[머신러닝을 위한 파이썬 한 조각] - CH.11 CNN
CH.11 CNN
- CNN 아키텍처
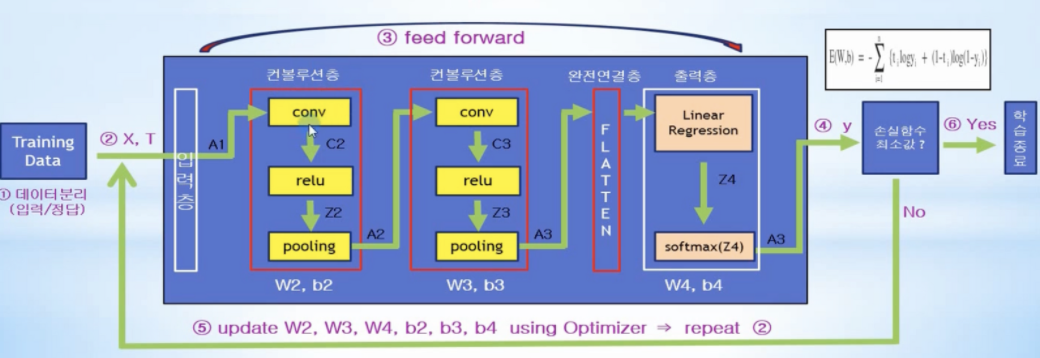
- 기존 Neural Network의 은닉층 부분이 여러개의 컨볼루션층과 완전연결층으로 구성됨
- 완전연결층: 컨볼루션층의 3차원 출력값을 1차원 벡터로 평탄화하여 일반 신경망 연결처럼 출력층의 모든 노드와 연결시켜주는 역할 수행, tf.reshape(A4, …)
- 출력층: 입력받은 값을 출력으로 0~1사이의 값으로 모두 정규화하며 출력값들의 총합은 항상 1이 되도록 하는 역할 수행, tf.nn.softmax(Z5)
- 컨볼루션층
- conv
- 입력으로 주어지는 데이터의 특징을 추출함
- 입력데이터와 가중치들의 집합체인 필터와의 컨볼루션 연산을 수행

- pooling
- 입력 정보를 최대값, 최소값, 평균값 등으로 압축하여 데이터 연산량을 줄여주는 역할
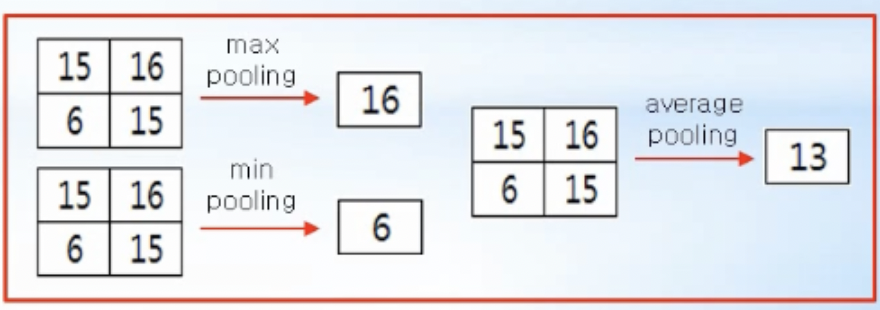
- convolution 연산 - 특징을 추출하는 feature map을 만들어냄
- 필터를 일정간격(stride)으로 이동해 가면서 입력데이터와 필터에서 대응하는 원소끼리 곱한 후 그 값들을 모두 더해주는 연산

- padding
- 컨볼루션 연산을 수행하기 전 입력데이터 주변을 특정값(ex.0)으로 채우는 것
- 컨볼루션 연산을 수행하면 데이터 크기(shape)이 줄어드는 단점을 방지하기 위해 사용
- 출력데이터 크기(shape) 공식
- 입력 데이터 크기( H, W), 필터크기 (FH, FW), 패딩 P, 스트라이드 S일 때 출력데이터 크기(OH, OW)

- 특징 추출 과정
- 입력데이터 1개 (숫자 2)에 필터 3개(가로, 대각선, 세로 필터) 적용
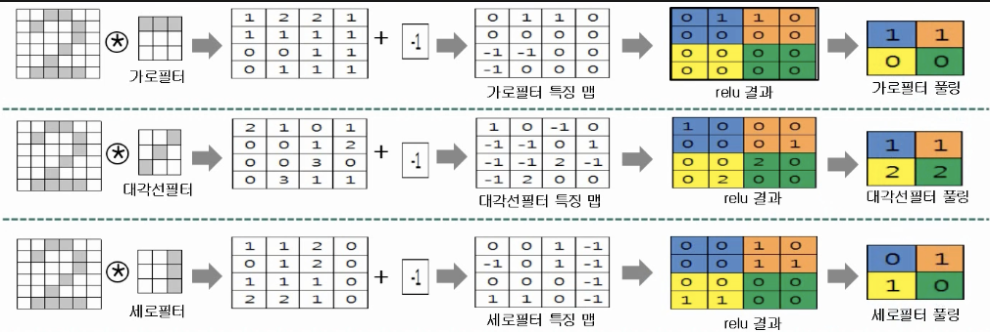
- 컨볼루션 연산 결과인 특징맵(feature map)값을 압축하고 있는 풀링값을 보면, 대각선 필터에 대한 풀링값이 가로, 세로필터의 풀링값보다 큰 값으로 구성되어 있는데, 풀링 값이 크다는 것은 데이터 안에 해당 필터의 특징(성분)이 많이 포함되어 있는 것을 의미함
- 특징맵 값이 압축되어 있는 풀링 결과값을 통해 데이터의 특징(성분) 추출 가능
- 숫자 2에 대해 대각선 특징이 가로, 세로 특징보다 많이 포함되어 있으며 특징 추출에 대각선 필터가 더 유용하다는 것을 알 수 있음
- convolution 연산 수행 - tf.nn.conv2d(input, filter, strides, padding, …)
- input
- 컨볼루션 연산을 위한 입력 데이터
- [batch, in_height, in_width, in_channels]
- 100개의 배치로 묶은 28x28크기의 이미지 → [100, 28, 28, 1]
- filter
- 컨볼루션 연산에 적용할 필터
- [filter_height, filter_width, in_channels, out_channels]
- 필터 크기 3x3, 입력채널 개수 1개, 적용되는 필터 개수 32 → [3, 3, 1, 32]
- strides: 컨볼루션 연산을 위해 필터를 이동시키는 간격
- [1, 1, 1 , 1] → 컨볼루션 적용을 위해 1칸씩 이동 필터를 이동
- padding:
- ‘SAME’ 또는 ‘VALID’ 값을 가짐
- padding = ‘VALID’라면 가로 / 세로 크기가 축소된 결과가 리턴, padding = ‘SAME이면, 입력값의 가로/세로 크기와 같은 출력이 리턴되도록 작아진 차원 부분에 0값을 채운 제로패딩 수행
- max pooling - tf.nn.max_pool(value, ksize, strides, padding, …)
- value
- relu를 통과한 출력 결과
- [batch, height, width, channels]
- ksize
- [1, height, width, 1]
- ksize = [1,2,2,1] → 2칸씩 이동하면서 출력결과 1개를 만들어내는것, 2x2데이터 중에서 가장 큰 값 1개를 찾아서 반환하는 역할 수행
- ksize = [1,3,3,1] → 3칸씩 이동, 3x3데이터 중 가장 큰 값을 찾는것
- strides
- max pooling을 위해 윈도우를 이동시키는 간격
- [1,2,2,1] → 2칸씩 이동
- padding
- max pooling을 수행하기에는 데이터가 부족한 경우에 주변을 0등으로 채워주는 역할
- 풀링층으로 들어오는 입력데이터가 7x7이고, 데이터를 2개씩 묶어 최대값을 찾아내는 연산을 하기에는 데이터가 부족한 상황 (8x8이어야 가능), padding = ‘SAME’을 통해 부족한 데이터 부분을 0등으로 채워 데이터를 2개씩 묶어 최대값 뽑아낼 수 있음
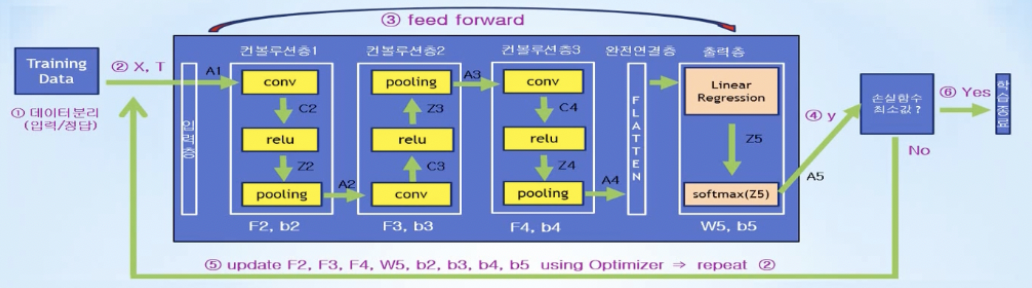
- CNN 노드, 연산 정의
- 데이터 분리 (입력/정답)

- read_data_sets()을 통해 객체형태인 mnist로 받아오고 입력데이터와 정답데이터는 MNIST_data/ 디렉토리에 저장되는데, one_hot=True 옵션을 통해 정답데이터는 one-hot encoding 형태로 저장됨
- mnist 객체는 train, test, validation 3개의 데이터 셋으로 구성됨
- 데이터는 784(28x28)개의 픽셀을 가지는 이미지와 one-hot encoding되어있는 label(정답)을 가짐
- 하이퍼 파라미터 설정, 입력과 정답을 위한 placeholder 노드(X, T) 정의

- learning rate, epochs, batch_size 등의 하이퍼 파라미터 설정
- 입력층의 출력값 A1은 픽셀값을 가진 데이터 이지만 컨볼루션 연산을 수행하기 위해 28x28x1 차원을 가지도록 reshpae함
- 컨볼루션층 1,2,3, 완전연결층, 출력층
- 손실함수계산, 5. optimizer를 통해 f, w, b 업데이트

- 출력층 선형회귀값(logits) Z5와 정답 T를 이용하여 손실함수 loss 정의
- tf.nn.softmax_cross_entropy_with_logits_v2(…)에 의해 100개의 데이터에 대해 각각의 softmax가 계산된 후 정답과의 비교를 통해 크로스 엔트로피 손실함수 값이 계산되고, tf.reduce_mean(…)에 의해 100개의 손실함수 값의 평균이 계산됨
- 학습종료
- one-hot encoding에 의해 출력층 계산값 A5와 정답 T는 (batch_size x 10) shpae을 가지는 행렬
- argmax의 두번째 인자에 1을 주어 행단위로 비교함
![]()
