데이터 분석 작업흐름(DA workflow) = 데이터 분석 흐름(DA pipeline)
데이터 수집
#1. 판다스 넘파이 import
import pandas as pd
import numpy as np
#2. 판다스의 read_html 메소드를 이용해서 특정 웹사이트 페이지를 읽어서 가져오자. <<단일테이블>>
#<<주의>> read_html의 웹페이지의 테이블만 읽어온다.
타자수_선수기록표 = pd.read_html('https://www.koreabaseball.com/Record/Player/HitterBasic/BasicOld.aspx')
투수_선수기록표 = pd.read_html('https://www.koreabaseball.com/Record/Player/PitcherBasic/BasicOld.aspx')
수비_선수기록표 = pd.read_html('https://www.koreabaseball.com/Record/Player/Defense/Basic.aspx')
#3. 다중 테이블도 읽어오자.
역대구단성적_2010 = pd.read_html('https://www.koreabaseball.com/Record/History/Team/Record.aspx?startYear=2010&halfSc=T')pandas의 read_html() 메소드를 사용하여 웹페이지를 읽어온다.(테이블형식(tag)만 읽어온다.)
특정 테이블을 추출하자
역대구단성적_2010[2].head(5)
pandas의 head()메소드를 사용해 넣은값 만큼 DataFrame형식으로 추출
불러온 테이블을 html형식으로 저장해 보자.
print(역대구단성적_2010[2].to_html())to_html() : html형식으로 저장
to_csv() ,to_json() 등도 자연스럽게 있을 것이라고 생각하자
주루수_선수기록표라는 변수를 html로 읽어와서 첫번째 테이블의 3줄만 출력 해보자
주루수_선수기록표 = pd.read_html('https://www.koreabaseball.com/Record/Player/Runner/Basic.aspx')
주루수_선수기록표[0].head(3)
주루수_선수기록표[0].head(3) = 선수기록표의 0번째 인덱스, 0~3까지 head(테이블)을 출력한다.
print(type(타자수_선수기록표))
# 리스트의 첫번째 요소만 가져와서 독립적인 데이터프레임을 만들어서 사용한다.
타자수_df = 타자수_선수기록표[0]
타자수_df그냥 간단하게
타자수_선수기록표의 0번째 테이블을타자수_df변수에 담은 것
데이터 가공
선수기록표_요약 이라는 변수에 타자수_df의 순위,팀명,AVG,선수명 만 넣어 가공하자.
선수기록표_요약 = pd.DataFrame(타자수_df,columns=['순위','팀명','AVG','선수명'])
선수기록표_요약.head()
columns=[] 안에 데이터 넣는 순서대로 출력된다. (데이터의 컬럼명과 같아야함)
데이터 탐색 : EDA(Exploratory Data Analysis) 탐색적 데이터 분석
선수기록_요약의 데이터를 이용해서 팀별 , 타율별로 정렬해 출력 해보자.
선수기록표_요약_정렬 = 선수기록표_요약.sort_values(by=['팀명','AVG'], ascending=True)
선수기록표_요약_정렬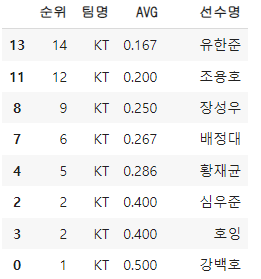
ascending=True: 오름차순
ascending=False: 내림차순
MVP를 출력해보자.
MVP = 선수기록표_요약.loc[선수기록표_요약['AVG'].idxmax()]
print(type(MVP)) #series타입
pd.DataFrame(MVP)
idxmax: 최대값
idxmin: 최소값
데이터 분석
-
데이터 탐색 : 데이터를 살펴 보는 것
-
데이터 분석 : 정보를 추출 하는 것
타율이 3할대인 우수 타자들의 타율을 분석해보자.
#평균 타율이 3할때인 우수한 타자들을 알아내자.
우수한타자 = 타자수_df.loc[타자수_df['AVG'] > 0.3]
print(type(우수한타자))
우수한타자
#pd.DataFrame(우수한타자) DataFrame타입이 아닐시 DataFrame타입으로 변환하여 출력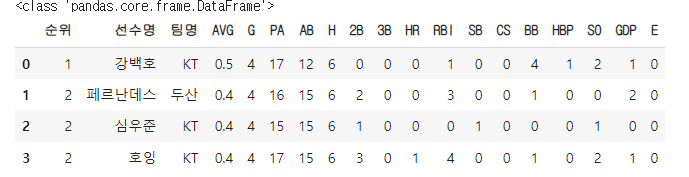
loc[]를 사용하여AVG만 분석 후AVG가 높은 순으로 출력
우수한 타자들의 통계적인 값을 각각 출력 해보자
print('----------------------------------------------------------')
print(f"우수한 타자들의 타율 평균 = \t{np.average(우수한타자['AVG'])}")
print(f"우수한 타자들의 타율 분산 = \t{np.var(우수한타자['AVG'])} ")
print(f"우수한 타자들의 타율 표준편차 = \t{np.std(우수한타자['AVG'])} ")
print('-----------------------------------------------------------')
print(f"우수한 타자들의 타율 최소타율 = \t{np.min(우수한타자['AVG'])} ")
print(f"우수한 타자들의 타율 1분위수 = \t{np.percentile(우수한타자['AVG'],25)} ")
print(f"우수한 타자들의 타율 2분위수 = \t{np.percentile(우수한타자['AVG'],50)} ")
print(f"우수한 타자들의 타율 3분위수 = \t{np.percentile(우수한타자['AVG'],75)} ")
print(f"우수한 타자들의 타율 최대타율 = \t{np.max(우수한타자['AVG'])} ")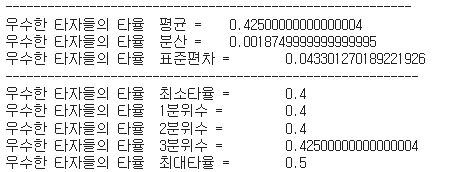
최우수 선수 그룹 (타율 3분위 이상에 속하는 선수) 선별 후
우수한 타자들의 홈런 개수 평균을 확인하자.
print(f"우수한 타자들의 홈런 개수 평균 = \t {np.average(우수한타자['HR'])}")우수한 타자들의 홈런 개수 평균 = 0.25
최우수 선수 그룹 (타율 3분위 이상에 속하는 선수) 선별
삼분위_타율 = np.percentile(우수한타자['AVG'],75)
최우수_타자수 = 우수한타자.loc[우수한타자['AVG'] >= 삼분위_타율]
최우수_타자수
당시 시즌이 시작한지 얼마 안되서 사기급이다...
시각화를 연습해 보자.
판다스를 이용해서 csv를 읽어오자.
df = pd.read_csv('/content/sample_data/california_housing_train.csv')
df.head()
import matplotlib.pyplot as pltgoogle의 colab이 갖고있는 샘플데이터를 사용했다.
분산 플랏 : 분산은 변수간의 상관관계를 시각적으로 확인하고 데이터 값의 가변성과 범위를 시각적으로 확인
데이터를 먼저 가로축과 세로축에 / 열 데이터 및 열 데이터의 분산된 플랏을 그려보자.
# 정규분포 = 평균, 표준 편차를 이용해서 분포
plt.scatter(df['median_income'], df['median_house_value'])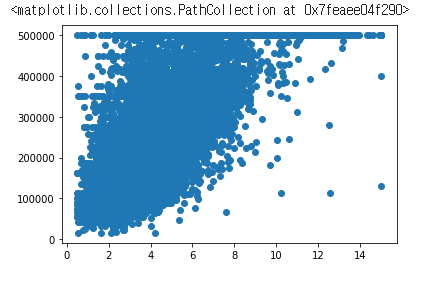
히스토그램 : 각 값이 데이터에 표시되는 빈도를 확인 하는데 사용
meddian_house_value 를 이용해서 빈도수를 알아보자
plt.hist(df['median_house_value']) # (데이터,, 매개인자)
# 히스토그램은 인수값(매개인자)을 이용해서 값 범위를 지정해야 한다.
# 범위의 값을 지정하고 각 범위의 샘플 수를 그려낸다.
# 만약 인수를 지정하지 않는다면 자동으로 저장소가 결정된다.
# 매개인자 인수에 정수를 부여하면 값 범위에 대한 빈을 균등한 간격으로 만들어준다.
# bins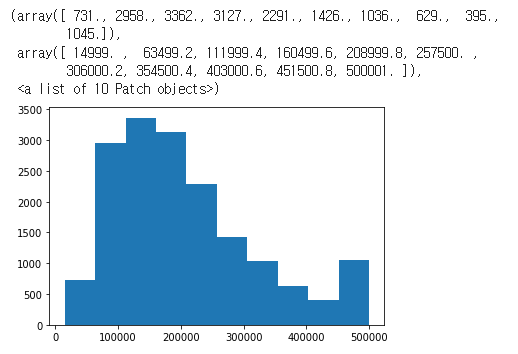
히스토그램의 빈을 이용한 균등 값 확인
plt.hist(df['housing_median_age'], bins=50)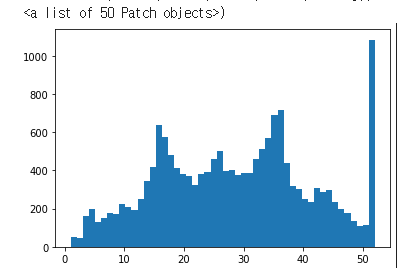
박스 플롯 : 변형된 값을 이해하기 쉽게 표시 [통계 시각화] 5개의 통계결과를 요약해서 표시할 때 사용된다.
plt.boxplot(df['median_house_value'])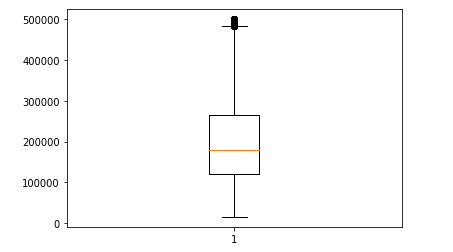
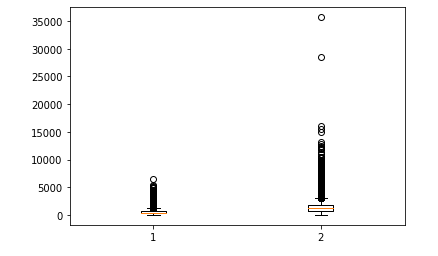
두개의 데이터를 이용한 박스플롯
plt.boxplot( (df['total_bedrooms'],df['population']))
선 차트 : 시계열 (시간, 날짜 데이터)등 타임라인에 적용되는 데이터를 표시할 때 사용
# ex) plot(y) : 하나의 인수가 있는 경우 요소는 세로 축(y) 값에 해당하며 가로 축(x)은 요소의 인덱스 값이 지정된다.
import numpy as np
x = np.linspace(0,10,100)
x
y = x+ np.random.randn(100)
y
plt.plot(y)
plt.plot(x,y) # 가로축(x), 세로축(y)
x값은 y에 의해 결정되기 때문에 위와 동일하게 나온다.
통계형 다이어그램을 쉽게 만들수 있도록 Matplotlib -> seaborn 이 있다.
import seaborn as sns
#데이터 분포 : distplot()을 사용
sns.distplot(df['housing_median_age'])
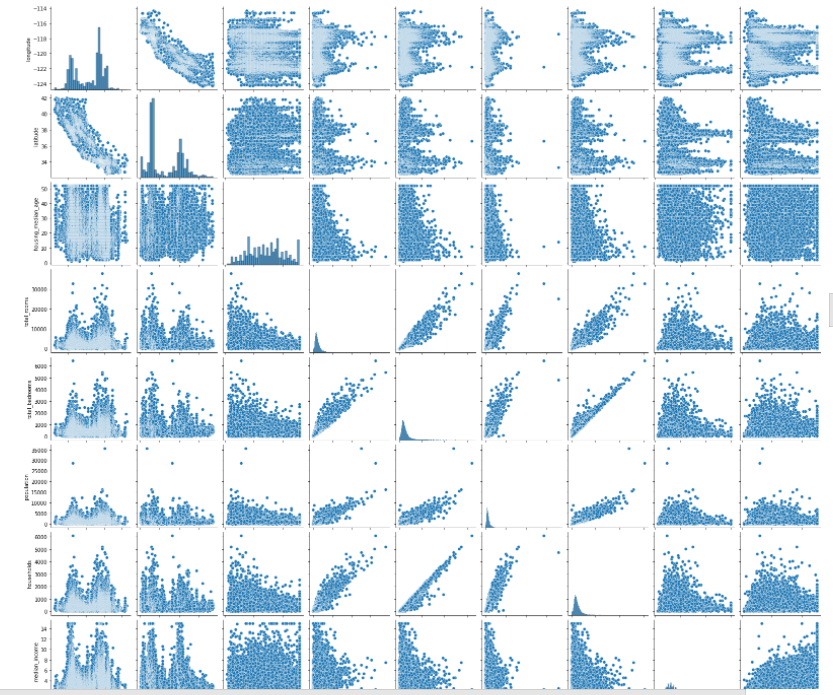
지정된 데이터 프레임 객체의 모든 열을 분산 플랏그리드로 표시해서 다양한 변수간의 상관관계를 시각적으로 확인 _ pairplot()
sns.pairplot(df)