

- 📝 Designing Data-Intensice Applications 을 읽고 정리한 글입니다.
- 이 책은 데이터베이스와 분산시스템을 구성하는 전반적인 개념들을 깊게 다루고 있는 책으로써, 대규모 데이터를 처리하고, 지탱하는 기술들에 대해 설명하고 있습니다.
- 작성 일자: 2020-07-28
1. Reliable, Scalable, and Maintainable Applications
- Role of an application developer is to design the data system for reliability, scalability and maintainability.
1) Reliability
- Fault tolerance
- No unauthorized access
- Chaos testing
- Full machine failures
- Bugs - Automating tests
- Staging/testing environment
- Quickly roll-back
2) Scalability
- Handle higher traffic volume (웹 서버의 초당 요청 수)
- Traffic load with peak #of reads,writes and simultaneous users (데이터베이스의 읽기 대 쓰기 비율)
- 캐시 적중률
- Capacity planning
- Response time vs throughput.
- End user response time
- 90th,95th Percentile SLO/A service level objectives/agreements.
- scaling up (more powerful machine)
- scaling out (distributed many smaller machines).
throughput : 초당 처리할 수 있는 레코드 수나 일정 크기의 데이터 집합을 처리할 때 걸리는 전체 시간으로, 하둡과 같은 일괄 처리 시스템에서 사용하는 지표이다.
response time : 클라이언트가 요청을 보내고 응답을 받는 시간
3) Maintainability
- Add new people to work
- productivity
- Operable: Configurable and testable
- Simple: easy to understand and ramp up
- Evolveable: easy to change
2. Data Models and Query Languages
- facebook의 컨셉을 relational databse로 나타낸다면
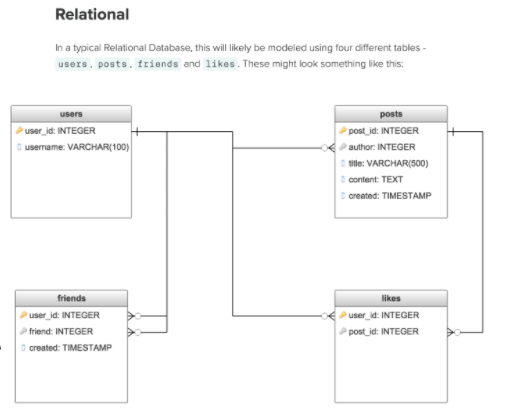
- fackbook관련 쿼리를 다음과 같이 3가지 형태의 다른 데이터베이스 모델로 나타낼 수 있다.
-
Relational Query

-
Document Based Model

-
Graph Model
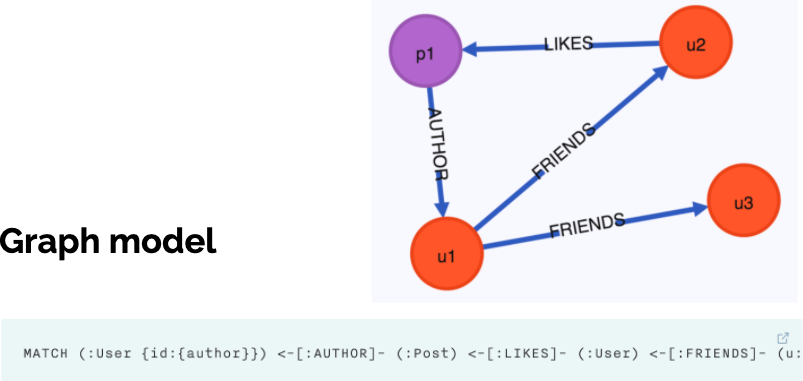
-
위의 사례를 통해, 적합한 데이터 베이스 모델 선택의 중요성을 보여준다.
Data Storage and Data Retrieval are the two main things to consider. Same query can be either written in 4 lines or with 30 lines based on your data model!
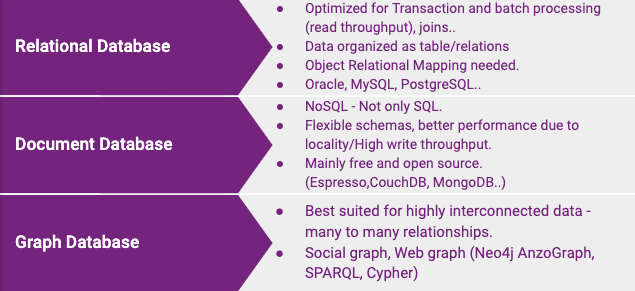
Document databases: target use cases where data comes in self-constrained documents and relationships between one document and another are rare.
Graph databases: go in the opposite direction, targeting use cases where anything is potentially related to everything.
3. Storage and Retrieval
1) Which database to use ??
There are two broad categories of databases - OLTP and OLAP each with different read pattern, write patterns, user using it, data size etc.
1. OLTP - Online Transaction processing database are optimized for latency.
E.g. MySQL, Oracle.
2. OLAP - Online Analytical processing databases are optimized data crunching! Data Warehousing - Star/Snowflake schema, Column oriented, Column compression, Data Cubes, optimized for reads/queries. Materialized views. Lack of flexibility.
E.g. Hbase, Hive, Spark,
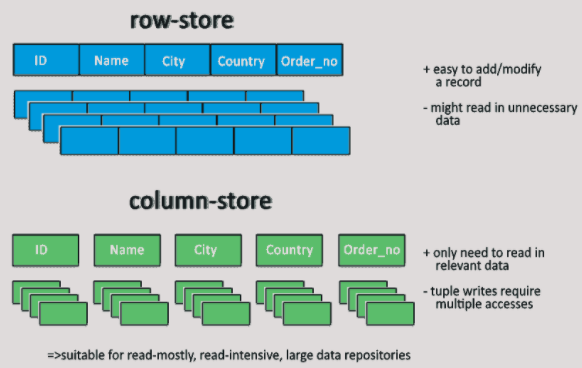
- 참고자료: DB의 지연을 줄이기 위한 노력
2) Database Index
-
An Index is an additional structure that is derived from the primary data. A well chosen index optimizes for reads but slows down the write. 즉, 색인은 쓰기 속도를 느리게 만드는 대신 읽기를 빠르게 하는 역할을 하는 것입니다
-
There are two families of storage engines these databases use
1) Log-structured : LSM-Trees ex) SSTables → HBase, Cassandra
Log-structured 관점에서 추가와 오래된 파일의 삭제만 허용하고 한 번 쓰여진 파일은 절대 갱신하지 않는다. it is fast to only append to the file.
2) Page-Oriented : B-trees → RDBMS
Page-Oriented 관점에서 덮어쓰기 할 수 있는 고정 크기 페이지의 셋으로 디스크를 다룬다.
2-1) LSM-Trees
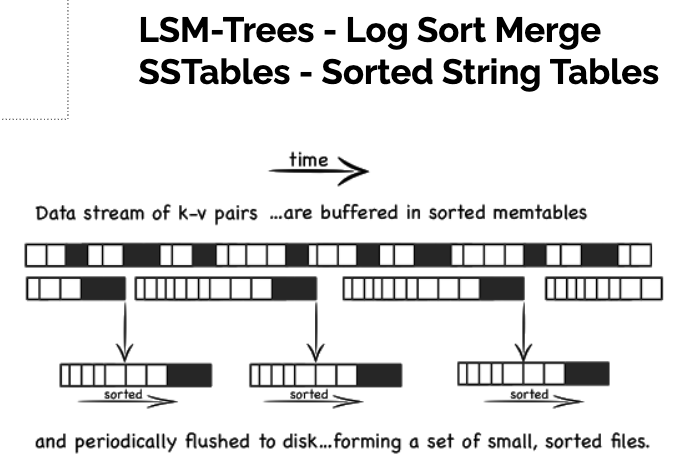
LSM Tree의 구성 요소:
-
SSTables - in-memory memtable backed by Disk SSTable file, sorted by keys. E.g. Red-black tree or AVL Trees. Supports high right throughput.
정렬된 키의 이점으로
1) 세그먼트 병합이 간단하고 효율적 - 병합정렬(mergesort) 알고리즘과 유사
2) 세그먼트는 정렬되어 있기 때문에 특정 키를 찾기 위해 모든 키를 색인으로 유지할 필요가 없습니다 -
Bloom filters - memory-efficient data structure used for approximating the contents of a set. It can tell you if a key does not appear in the database, thus saves many unnecessary disk reads for nonexistent keys. 블룸 필터는 키가 데이터베이스에 존재하지 않음을 알려주므로 존재하지 않는 키를 위한 불필요한 디스크 읽기를 방지할 수 있습니다.
-
Compaction is a background process of the means of throwing away duplicate keys in the log and keeping only the most recent update for each key. eg) LevelDB, RocksDB, Cassandra and HBase. 각각의 파일에 대해 컴팩션(compaction)을 수행할 수 있습니다. 컴팩션은 각 로그의 중복된 키 값을 버리고 각 키의 최신 값만 유지하는 것을 의미합니다. 이를 통해 디스크 공간 부족문제를 해결할 수 있습니다.
SSTable의 생성과 유지:
디스크 상에 키를 정렬하여 유지할 수도 있지만, 메모리에서 하는 것이 훨씬 쉽다. Red-black tree 나 AVL Tree 같은 데이터 구조를 사용하면, 임의 순서로 키를 삽입하고 정렬된 순서로 키를 다시 읽을 수 있다.
이에 저장소 엔진을 다음과 같이 만들 수 있다.1. 쓰기가 들어오면 balanced tree 데이터 구조에 추가한다. 이 인메모리 트리를 memtable 이라고 한다. 2. memtable 이 수 메가바이트 정도 임곗값보다 커지면 SS 테이블 파일로 디스크에 기록한다. 3. 읽기 요청이 오면 memtable 에서 키를 찾는다. 그 다음 디스크의 최신 세그먼트에서 찾는다. 이를 반복한다. 4. 병합과 컴팩션을 백그라운드에서 수행한다.만약 데이터베이스가 고장나면 아직 디스크에 쓰지 않은 memtable 은 손실된다. 이런 문제를 피하기 위해서는 매번 쓸 때마다 분리된 로그를 디스크상에 유지하면 된다. memtable을 SS 테이블로 기록하면 해당 로그는 버리면 된다.
SS 테이블에서 LSM 트리 만들기:
LSM 트리 알고리즘은 존재하지 않는 키를 찾기 위해서 모든 세그먼트를 다 뒤져야 하는 문제가 있다. 이를 막기 위해, 저장소 엔진은 보통 블룸 필터(Bloom filter) 를 추가적으로 사용한다. 또한 SS 테이블을 압축 / 병합하는 순서와 시기를 결정하는 다양한 전략이 있다. 가장 일반적으로 size-tiered 와 leveled compaction 을 많이 사용한다.1. size-tiered: 상대적으로 좀 더 새롭고 작은 SS 테이블을 상대적으로 오래되었고 큰 SS 테이블에 연이어 병합한다. 2. leveled compection: 키 범위를 더 작은 SS 테이블로 나누고 오래된 데이터는 개별 레벨로 이동하여, 컴팩션을 점진적으로 진행한다. 이는 디스크 공간을 덜 사용하게 된다.
LSM 트리의 기본 개념은 백그라운드에서 연쇄적으로 SS 테이블을 지속적으로 병합하는 것이다. 추가와 세그먼트 병합은 순차적인 디스크 쓰기 작업이기 때문에 random write보다 높은 쓰기 처리량을 보장할 수 있습니다. ex) HBase, Google BigTable, Cassandra 에서 사용됨
2-2) B-Tree
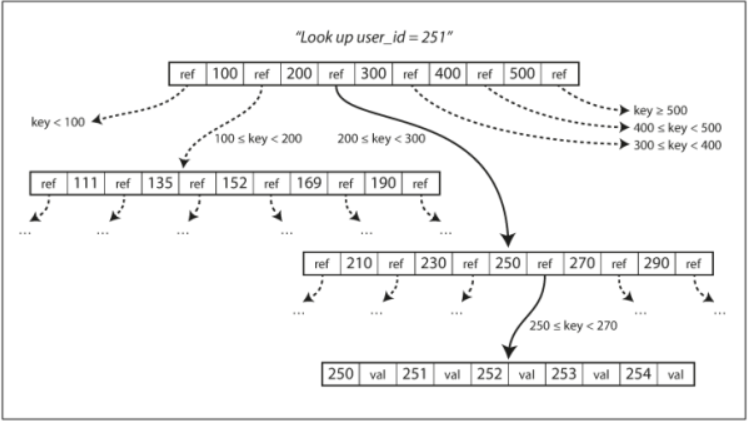
- Most widely used indexing structure is B-Trees. One place per key!
- They are the standard implementation in RDBMS and NoSQL stores today.
- It also keeps key-value sorted by keys which allows quick lookups.
- B-tree 는 4kb 크기(혹은 더 큰)의 고정 크기 블록이나 페이지로 나누고, 한 번에 하나의 페이지에 읽기 또는 쓰기를 한다.
- There is a root node and a branching factor (references to child pages).
- 이 알고리즘은 트리가 계속 balanced 상태임을 보장한다. n 개의 키가 있는 B-tree 는 깊이가 항상 O(logn) 이다. 대부분의 데이터베이스에서 B-tree 의 depth 는 3이나 4 면 충분하므로 검색하려는 페이지를 찾기 위해 많은 페이지 참조를 따라가지 않아도 된다. 4 level tree with 4KB pages with branching factor of 500 can store up to 256TB!! B-Tree is optimized for reads!
- Write ahead log is used for Crash recovery, Latches for concurrency.
- 각 페이지는 주소나 위치를 이용해 식별할 수 있다. 이 방식으로 하나의 페이지가 다른 페이지를 참조할 수도 있다. 다른 페이지를 참조하여 페이지 트리를 만들 수 있다.
B-Tree 와 LSM Tree 비교:
LSM 트리 는 쓰기가 빠르고, B-tree 는 읽기가 빠르다.
LSM 트리에서 읽기가 느린 이유는, 각 컴팩션 단계에 있는 여러 데이터 구조와 SS 테이블을 확인해야 하기 때문이다.
B-tree가 쓰기 속도가 느린 이유는, 존재하는 키의 값을 update 하려면 리프 페이지까지 검색한 후에 페이지에 있는 값을 변경 후 디스크에 다시 씁니다
4. Replication
1) Replication의 장점
- 지리적으로 사용자와 가까운 곳에 데이터가 존재할 수 있어서 지연 시간(latency)을 줄여줍니다.
- 시스템에 일부 장애가 발생해도 지속적으로 동작할 수 있게 해 가용성(availability)를 높여줍니다.
- 데이터를 여러 장비로부터 읽을 수 있어서 처리량을 늘려줍니다.
2) 데이터 베이스에서의 Replication 종류:
- Leader의 경우 write를 주로 담당하고, Follower들의 경우 주로 read를 담당한다.
2-1) single leader (Master-Slave)
2-2) multi-leader (multi-Master - Slave)
쓰기 충돌 문제 해결 방법:
- 충돌 회피 : 특정 레코드의 모든 쓰기가 동일한 리더를 거치도록 애플리케이션이 보장
- 일관된 상태 수렴 : 데이터베이스에 데이터가 최종적으로 수렴(convergent)하는 방식으로 충돌 해결 - ex) 타임스탬프를 사용한 최종 쓰기가 저장되는 방식(Last write wins), 고유 ID 부여, 데이터 병합, 충돌 기록 후 사용자가 해결하도록 제공 등
- 사용자 정의 충돌 해결 로직 : 사용자가 애플리케이션 코드에서 충돌 해결 로직을 작성하도록 하는 방법
2-3) leaderless
- 일부 시스템에서는 클라이언트가 직접 여러 복제 서버에 쓰기를 전송하는 반면, ZooKeeper와 같은 코디네이터 노드가 클라이언트를 대신에 이를 수행하기도 한다.
-
anti-entropy방식: 클라이언트에서는 오래된 데이터를 감지하고 이를 바로잡기 위해 병렬로 여러 노드에서 데이터를 읽습니다. 일부 데이터스토어에서는 백그라운드 프로세스를 두어서 복제 서버 간 데이터 차이를 지속적으로 찾아 다른 복제 서버로 복사합니다
-
quorum(최소 투표수)을 이용한 민주주의 방식: 리더리스 복제 방식에서는 읽기와 쓰기를 위해 필요한 최소의 투표수가 필요합니다. 즉 여러 복제 서버들로부터 데이터를 읽거나 쓰는 경우 최소 얼마 이상의 투표가 이루어져야지 정상적으로 데이터를 읽은 것이나 쓴 것이라고 판단합니다.
3) 노드 중단 처리:
3-1) Follower 장애:따라잡기 복구
- 팔로워는 리더로부터 수신한 데이터 변경 로그를 로컬 디스크에 보관한다.
- 팔로워에 장애가 발생한 후 복구되면, 보관된 로그에서 결함이 발생하기 전에 처리한 마지막 트랜젝션을 알아낸다.
- 리더에 연결해 장애가 발생한 동안 받지 못한 데이터 변경을 요청한다.
3-2) Leader 장애: 장애 복구(Fail Over)
=> 많은 문제가 발생할 수 있음으로, 수동으로 보통 해결한다.
장애 복구과정에서의 발생 가능 문제:
- 비동기식 복제를 사용한다면 새로운 리더는 이전 리더가 실패하기 전에 이전 리더의 쓰기를 수신하지 못할 수 있다.
- 오래된 팔로워가 리더로 승격될 수 있다. 즉, 이전 리더의 최신 데이터 변경사항을 가진 팔로워가 리더가 되어야 하는데 그렇지 못할 수 있다. 이 경우 예전에 사용한 Auto Increment 키를 다시 사용하는 케이스가 발생할 수 있는데, 이 키를 가지고 다른 데이터베이스의 키로 삼는 경우 장애가 발생할 수 있다.
- 특정 경우에 두 개의 노드가 모두 자신이 리더라 믿을 수 있다. 이를 split brain 이라고 부르는데, 매우 위험한 상황이다.
4) Replication Lag 문제 (복제 지연 문제)
- Even if the replication lag is usually small, a whole range of factors (for example network problems or high load) can cause the lag to become several seconds or even minutes. Several problems can occur when you have replication lag:
문제점 및 해결 방법:
- 자신이 쓴 내용 읽기(read your own writes): 사용자가 쓰기를 수행한 직후 데이터를 보는 경우 아직 복제 서버에는 반영이 안될 수도 있습니다. 물론 최종적으로는 반영될 것이지만 (이를 eventual consistency라고 합니다) 데이터 변경 직후에는 사용자가 보기엔 데이터가 유실된 것처럼 보이기 때문에 문제가 있습니다.
- 단조 읽기(Monotonic reads): 단조 읽기는 각 사용자의 읽기는 동일한 복제 서버에서 읽도록 하는 방법입니다. 사용자 ID를 해시 기반으로 복제 서버를 선택하여 읽도록 하는 방식입니다. 이 방식은 최종적 일관성(eventual consistency)보다는 더 강한 보장 방식입니다.
5. Partitioning
-
The reason for breaking the data up into partitions (also known as sharding) is scalability
-
The partitioning can be done on key range or by hashing of the key
1) key-range: 키를 통하여 분할하는 방식은 특정한 접근 패턴이 핫스팟을 유발할 수 있다. 타임스탬프를 기준으로 하루 단위로 파티션을 분할한다고 가정해 보자. 키를 정렬된 순서로 저장한다면 가장 마지막 파티션이 모든 요청 부하를 받게 될 것이다.
2) hashing of the key: 이 기법은 키를 파티션 사이에 균일하게 분산시키기에 좋다. 그러나 단점이 있는데, 해시함수를 사용하여 키를 결정하면 정렬된 키를 가지고 데이터를 쉽게 질의할 수 있는 장점을 잃어버리게 된다.
Partiting Rebalancing
-
하면 안되는 전략(hash mod N): 새로운 서버가 추가되는 경우 파티션 개수가 증가하게 되고, 대부분의 파티션을 다른 서버로 이동시켜야 한다. 이 경우 리밸런싱 비용이 지나치게 커진다.
-
A better approach is to use many more partitions than there are nodes and only move entire partitions between nodes. 이 전략을 사용하는 경우, 보통 파티션 개수를 변경하지 않는다. 이론적으로는 파티션을 합치고 분할할 수 있지만, 개수를 변경하지 않는 편이 편리하기 때문이다.
-
Consistent Hashing: ex) Memcached, Cassandra
- Each object key will belong in the server whose key is closest, in a counterclockwise direction (or clockwise, depending on the conventions used)
- To ensure object keys are evenly distributed among servers, we need to apply a simple trick:instead of having labels A, B and C, we could have, say, A0 .. A9, B0 .. B9 and C0 .. C9, all interspersed along the circle. The factor by which to increase the number of labels (server keys), known as weight, depends on the situation (and may even be different for each server) to adjust the probability of keys ending up on each
- only k/N keys need to be remapped when k is the number of keys and N is the number of servers (more specifically, the maximum of the initial and final number of servers).
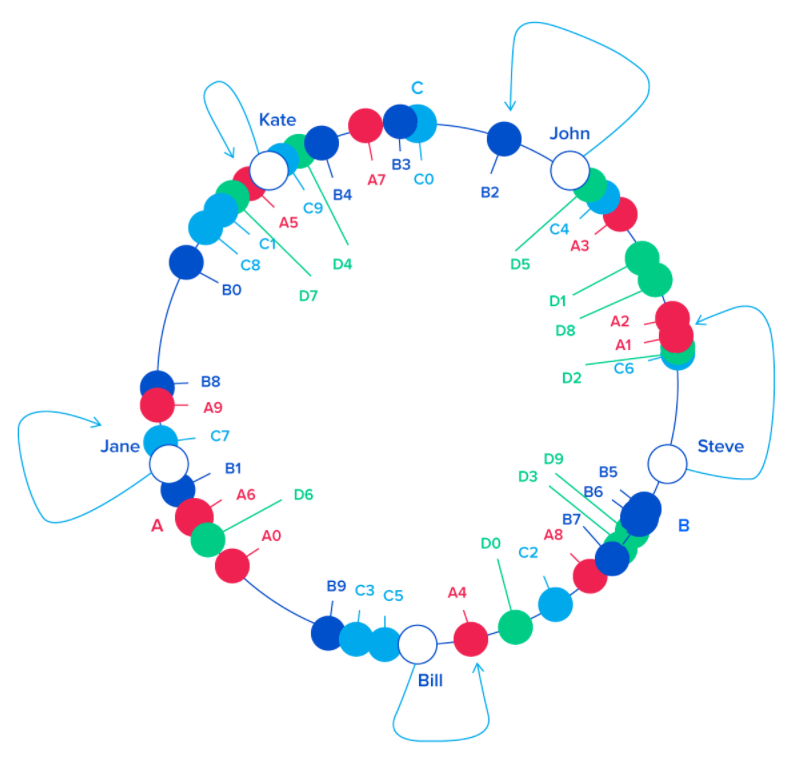
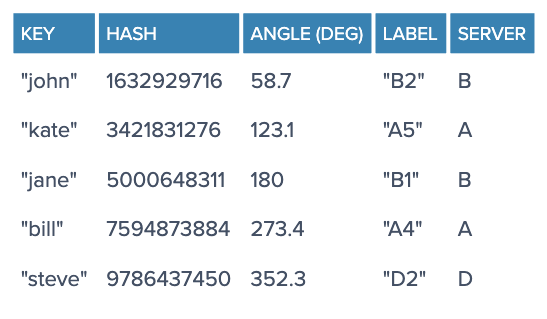
6. Transactions
1) ACID:
- Atomicity: either all writes succeeded, or none.
- Consistency: invariants must always be true before and after a transaction. For example, that credits and debits across all accounts are always balanced.
- Isolation: concurrently executing transactions don't interfere with each other.
- Durability: data that has been written successfully will not be lost.
2) Isolation Levels
1. read committed: 다른 트랜잭션에서 COMMIT 된 데이터만 읽어올 수 있는 level이다. - dirty read 해결
2. repeatable read : 동시성과 안정성의 균형을 가장 잘 갖춘 isolation level - dirty read, non-repeatable read 해결
3. SERIALIZABLE : 동시성을 상당 부분 포기하고 안정성에 큰 비중을 둔 isolation level - dirty read, non-repeatable read, Phantom reads 해결
dirty read: 아직 COMMIT 되지 않은 신뢰할 수 없는 데이터는 읽어올 수 없음
non-repeatable read: 한 트랜잭션에서 동일한 SELECT 쿼리의 결과가 동일
phantom read: 이전의 SELECT 쿼리의 결과에 없던 row가 생김
참고자료: MySQL Transaction Isolation Levels
7. The Trouble With Distributed Systems
1. Unreliable networks
- The connections between nodes can fail in various ways.
- a software upgrade of a switch causes all network packets to be delayed for more than a minute, sharks bite and damage undersea cables, all inbound packets are dropped, but outbound packets are sent successfully. Even in a controlled environment, such as one datacenter, network problems are common.
2. Unreliable clocks
- Time-of-day clocks return the current date and time according to some calendar. They are usually synchronized with NTP. Because the local clock on the machine can drift, it may get ahead of the NTP time, and a reset can make it appear to jump back in time.
- Even if NTP is used to synchronize different machines, there are many possible problems.
- Relying on timestamps for ordering events, such as Last Write Wins in, for example, Cassandra, can lead to unexpected results. One solution used by Google's Spanner is to have confidence intervals for timestamps and make sure there is no overlap when ordering events.
3. Process Pauses
- There are many ways this can happen: garbage collection, synchronous disk access that is not obvious from the code (Java classloader lazily loading a class file), operating system swapping to disk (paging), etc.
- Even worse would be if participating nodes would deliberately try to cause problems. That is called Byzantine faults
8. Consistency and Consensus
-
Distributed algorithms such as resource synchronization often depend on some method of ordering events to function
-
Ordering requires waiting
-
CAP Theorem : The CAP (Consistency-Availability-Partition) theorem also boils down to causality. When a machine in a distributed system is asked to perform an action that depends on its current state it must decide that state by choosing a serialisation of the events it has seen. It has two options:
1) Choose a serialisation of its current events immediately - 속도 > 정확성
2) Wait until it is sure it has seen all concurrent events before choosing a serialisation - 속도 < 정확성
1) Linearizability
- It makes the database behave like a variable in a single-threaded program. The problem is that it is slow, especially when there are large network delays.
2) Ordering Guarantees
- If two events happen concurrently, you can't say which happened first. This leads to the weaker consistency model of causality. It defines a partial order: some operations are ordered with respect to each other, but some are incomparable (concurrent).
- If the final state is dependent on the order of updates then the system must choose a single serialization of the events, imposing a global total order.
- Lamport timestamps: Lamport invented a simple mechanism by which the happened-before ordering can be captured numerically. A Lamport logical clock is a numerical software counter value maintained in each process. Conceptually, this logical clock can be thought of as a clock that only has meaning in relation to messages moving between processes. When a process receives a message, it re-synchronizes its logical clock with that sender.
- Vector clocks
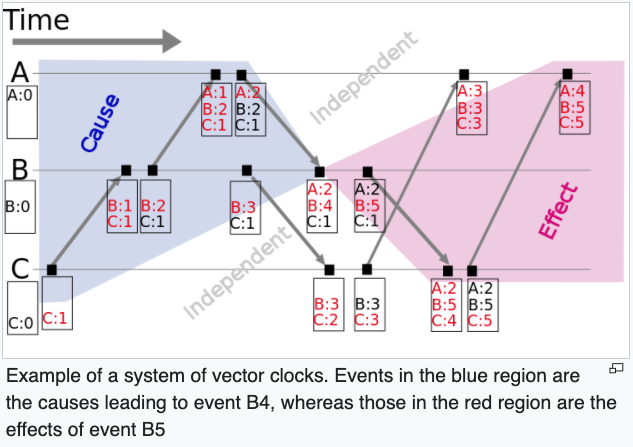
- Total Order Broadcast
3) ZoopKeeper
- provide 'consensus', 'failure detection', 'mempership service'
9. Batch Processing
10. Stream Processing
- Batch Processing과 Stream Processing 의 경우, 이전 포스팅인 빅데이터 파이프라인 구축을 위한 Lamda Architecture 에서 자세히 다루었음으로, 다음 추가 참고자료를 통해, 내용을 대신한다.

참고자료:
빅데이터의 데이터 수집형태, 벌크와 스트리밍
빅데이터 스트리밍 데이터 수집을 위한 Message Broker
데이터 수집 파이프라인과 메시지 중복 제거
🏝이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
참고 자료
- Designing Data Intensive Application 유튜브
- 데이터 중심 어플리케이션 설계 by astrod
- 데이터 중심 어플리케이션 설계 by Smart Tigers
- Dzone Book Review: Designing Data-Intensive Applications
- DB의 지연을 줄이기 위한 노력
- [DB] Transaction Isolation Level이란?
- MySQL의 Transaction Isolation Levels
- Causal ordering
- Zookeeper의 이해
- 빅데이터의 데이터 수집형태, 벌크와 스트리밍
- 빅데이터 스트리밍 데이터 수집을 위한 Message Broker
- 데이터 수집 파이프라인과 메시지 중복 제거
- A Guide to Consistent Hashing
- [입 개발] Consistent Hashing 과 Replication
- Strong consistency vs Eventual consistency
- Eventually Consistent by Amazon CTO
- Log Structured Merge(LSM) Tree
- LSM-Tree (Log Structured Merge Tree)
- Log Structured Merge Trees
- [MySQL] B-Tree 인덱스

오우.. 해외취업 위해서 시스템디자인 학습중인데 좋은글인것 같습니다.