

- 📝 Big Data: Principles and best practices of scalable realtime data systems 을 읽고 정리한 글입니다.
- 이 책은 Lamda Architecture를 소개하며, 어떻게 하면 효율적이며, 확장가능한 빅데이터 파이프라인을 구축할 수 있을지 소개하고 있습니다. Lamda Architecture은 Batch Layer, Serving Layer, Speed Layer로 구성되어 있으며, batch단위의 데이터와 real-time 데이터를 효율적으로 처리하는 방안을 제시합니다.
- 작성 일자: 2020-07-07
Lamda Architecture 구성 요소
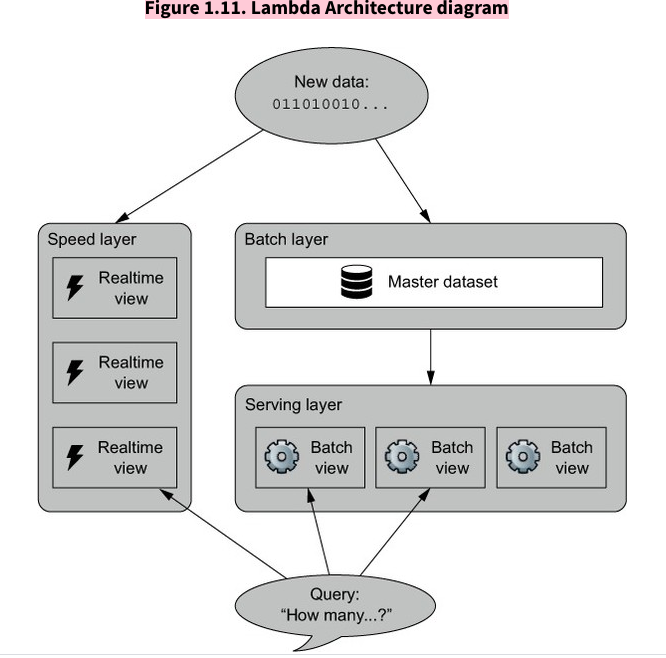
- Lamda Architecure는 1) Batch layer, 2) Serving layer, 3) Speed layer 으로 구성되어 있으며, Batch layer는 배치성 데이터를 담당하고, Serving layer는 배치성 데이터의 precomputed된 값을 제공하여 원하는 데이터를 빠르게 얻을 수 있게한다. 반면, Speed layer는 실시간성 데이터를 처리하는 역할을 한다. 배치성 데이터와 실시간성 데이터를 분리시켜 처리함으로써, 각기 다른 이점을 얻을 수 있다.
1. Batch Layer
- The goal of the batch layer is to produce views that are indexed so that queries on those views can be resolved with low latency
- Distributed File System(ex. Hadoop, HDFS..)을 이용하여 Master Dataset을 저장한다. 이때 Master Dataset이란, timestamp와 함께 fact기반의 raw데이터들(fact-based model) 전부 모아둔 데이터 집합이다. 이때 데이터는 immutable하고 eternally true하다. Distributed File System은 더 많은 데이터를 저장할 수 있게 하고, fault tolerance에 강하다.
- Vertical Partitioning을 통해 관련된 데이터만 접근하게 함으로써, Computation을 줄여줄 수 있다.
- MapReduce 방식을 통한 배치성 데이터 처리를 한다.
- batch layer는 master dataset을 precompute하여 batch views를 만듬으로써, low latency로 query할 수 있게 해준다.
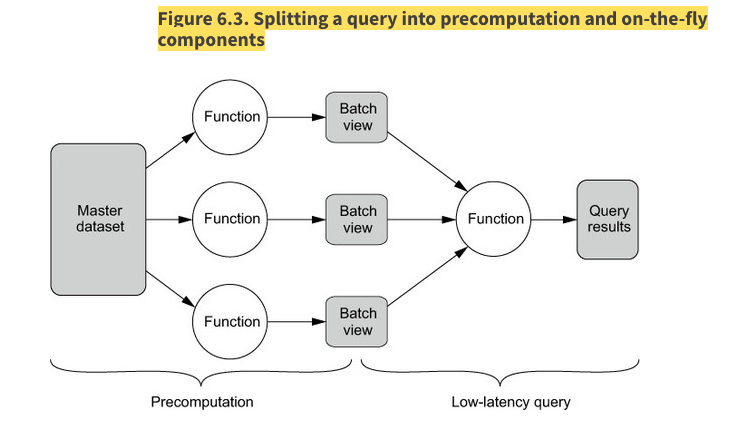
- recomputation algorithm vs incremental algorithm
recomputation algorithm: batch view가 오래되면, master dataset 통째로 처음부터 다시 계산하여 batch view를 만드는 알고리즘.
incremental algorithm: batch view가 오래되면, 새로 들어온 데이터에 대해서만 다시 계산하여 batch view들을 만들어 주는 알고리즘.
얼핏 보면, 계산량이 적은 incremental algorithm이 좋아보이지만, 오히려 더 많은 정보가 있어야 새로운 batch view를 만들 수가 있어서, batch view의 데이터를 키워버리는 단점이 발생할 수있다.
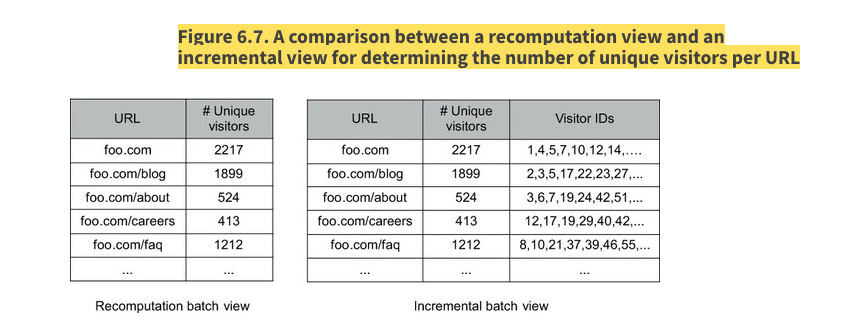
- incremental batch view의 경우 unique visitor를 계산하기 위해서는 visitors id들 또한, batch view에 들고 있어야 계산이 가능함. 이로 인해 batch view 사이즈가 매우 커지는 문제가 발생함.
- 이외에도 normalization을 한 경우, 다시 renormalization을 해야하는 상황이 발생하면, 전체를 처음부터 계산하는 recompuation algorithm전략이 더 나을 수 있다.
2. Serving Layer
- The serving layer indexes the views and provides interfaces so that the precomputed data can be quickly queried.
- The ability to tailor views to optimize latency and throughput
- The simplicity from not supporting random writes
- The capacity to store normalized data in the batch layer and denormalized data in the serving layer
- The inherent error-tolerance and correction of the serving layer, because it can be recomputed from the master dataset
3. Speed Layer
- the speed layer is significantly more complex than the batch layer because updates are incremental
- the speed layer requires random reads and writes in the data while the batch layer only needs batch reads and writes
- the speed layer is only responsible for data that is not yet included in the serving layer, therefore the amount of data to be handled is vastly smaller
- the speed layer views are transient, and any errors are short-lived
1) Queuing and stream processing
문제: queues - wokers 방식의 한계
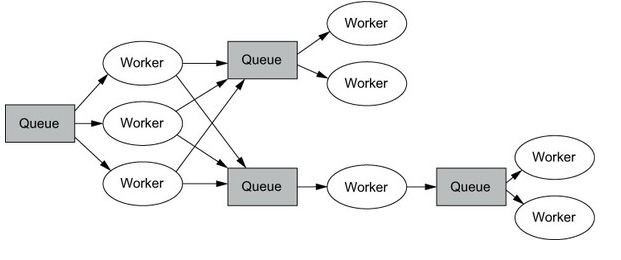
- 1) race condition의 가능성
- 2) poor fault tolerance: 어떤 일을 담당하던 worker가 죽어버리면, 그 담당하던 일에 문제가 생김
- 3) Another problem is that having queues between every set of workers adds to the operational burden on your system.
- 4) each intermediate queue needs to be managed and monitored and adds yet another layer that needs to be scaled. (제일 큰 문제)
해결책: one-at-a time streaming 방식
-
Apache Storm을 예로 들고 있음.
-
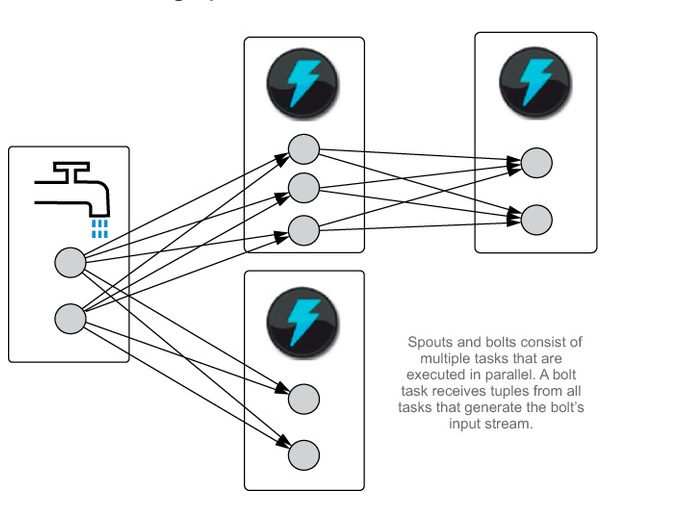
Apache Storm의 간단한 동작원리
-
One of the beauties of the Storm model is that it can be implemented without any intermediate queues. It turns out you can maintain that at-least-once guarantee without intermediate queues. Of course, it has to work differently—instead of retries happening wherever the failure occurred, retries happen from the root of the topology.
when a task emits a tuple, which of the consuming tasks should receive it?
The Storm model requires stream groupings to specify how tuples should be partitioned among consuming tasks. The simplest kind of stream grouping is a shuffle grouping that distributes tuples using a random round-robin algorithm. This grouping evenly splits the processing load by distributing the tuples randomly but equally to all consumers. Another common grouping is the fields grouping that distributes tuples by hashing a subset of the tuple fields and modding the result by the number of consuming tasks.
2) Micro-batch stream processing
-
one-at-a time streaming 방식의 경우, low latency를 가지고 있지만, But it can only provide an at-least-once processing guarantee during failures. Although this doesn’t affect accuracy for certain operations, like adding elements to a set, it does affect accuracy for other operations such as counting. 즉, 정확성이 중요한 경우는 보류해야함.
-
반면, Micro-batch stream processing 방식의 경우, 좀더 높은 latency를 가졌지만, full accuracy를 원할 때 사용할 수 있다. The key idea is rather than just store a count(계산할려는 값), you store the count along with the ID of the latest tuple processed
- one-at-a time streaming 방식의 경우 : Failures are tracked at an individual tuple level, and replays also happen at an individual tuple level.
반면, Micro-batch stream processing 방식의 경우: Small batches of tuples are processed at one time, and if anything in a batch fails, the entire batch is replayed.- Micro-batch stream processing 방식의 경우: Strongly ordered processing을 추구한다. 즉, you don’t move on to the next tuple until the current one is successfully processed.
- Micro-batch stream processing 방식의 경우: can have higher throughput than one-at-a-time processing. Whereas one-at-a time streaming 방식의 경우 : must do tracking on an individual tuple level, micro-batch processing only has to track at a batch level.
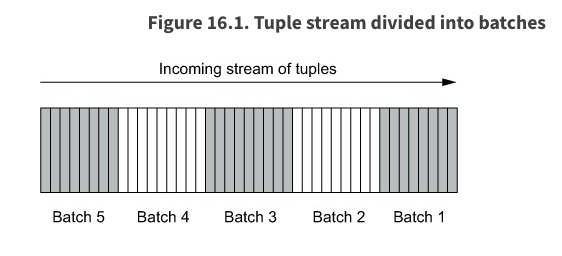
- The batches are processed in order
- each batch has a unique ID
- Batches must be processed to completion before moving on to the next batch.
- Batch-local computation: There’s computation that occurs solely within the batch, not dependent on any state being kept
- Stateful computation: The trick of storing the batch ID with the state is particularly useful here to add idempotence to non-idempotent operations.
- micro-batch stream processing relies on a stream source that can replay a batch exactly as it was played before.
🏝이 글이 도움이 되셨다면 추천 클릭을 부탁드립니다 :)
참고 자료
