트 설정이 매우 까다로워진다.
공유에서도 마찬가지다.
페이징에서는 code 영역을 나눈다해도 다른 영역이 포함될 확률이 매우 높다.
하지만, 세그멘테이션은 정확히 code 영역만 나누기에 더 효율적으로 공유를 수행할 수 있다.
세그멘테이션 & 페이징
세그멘테이션은 페이징과 유사하고 보호와 공유에서는 더 나은 성능을 보여주지만, 현재 대부분은 페이징 기법을 사용한다.
그 이유는 세그멘테이션의 치명적 단점에 있다.
메모리 할당을 처음 시작할 때 다중 프로그래밍에서의 문제는 크기가 서로 다른 프로세스로 인해 여러 크기의 hole이 발생한다.
이로 인해, 어느 hole에 프로세스를 할당하는 것에 대한 최적화 알고리즘이 존재하지 않고, 외부 단편화로 인해 메모리 낭비가 크다고 했었다.
세그멘테이션도 동일한 문제점이 발생한다.
왜냐? 세그멘테이션은 논리적인 단위로 나누기에 세그먼트의 크기가 다양하다.
이로 인해 다양한 크기의 hole이 발생하므로 같은 문제가 발생한다.
결론적으로 세그멘테이션은 보호/공유에서 효율적이고,
페이징은 외부 단편화 문제를 해결 할 수 있다.
그래서 2가지를 같이 사용하는 방법이 나왔고 두 장점을 합치기 위해 세그먼트를 페이징 기법으로 나누는 것이다. (Paged Segmentation)
이 역시 단점은 있다.
세그먼트와 페이지가 동시에 존재할 수 있기에 주소 변환도 2번 해야 한다.
즉, CPU에서 세그먼트 테이블에서 주소 변환을 하고, 그 다음 페이지 테이블에서 또 주소 변환을 해야 한다..
