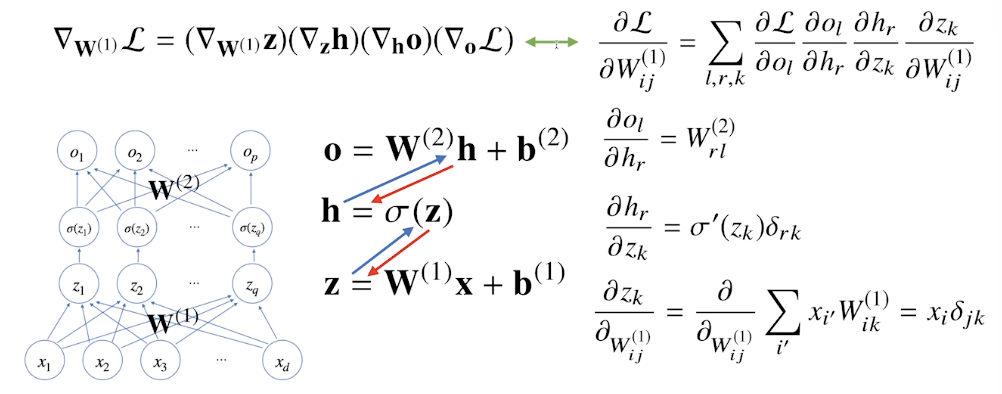부스트코스 강의 인공지능(AI) 기초 다지기 중 '딥러닝 학습방법 이해하기'를 정리한 내용이다.
-
비선형모델인 신경망(neural network)
- 출력 벡터의 차원이 원래 데이터들이 모여있는 d차원에서 출력벡터의 p차원으로 변함
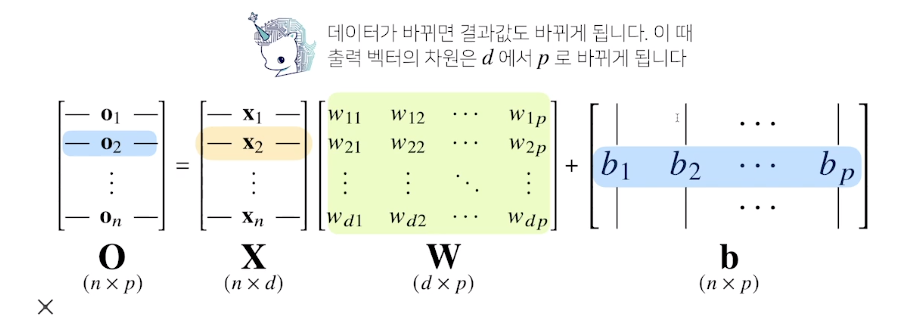
- d개의 변수로 p개의 선형모델을 만들어서 p개의 잠재변수를 설명함
- 출력 벡터의 차원이 원래 데이터들이 모여있는 d차원에서 출력벡터의 p차원으로 변함
-
Softmax 연산
-
softmax 함수는 모델의 출력을 확률로 해석할 수 있게 변환해주는 연산
-
분류 문제를 풀 때 선형모델과 softmax 함수를 결합하여 예측함

-
추론을 할때는 one-hot 벡터로 최대값을 가진 주소만 1로 출력하는 연산을 사용하고 softmax는 사용하지 않음
-
-
신경망은 선형모델과 activation function(활성함수)을 합성한 함수
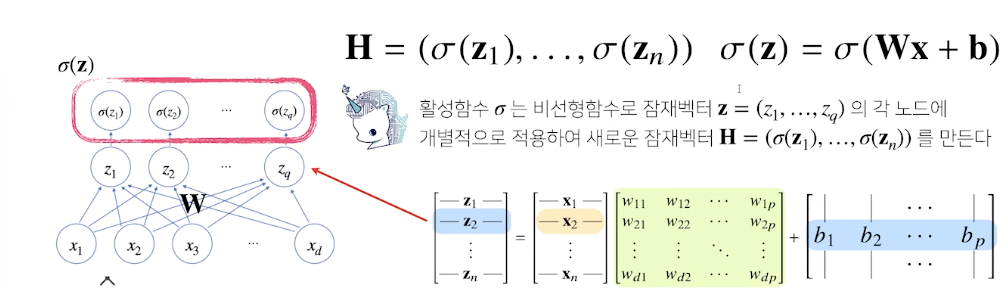
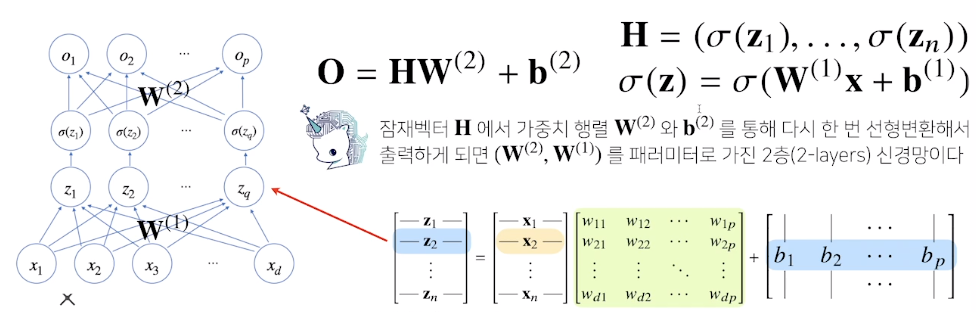
- 다층(multi-layer) perceptron(MLP)은 신경망이 여러층 합성된 함수
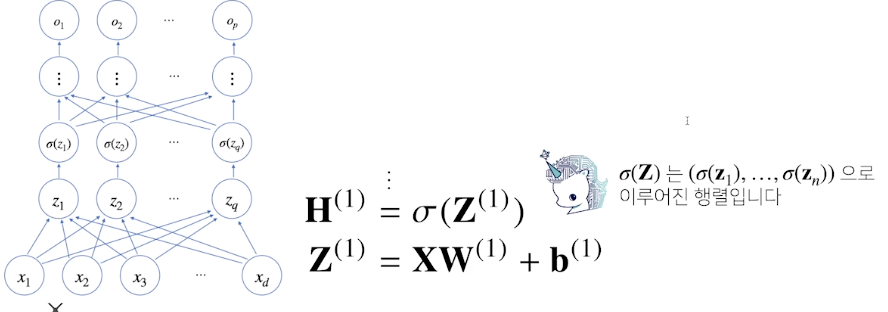
- forward propagtion(순전파): 순차적인 신경망 계산, 학습이 아니라 주어진 입력이 왔을 때 출력물을 내뱉는 과정을 표현하는 연산

- 다층(multi-layer) perceptron(MLP)은 신경망이 여러층 합성된 함수
-
activation function
- R위에 정의된 비선형(lonlinear) 함수로서 딥러닝에서 중요한 개념
- 활성함수를 쓰지 않으면 딥러닝은 선형모양과 차이가 없음
- 전통적으로 sigmoid 함수, tanh 함수가 많이 쓰였지만 딥러닝에서는 ReLU함수를 많이 씀

-
층을 쌓는 이유: 층이 깊을수록 목적함수를 근사하는데 필요한 뉴런(노드)의 숫자가 훨씬 빨리 줄어 효율적으로 학습이 가능하기에 층을 여러개 쌓음
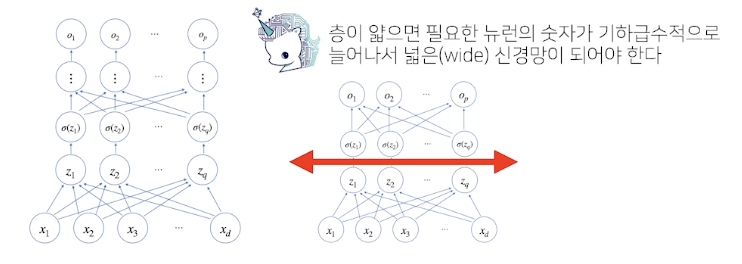
- 반면, 최적화는 층이 깊어질수록 어려움
-
딥러닝은 역전파(backpropagation) 알고리즘을 이용하여 각 층에 사용된 파라미터를 학습함

- 경사하강법을 적용해 각각의 가중치 행렬을 학습시킬 때, 각각의 가중치에 대한 gradient를 계산해야 함
-
각 층 paraemter의 gradient vector는 윗층부터 역순으로 계산하게 됨 - 연쇄법칙을 통해 gradient vector 전달
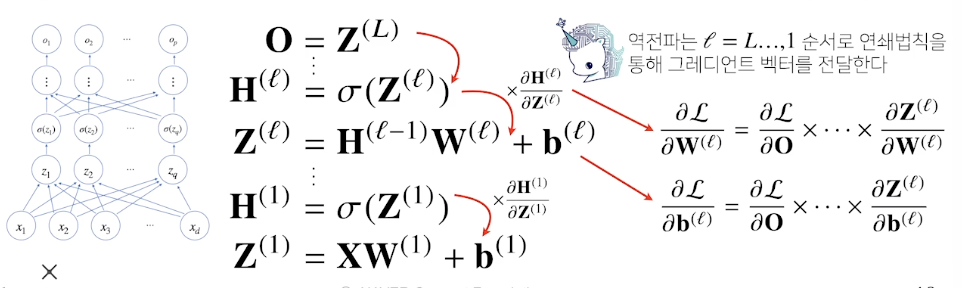
-
역전파 알고리즘은 합성함수 미분법인 연쇄법칙(chain-rule)기반 자동미분(auto-diffentiation)을 사용함

-
2층 신경망의 역전파 알고리즘