CH.7 딥러닝 (Deep Learning)
-
뉴런은 이전 뉴런으로부터 입력신호를 받아 또 다른 신호를 발생시킴
-
입력에 비례해서 출력을 내는 형태 (y=WX)가 아니라, 입력 값들의 모든 합이 어느 임계점(threshold)에 도달해야만 출력 신호를 발생시킴
-
입력신호를 받아 특정 값의 임계점을 넘어서는 경우에 출력을 생성해주는 함수를 활성화 함수(activation function)이라고 함 ex) sigmoid, ReLU, tanh
-
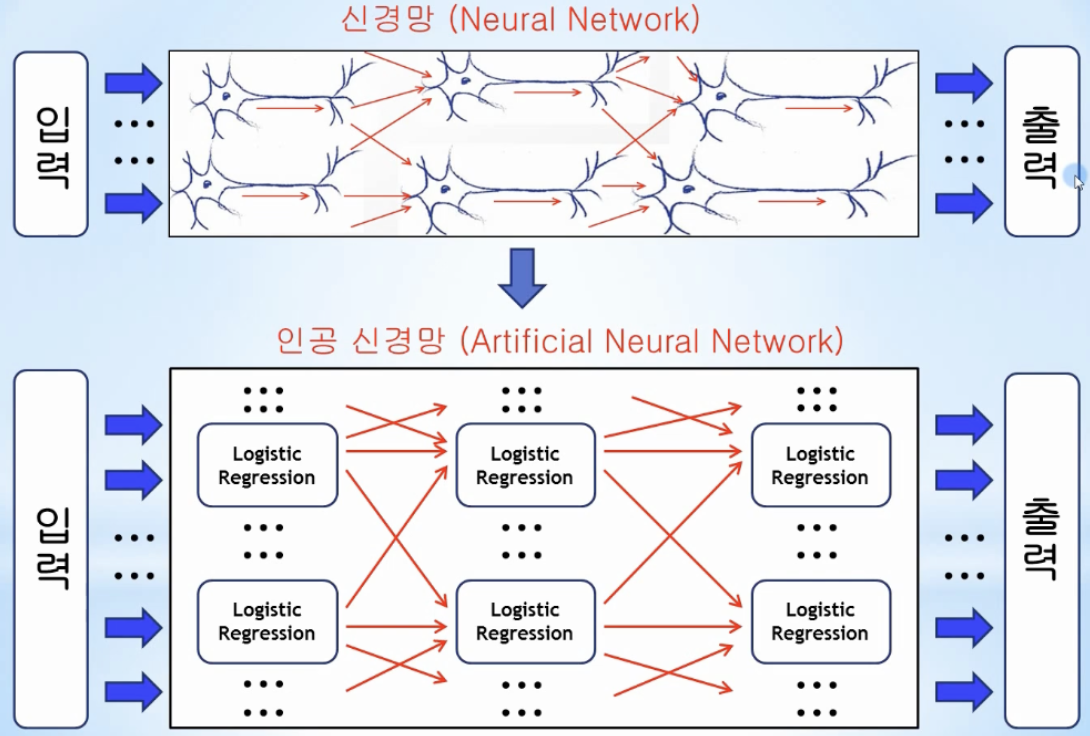
신경세포인 뉴런 동작원리를 머신러닝에 적용하여 multi-variable Logistic Regression 시스템 구축
→ 1) 입력 신호와 가중치를 곱하고 적당한 바이어스를 더한 후(Linear Regression)
→ 2) 그 값을 활성화 함수 입력으로 전달(Classification)해서 sigmoid 함수 임계점 0.5를 넘으면 1을, 그렇지 않으면 0을 다음의 뉴런으로 전달
-
딥러닝
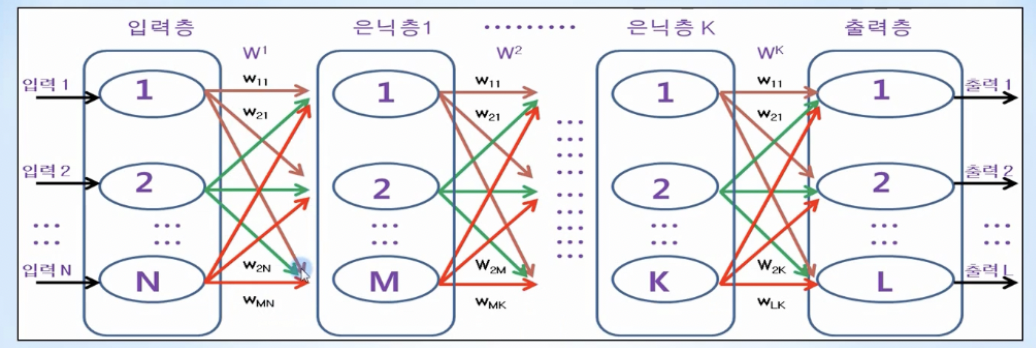
- 노드: 1개의 logistic regression을 나타냄, 타원형
- 노드가 서로 연결되어 있는 신경망 구조를 바탕으로 입력층(Input Layer), 1개 이상의 은닉층(Hidden Layer), 출력층(Output Layer)을 구축하고, 출력층에서의 오차를 기반으로 각 노드(뉴런)의 가중치(Weight)를 학습하는 머신러닝의 한 분야
- Hidden Layer를 깊게할수록 정확도가 높아진다 해서 딥러닝이라 불림
- 가중치 w21 → 특정 계층의 노드1에서 다음 계층의 노드2로 전달되는 신호를 강화 또는 약화시키는 가중치 (즉, 다음계층의 노드 번호가 먼저 나옴)
- 층과 층 사이의 모든 노드에 초기화 되어있으며, 데이터가 입력층에서 출력층으로 전파(propagation)될 때, 각 층에 있는 노드의 모든 가중치는 신호를 약화시키거나 강화시키며, 최종적으로 오차가 최소값이 될 때 최적의 값을 가지게 됨
-
feed forward
- 입력층으로 데이터가 입력되고, 1개 이상으로 구성되는 은닉층을 거쳐 마지막에 있는 출력층으로 출력 값을 내보내는 과정
- 딥러닝에서는 이전 층에서 나온 출력값 → 층과 층 사이에 적용되는 가중치 영향을 받은 다음 → 다음 층의 입력 값으로 들어가는 것을 의미함
- 표기법
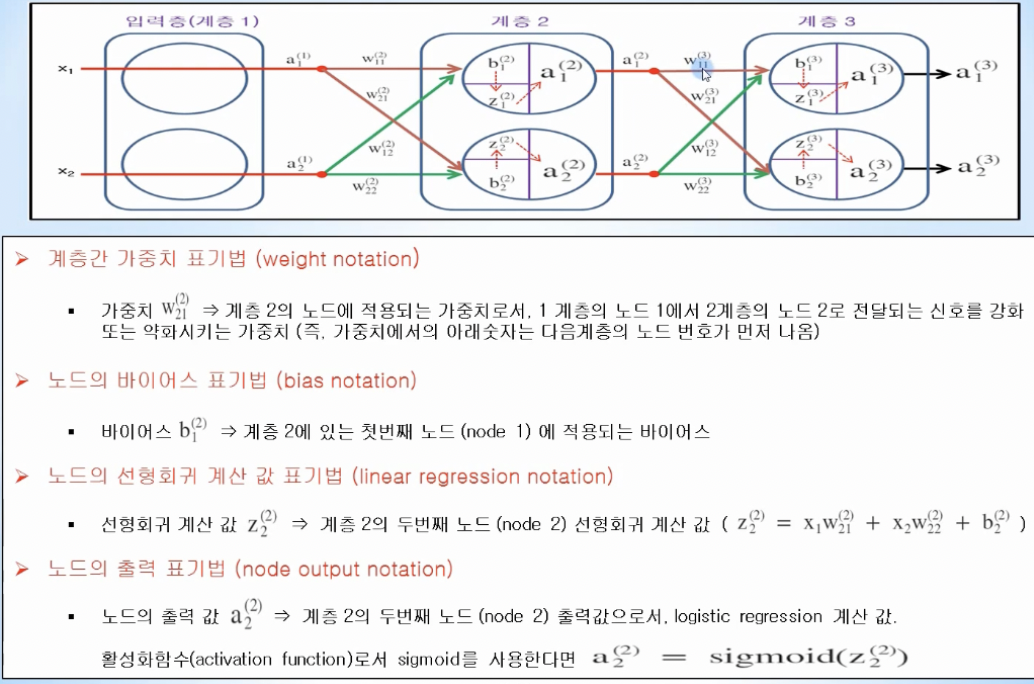
- 동작방식
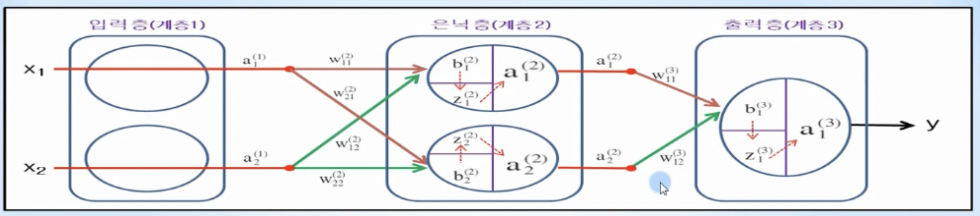
- 입력층 출력

- 딥러닝 입력층에서는 활성화 함수인 sigmoid를 적용하지 않고, 입력 값 그대로 출력으로 내보냄
- 은닉층 선형회귀 값 및 출력

- 출력층 선형회귀 값 및 출력

- 딥러닝에서는 출력층에서의 출력값 y(a1)와 정답 t와의 차이를 이용하여 오차가 최소가 되도록 각 층에 있는 가중치와 바이어스를 최적화해야 함
- 입력층 출력
-
딥러닝에서는 1개 이상의 은닉층을 만들 수 있고, 각 은닉층에 존재하는 노드 수 또한 임의로 만들 수 있음, 그러나 은닉층과 노드 수가 많아지면 학습 속도가 느려지므로 적절하게 설정해야 함
-
딥러닝으로 XOR 문제 풀기
-
전체 구조

-
코드 구현
import numpy as np def sigmoid(z): return 1 / (1+np.exp(-z)) def derivative(f,x): delta_x = 1e-4 grad = np.zeros_like(x) it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) while not it.finished: idx = it.multi_index tmp_val = x[idx] x[idx] = float(tmp_val) + delta_x fx1 = f(x) x[idx] = tmp_val - delta_x fx2 = f(x) grad[idx] = (fx1 - fx2) / (2*delta_x) x[idx] = tmp_val it.iternext() return grad class LogicGate: def __init__(self, gate_name, xdata, tdata): self.name = gate_name self.xdata = xdata.reshape(4,2) self.tdata = tdata.reshape(4,1) self.W2 = np.random.rand(2,6) self.b2 = np.random.rand(6) self.W3 = np.random.rand(6,1) self.b3 = np.random.rand(1) self.learning_rate = 1e-2 def feed_forward(self): delta = 1e-7 z2 = np.dot(self.xdata, self.W2) + self.b2 a2 = sigmoid(z2) z3 = np.dot(a2, self.W3) + self.b3 y = a3 = sigmoid(z3) return -np.sum(self.tdata*np.log(y+delta)+(1-self.tdata)*np.log((1-y)+delta)) def loss_val(self): delta = 1e-7 z2 = np.dot(self.xdata, self.W2) + self.b2 a2 = sigmoid(z2) z3 = np.dot(a2, self.W3) + self.b3 y = a3 = sigmoid(z3) return -np.sum(self.tdata*np.log(y+delta)+(1-self.tdata)*np.log((1-y)+delta)) def train(self): f = lambda x: self.feed_forward() print("Initial loss value = ", self.loss_val()) for step in range(20001): self.W2 -= self.learning_rate * derivative(f, self.W2) self.b2 -= self.learning_rate * derivative(f, self.b2) self.W3 -= self.learning_rate * derivative(f, self.W3) self.b3 -= self.learning_rate * derivative(f, self.b3) if (step % 1000 == 0): print("step = ", step, "loss value =", self.loss_val()) def predict(self, xdata): z2 = np.dot(xdata, self.W2) + self.b2 a2 = sigmoid(z2) z3 = np.dot(a2, self.W3) + self.b3 y = a3 = sigmoid(z3) if y > 0.5: result = 1 else: result = 0 return y, resultxdata = np.array([ [0,0],[0,1],[1,0],[1,1] ]) tdata = np.array([0,1,1,0]) xor_obj = LogicGate("XOR", xdata, tdata) xor_obj.train()test_data = np.array([ [0,0],[0,1],[1,0],[1,1] ]) for data in test_data: (sigmoid_val, logical_val) = xor_obj.predict(data) print(data,"",logical_val)
-
