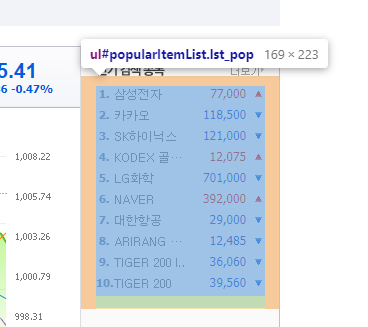
크롤링할 내용이 담긴 부분을 찾는다.
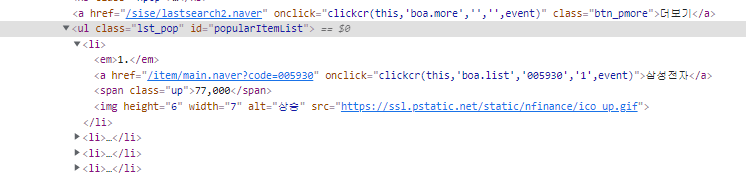
추출할 내용들을 둘러싸고 있는 태그는 ul 태그이고 class 명은lst_pop이다.
여기서 이름과 가격만 추출할 것이다.
li부분을 펼치게 되면 추출해야할 내용들이 보인다.
삼성전자 = a태그
77,000 = span
이제 모두 숙지 하였으니 코딩해보자.
from bs4 import BeautifulSoup
import urllib.request
url='https://finance.naver.com/sise/' #주소를 변수에 넣기
resp = urllib.request.urlopen(url) # url을 넣어 html형식으로 돌려받는다.
# print(resp) # <http.client.HTTPResponse object at 0x0000022FAA0BE940
soup = BeautifulSoup(resp,'html.parser',from_encoding='euc-kr') #불러올때 한글깨짐으로 encoding 설정
sises = soup.find('ul',{'class' : 'lst_pop'}) # class가 lst_pop인 ul 태그를 찾는다.
#sises = soup.find_all('ul', class_= 'lst_pop') #find_all로 찾을 때
#sises = soup.find('ul',{'id' : 'popularItemList'}) # id로찾기
sises_kor = sises.select('li') # sises에서 li 태그를 찾음
for sise in sises_kor: #반복
title = sise.find('a').text # a 태그를 text로 가져온다.
result = sise.find('span').text # span 태그를 text로 가져온다.
print(f'{title} \t {result}') # title과 result 출력출력

개발 옹알이 부터
안녕하세요! 주식 크롤링을 따라해보고 있는데, 10개보다 더 많은 갯수를 출력하려면 어떻게 하면 되나요?